LLM介绍
ChatGPT 的巨大成功激发了越来越多的开发者兴趣,他们希望利用 OpenAI 提供的 API 或者私有化模型,来开发基于大型语言模型的应用程序。尽管大型语言模型的调用相对简单,但要创建完整的应用程序,仍然需要大量的定制开发工作,包括 API 集成、互动逻辑、数据存储等等。为了解决这个问题,从 2
AI Agent在11个领域100个应用场景
人工智能代理(AI Agent)的发展正在以前所未有的速度改变我们的生活和工作方式。从日常生活的小事到企业级的复杂决策,AI Agent 的应用场景广泛且多样。以下是11个领域中 100 个 AI Agent 的创新应用场景,它们展示了 AI 技术如何渗透到我们生活的方方面面。
人工智能、机器学习、神经网络、深度学习和卷积神经网络的概念和关系
深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的有效表示,而这种使用相对较短、稠密的向量表示叫做分布式特征表示(也可以称为嵌入式表示)。研究深度学习的动机在于建立模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本等。又称为机器智能,是研究、开发
机器学习课程设计,人工智能课程设计,深度学习课程设计--基于Transformer的家庭暴力情绪检测系统(欢迎私)
家庭暴力在现今社会屡见不鲜,成为威胁社会和谐与稳定的重要问题之一。家庭暴力不仅包括身体上的虐待,还涉及情感、心理和经济上的虐待,给受害者尤其是女性和儿童带来深远的负面影响。有效预防和处理家庭暴力事件,及时感知和理解伴侣的情感显得尤为重要。为了帮助社会稳定,提高居民生活幸福指数,本系统选取了CMU-M
【机器学习】Datawhale-AI夏令营分子性质AI预测挑战赛
一、赛事背景在当今科技日新月异的时代,人工智能(AI)技术正以前所未有的深度和广度渗透到科研领域,特别是在化学及药物研发中展现出了巨大潜力。精准预测分子性质有助于高效筛选出具有优异性能的候选药物。以PROTACs为例,它是一种三元复合物由目标蛋白配体、linker、E3连接酶配体组成,靶向降解目标蛋
减轻幻觉新SOTA,7B模型自迭代训练效果超越GPT-4,上海AI lab发布
本文通过迭代自我训练,逐步扩大数据集的多样性和规模,并提高幻觉标注器的准确性。最终得到的ANAH-v2仅用7B参数在各种幻觉检测基准测试中首次超过了GPT-4,并在第三方幻觉检测基准测试中表现出色。ANAH-v2不仅提供了一个基于的扩展数据集的自动幻觉评估基准,为未来幻觉缓解研究铺平了道路,还通过简
cube studio开源一站式机器学习平台:k3s部署cube-studio
开源地址:https://github.com/tencentmusic/cube-studiocube studio 腾讯开源的国内最热门的一站式机器学习mlops/大模型训练平台,支持多租户,sso单点登录,支持在线镜像调试,在线ide开发,数据集管理,图文音标注和自动化标注,任务模板自定义,拖
用AI勘探地质:全波形反演技术 (FWI) 原理与AI方法的应用
该问题是典型的涉及偏微分方程求解的反问题,当前业界常用的方法是利用有限差分、有限元法求解声波、弹性波方程,利用伴随方法进行反演,最终得到代表地下地质分布的速度模型。此外,基于梯度的优化方法可能陷入局部最优解,因此对速度模型的初始估计需要较为准确,具体地,初始速度模型所对应的地震波场与实际地震波场的误
MLlib机器学习入门:用Spark打造预测模型
