
数据集地址:Market Basket Analysis | Kaggle
我的NoteBook地址:pyspark Market Basket Analysis | Kaggle
零售商期望能够利用过去的零售数据在自己的行业中进行探索,并为客户提供有关商品集的建议,这样就能提高客户参与度、改善客户体验并识别客户行为。本文将通过pyspark对数据进行导入与预处理,进行可视化分析并使用spark自带的机器学习库做关联规则学习,挖掘不同商品之间是否存在关联关系。
整体的流程思路借鉴了这个Notebook:Market Basket Analysis with Apriori🛒 | Kaggle
一、导入与数据预处理
这一部分其实没有赘述的必要,贴在这里单纯是为了熟悉pyspark的各个算子。
from pyspark import SparkContext
from pyspark.sql import functions as F, SparkSession, Column,types
import pandas as pd
import numpy as np
spark = SparkSession.builder.appName("MarketBasketAnalysis").getOrCreate()
data = spark.read.csv("/kaggle/input/market-basket-analysis/Assignment-1_Data.csv",header=True,sep=";")
data = data.withColumn("Price",F.regexp_replace("Price",",",""))
data = data.withColumn("Price",F.col("Price").cast("float"))
data = data.withColumn("Quantity",F.col("Quantity").cast("int"))
预处理时间类变量
#时间变量
data = data.withColumn("Date_Day",F.split("Date"," ",0)[0])
data = data.withColumn("Date_Time",F.split("Date"," ",0)[1])
data = data.withColumn("Hour",F.split("Date_Time",":")[0])
data = data.withColumn("Minute",F.split("Date_Time",":")[1])
data = data.withColumn("Year",F.split("Date_Day","\.")[2])
data = data.withColumn("Month",F.split("Date_Day","\.")[1])
data = data.withColumn("Day",F.split("Date_Day","\.")[0])
convert_to_Date = F.udf(lambda x:"-".join(x.split(".")[::-1])+" ",types.StringType())
data = data.withColumn("Date",F.concat(convert_to_Date(data["Date_Day"]),data["Date_Time"]))
data = data.withColumn("Date",data["Date"].cast(types.TimestampType()))
data = data.withColumn("DayOfWeek",F.dayofweek(data["Date"])-1) #dayofweek这个函数中,以周日为第一天
data = data.withColumn("DayOfWeek",F.udf(lambda x:x if x!=0 else 7,types.IntegerType())(data["DayOfWeek"]))
删除负值的记录、填充缺失值并删除那些非商品的记录
# 删除price/QTY<=0的情况
data = data.filter((F.col("Price")>0) & (F.col("Quantity")>0))
# 增加Total Price
data = data.withColumn("Total Price",F.col("Price")*F.col("Quantity"))
data_null_agg = data.agg(
*[F.count(F.when(F.isnull(c), c)).alias(c) for c in data.columns])
data_null_agg.show()
# CustomerID 空值填充
data = data.fillna("99999","CustomerID")
# 删除非商品的那些Item
data = data.filter((F.col("Itemname")!='POSTAGE') & (F.col("Itemname")!='DOTCOM POSTAGE') & (F.col("Itemname")!='Adjust bad debt') & (F.col("Itemname")!='Manual'))
二、探索性分析
1、总体销售情况
本节开始,将会从订单量(No_Of_Trans)、成交量(Quantity)与成交额(Total Price)三个维度,分别从多个角度进行数据可视化与分析。
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
from collections import Counter
## 总体分析
data_ttl_trans = data.groupby(["BillNo"]).sum("Quantity","Total Price").withColumnRenamed("sum(Quantity)","Quantity").withColumnRenamed("sum(Total Price)","Total Price").toPandas()
data_ttl_item = data.groupby(["Itemname"]).sum("Quantity","Total Price").withColumnRenamed("sum(Quantity)","Quantity").withColumnRenamed("sum(Total Price)","Total Price").toPandas()
data_ttl_time = data.groupby(["Year","Month"]).sum("Quantity","Total Price").withColumnRenamed("sum(Quantity)","Quantity").withColumnRenamed("sum(Total Price)","Total Price").toPandas()
data_ttl_weekday = data.groupby(["DayOfWeek"]).sum("Quantity","Total Price").withColumnRenamed("sum(Quantity)","Quantity").withColumnRenamed("sum(Total Price)","Total Price").toPandas()
data_ttl_country = data.groupby(["Country"]).sum("Quantity","Total Price").withColumnRenamed("sum(Quantity)","Quantity").withColumnRenamed("sum(Total Price)","Total Price").toPandas()
data_ttl_country_time = data.groupby(["Country","Year","Month"]).sum("Quantity","Total Price").withColumnRenamed("sum(Quantity)","Quantity").withColumnRenamed("sum(Total Price)","Total Price").toPandas()
sns.boxplot(data_ttl_trans["Quantity"])
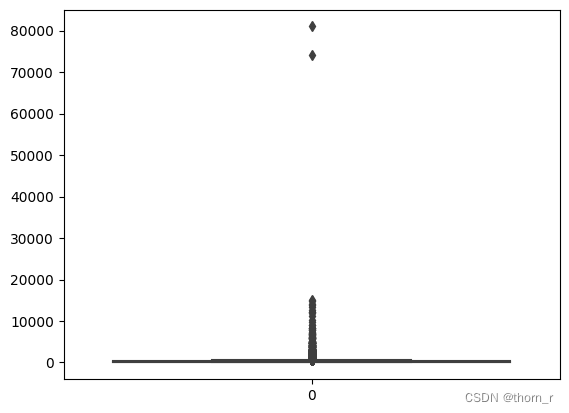
sns.boxplot(data_ttl_trans["Total Price"])
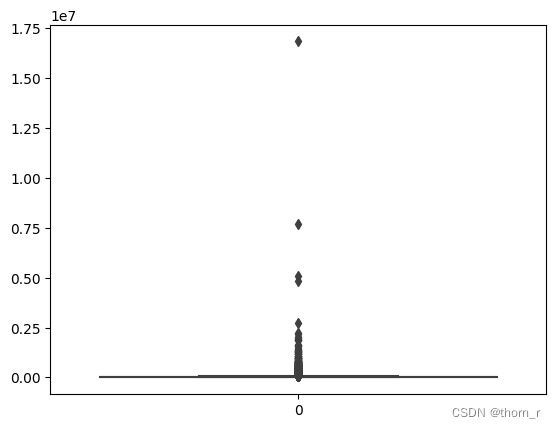
如上两图所示,销售数据极不平衡,有些单子里的销售额或销售量远远超过正常标准,因此在作分布图时,我会将箱线图中的离群点去除。
print("Quantity upper",np.percentile(data_ttl_trans["Quantity"],75)*2.5-np.percentile(data_ttl_trans["Quantity"],25)) #箱线图顶点
print("Total Price upper",np.percentile(data_ttl_trans["Total Price"],75)*2.5-np.percentile(data_ttl_trans["Total Price"],25)) #箱线图顶点
sns.distplot(data_ttl_trans[data_ttl_trans["Quantity"]<=661]["Quantity"])