Apache Spark 已然成为大数据处理领域的一颗璀璨明星。它以其卓越的性能、易用性以及丰富的生态系统,吸引了无数开发者投身于大数据的浪潮之中。如果你正是一名向往大数据领域的开发者,或是已经涉足其中但希望更深入地掌握Spark技术,那么请跟随这篇指南,我们将以一种“糙快猛”的策略,高效开启你的大
人工智能在数字病理切片虚拟染色以及染色标准化领域的研究进展|顶刊速递·24-06-23
这篇文章介绍了一种用于数字病理学的端到端平台,该平台利用高光谱自荧光显微镜和基于深度学习的虚拟组织学染色技术。研究团队开发了一种定制的高光谱显微镜,用于无损成像未染色组织切片的自荧光。然后,他们训练了一个深度学习模型,使用自荧光生成虚拟的组织学染色,避免了化学染色过程的成本和变异性,并保留了组织样本
【机器学习】独立成分分析(ICA):解锁信号的隐秘面纱
在当今数据驱动的世界中,信号处理和数据分析面临着前所未有的挑战。特别是在处理混合信号时,如何从复杂的混合体中分离出纯净的源信号,成为了研究的热点。独立成分分析(Independent Component Analysis,ICA)作为一种先进的信号处理技术,以其独特的理论基础和广泛的适用性,逐渐成为
SpringBoot中优化if-else语句的七种方法实战
通过策略模式、枚举与策略模式结合、状态模式, 多态性、Lambda表达式与函数接口、命令模式以及保护子句等策略,我们可以有效地减少Spring Boot项目中`if-else`语句的使用,提升代码的可读性、可维护性和模块化水平。每种策略都有其适用的场景,合理选择和组合这些策略,可以帮助我们编写出更简
【深度学习】图形模型基础(2):概率机器学习模型与人工智能
概率建模在机器学习中至关重要,它利用概率分布表达不确定性,通过贝叶斯学习从数据中学习。非参数方法、概率编程、贝叶斯优化和数据压缩等技术展示了概率建模的灵活性和效率。自动建模系统能够发现并解释数据模型。随着大数据的增长,不确定性建模依然关键。概率建模将在未来机器学习和人工智能系统中发挥核心作用,为自动
Logit 模型及 Stata 操作步骤
Logit 模型及 Stata 操作步骤
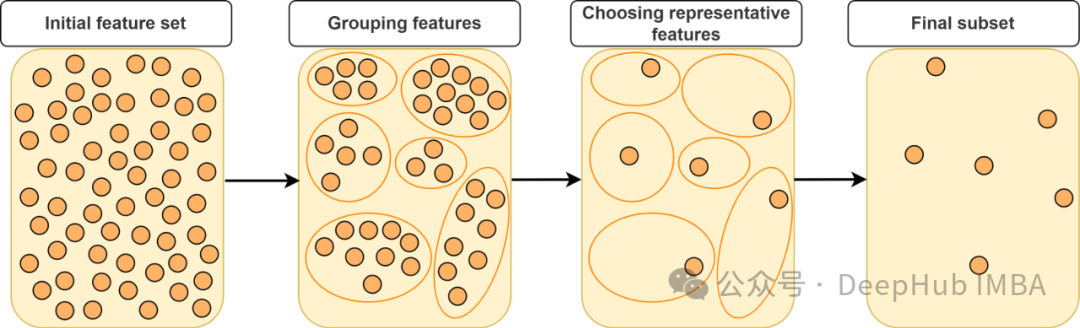
精简模型,提升效能:线性回归中的特征选择技巧
在本文中,我们将探讨各种特征选择方法和技术,用以在保持模型评分可接受的情况下减少特征数量。通过减少噪声和冗余信息,模型可以更快地处理,并减少复杂性。
【人工智能】Transformers之Pipeline(五):深度估计(depth-estimation)
本文对transformers之pipeline的深度估计(depth-estimation)从概述、技术原理、pipeline参数、pipeline实战、模型排名等方面进行介绍,读者可以基于pipeline使用文中的代码极简的使用计算机视觉中的深度估计(depth-estimation)模型,应用
人工智能与伦理挑战:多维度应对策略
人工智能技术近年来取得了迅猛发展,广泛应用于医疗诊断、金融分析、教育辅助、自动驾驶等各个领域,极大地提升了生产效率和服务质量,推动了科技进步和商业创新。然而,伴随其普及和应用的泛滥,AI也带来了数据隐私侵犯、信息茧房、算法歧视、虚假信息传播等诸多问题,导致社会信任危机和伦理道德挑战凸显。这种技术的双
【人工智能高频面试题--基础篇】
人工智能面试题,他来了!
【Datawhale AI夏令营】|从零入门机器学习竞赛笔记
是一款基于决策树算法的分布式梯度提升框架,旨在提供快速高效、低内存占用、高准确率的模型训练工具。它通过多种优化手段,解决了传统GBDT在面对海量数据时遇到的效率和内存瓶颈问题,使其更适用于工业级应用。