sns.distplot(data_ttl_trans[data_ttl_trans["Total Price"]<=97779]["Total Price"])
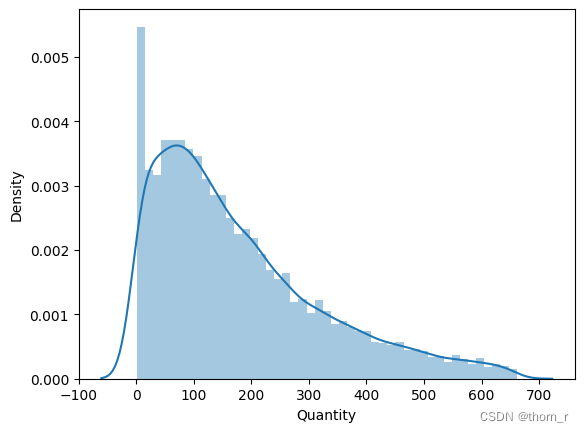
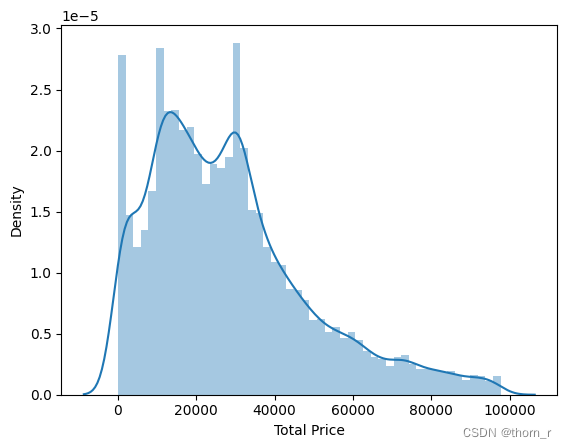
可以看出,哪怕去除了离群点,从分布图上分布看依旧明显右偏趋势,表明了有极少数的订单拥有极大的销售量与销售额,远超正常订单的水平。
sns.boxplot(data_ttl_item["Quantity"])
print("Quantity upper",np.percentile(data_ttl_item["Quantity"],75)*2.5-np.percentile(data_ttl_item["Quantity"],25)) #箱线图顶点
#Quantity upper 3279.75
sns.distplot(data_ttl_item[data_ttl_item["Quantity"]<=2379]["Quantity"])

以商品为单位的销量分布也同样右偏,表明了同样有极少数的商品拥有极大的销售量,远超一般商品的水平。
接下来我们看看时间维度上的销量变化
data_ttl_time.index = [str(i)+"\n"+str(j) for i,j in zip(data_ttl_time["Year"],data_ttl_time["Month"])]
fig,ax1 = plt.subplots()
ax1.plot(data_ttl_time["Quantity"],color='gray',label="Quantity")
ax2 = ax1.twinx()
ax2.plot(data_ttl_time["Total Price"],color="red",label="Total Price")
ax1.set_ylabel("Quantity",color="gray")
ax2.set_ylabel("Total Price",color="red")
plt.show()

plt.bar(data_ttl_weekday["DayOfWeek"],data_ttl_weekday["Total Price"],color='red',width=0.5,label="Quantity")
plt.show() #周六不卖
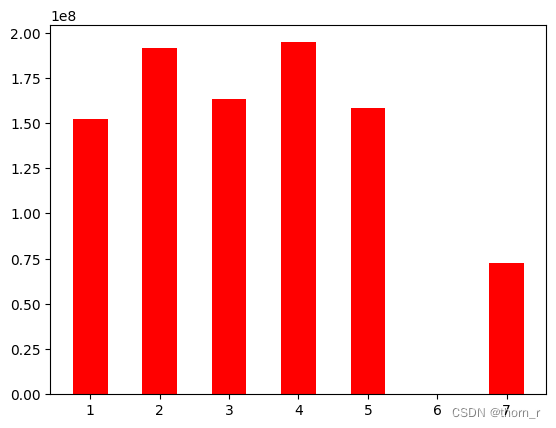
从时间轴上来看,销售额有一个明显的上升趋势,到了11月有一个明显的高峰,而到12月则有所回滚。
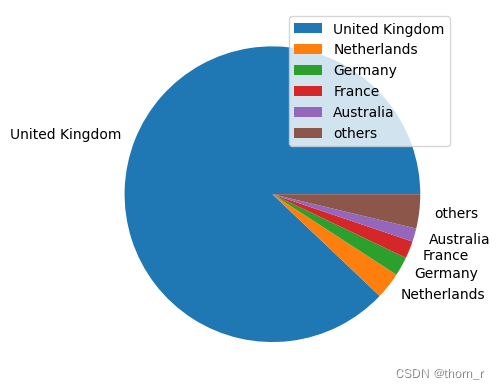
data_ttl_country.index = data_ttl_country["Country"]
ttl_price_country = data_ttl_country["Total Price"].sort_values()[::-1]
tmp = ttl_price_country[5:]
ttl_price_country = ttl_price_country[0:5]
ttl_price_country["others"] = sum(tmp)
plt.pie(ttl_price_country,labels=ttl_price_country.index)
plt.legend(loc="upper right")
plt.show()
data_ttl_country_time["isUnitedKingdom"]=["UK" if i=="United Kingdom" else "Not UK" for i in data_ttl_country_time["Country"]]
data_ttl_country_time_isUK = data_ttl_country_time.groupby(["isUnitedKingdom","Year","Month"])["Total Price"].sum().reset_index()
data_ttl_country_time_isUK.index = data_ttl_country_time_isUK["Year"]+"\n"+data_ttl_country_time_isUK["Month"]
UK = data_ttl_country_time_isUK[data_ttl_country_time_isUK["isUnitedKingdom"]=="UK"]
NUK = data_ttl_country_time_isUK[data_ttl_country_time_isUK["isUnitedKingdom"]=="Not UK"]
plt.figure(figsize=(8,8))
plt.bar(UK.index,UK["Total Price"],color="#66c2a5",label="United Kingdom")
plt.bar(NUK.index,NUK["Total Price"],bottom=UK["Total Price"],color="#8da0cb",label="other Country")
plt.legend()
plt.show()

总体上来看,总销售额的绝大部分都是来自于英国销售,而从时间线商来看,每个月都是英国销售额占主体。因此,后文的分析将看2011年英国的全年销售。
## 只选取UK2011年的全年数据
df_UK = data.filter((F.col("Country")=="United Kingdom") & (F.col("Year")==2011))
2、是否存在季节性商品
首先,我们将2011年的4个季度的销售额、销售量以及成交量分别汇总并排序,看看有没有哪个商品在各个季度的排名有明显的差距。
def transform_to_Season(x):
if len(x)>1 and x[0]=="0":
x = x[1:]
return int((int(x)-1)//3)+1
df_UK = df_UK.withColumn("Season",F.udf(transform_to_Season,types.IntegerType())(F.col("Month")))
df_UK_seasonal = df_UK.groupby(["Season","Itemname"]).agg(F.countDistinct(F.col("BillNo")).alias("No_Of_Trans"),F.sum(F.col("Quantity")).alias("Quantity")
,F.sum(F.col("Total Price")).alias("Total Price")).toPandas()
# 排序
def rank_seasonal(df,season="all"):
groupby_cols = ["Itemname"]
if season!="all":
groupby_cols.append("Season")
df = df[df["Season"]==int(season)]
df = df.groupby(groupby_cols).sum(["No_Of_Trans","Quantity","Total Price"])
for col in ["No_Of_Trans","Quantity","Total Price"]:
df[col+"_Rank"]=df[col].rank(ascending=False)
return df
df_UK_all = rank_seasonal(df_UK_seasonal)
df_UK_first = rank_seasonal(df_UK_seasonal,"1")
df_UK_second = rank_seasonal(df_UK_seasonal,"2")
df_UK_third = rank_seasonal(df_UK_seasonal,"3")
df_UK_fourth = rank_seasonal(df_UK_seasonal,"4")
## Top 10 Rank:
dfs = [df_UK_all,df_UK_first,df_UK_second,df_UK_third,df_UK_fourth]
item_set_No_Of_Trans=set()
item_set_Quantity=set()
item_set_Total_Price = set()
for df in dfs:
df = df.copy().reset_index()
itemname_top_Trans = df[df["No_Of_Trans_Rank"]<=10]["Itemname"]
itemname_top_Qty = df[df["Quantity_Rank"]<=10]["Itemname"]
itemname_top_TTL_PRICE = df[df["Total Price_Rank"]<=10]["Itemname"]
for i in itemname_top_Trans:
item_set_No_Of_Trans.add(i)
for i in itemname_top_Qty:
item_set_Quantity.add(i)
for i in itemname_top_TTL_PRICE:
item_set_Total_Price.add(i)
## 每个季度的是否有所不同?
RANK_DF = {"Dimension":[],"item":[],"Rank":[],"Value":[],"Season":[],"Range":[]}#pd.DataFrame(columns=["Dimension","item","Rank","Value"])
for dim,itemset in [("No_Of_Trans",item_set_No_Of_Trans),("Quantity",item_set_Quantity),("Total Price",item_set_Total_Price)]:
for i in list(itemset):
min_rank=9999
max_rank=-1
for j,df in enumerate(dfs):
df = df.reset_index()
if j == 0:
RANK_DF["Season"].append("all")
else:
RANK_DF["Season"].append(df["Season"].values[0])
sub_df = df[df["Itemname"]==i]
if sub_df.shape[0]==0:
curr_rank=9999
curr_value=0
else:
curr_rank = df[df["Itemname"]==i][dim+"_Rank"].values[0]
curr_value = df[df["Itemname"]==i][dim].values[0]
min_rank = min(curr_rank,min_rank)
max_rank = max(curr_rank,max_rank) if curr_rank<9999 else max_rank
RANK_DF["Dimension"].append(dim)
RANK_DF["item"].append(i)
RANK_DF["Rank"].append(curr_rank)
RANK_DF["Value"].append(curr_value)
RANK_DF["Range"] += [max_rank-min_rank]*5
RANK_DF = pd.DataFrame(RANK_DF)
plt.figure(figsize=(20,20))
# “每个季度的量相差很多”的,但是本身很多的
dims = ["No_Of_Trans","Quantity","Total Price"]
for i,dim in enumerate(dims):
tmp_df = RANK_DF[(RANK_DF["Dimension"]==dim) & (RANK_DF["Season"]!='all')]
tmp_df["Range_Rank"] = tmp_df["Range"].rank(ascending=False)
tmp_df = tmp_df.sort_values("Range_Rank").reset_index(drop=True)
for j in range(3):
tmp_df_rank = tmp_df.loc[4*j:4*(j+1)-1,:]
this_item = list(set(tmp_df_rank["item"]))[0]
plt.subplot(3,3,i*3+j+1)
plt.pie(tmp_df_rank["Value"],labels=tmp_df_rank["Season"])
plt.title(f"{dim}:{this_item}")
plt.show()
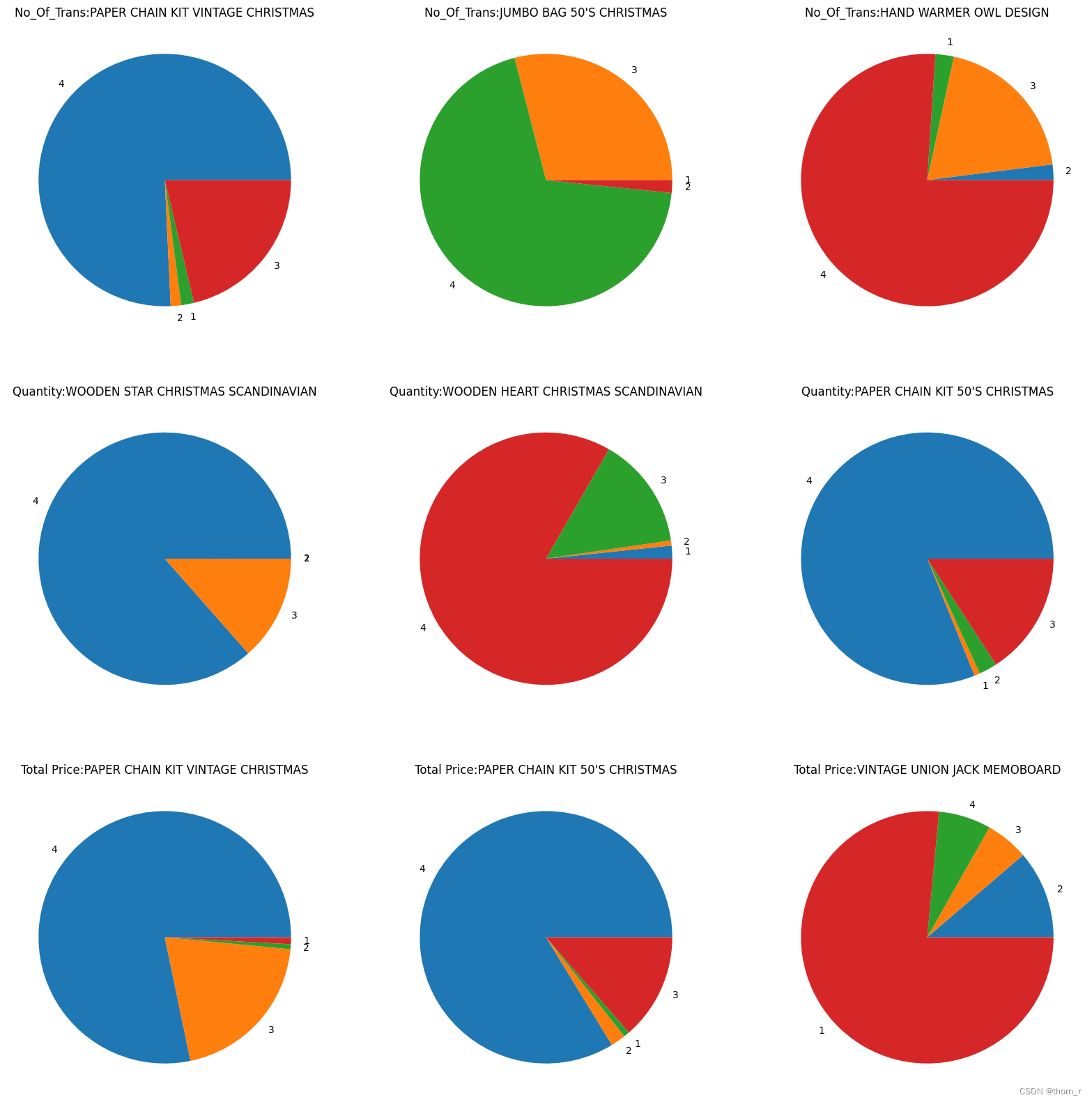
上图中的商品,是在全年的销售中名销售额/销售了/成交量列前茅的几个商品,但是从饼图上来看,这下商品明显是会集中在某一个季度中畅销。我们把颗粒度缩小到按月份来看,计算每月销售额占总销售额的比重(季节指数);并以此排序看看哪些商品的季节指数极差最大。
df_UK_monthly = df_UK.groupby(["Month","Itemname"]).agg(F.countDistinct(F.col("BillNo")).alias("No_Of_Trans"),F.sum(F.col("Quantity")).alias("Quantity")
,F.sum(F.col("Total Price")).alias("Total Price")).toPandas().reset_index(drop=True)
df_UK_fullyear = df_UK_monthly.groupby(["Itemname"]).mean(["No_Of_Trans","Quantity","Total Price"]).reset_index()
df_UK_fullyear.rename(columns={"No_Of_Trans":"FY_No_Of_Trans","Quantity":"FY_Quantity","Total Price":"FY_Total Price"},inplace=True)
df_UK_Monthly_season = pd.merge(df_UK_monthly,df_UK_fullyear,on=["Itemname"],how='left')
df_UK_Monthly_season["seasonal_index_No_Of_Trans"]=df_UK_Monthly_season["No_Of_Trans"]/df_UK_Monthly_season["FY_No_Of_Trans"]
df_UK_Monthly_season["seasonal_index_Quantity"]=df_UK_Monthly_season["Quantity"]/df_UK_Monthly_season["FY_Quantity"]
df_UK_Monthly_season["seasonal_index_Total Price"]=df_UK_Monthly_season["Total Price"]/df_UK_Monthly_season["FY_Total Price"]
#算极差
df_UK_season_max = df_UK_Monthly_season.groupby("Itemname").max(["seasonal_index_No_Of_Trans","seasonal_index_Quantity","seasonal_index_Total Price"]).reset_index().rename(columns={"seasonal_index_No_Of_Trans":"seasonal_index_No_Of_Trans_max","seasonal_index_Quantity":"seasonal_index_Quantity_max","seasonal_index_Total Price":"seasonal_index_Total Price_max"})
df_UK_season_min = df_UK_Monthly_season.groupby("Itemname").min(["seasonal_index_No_Of_Trans","seasonal_index_Quantity","seasonal_index_Total Price"]).reset_index().rename(columns={"seasonal_index_No_Of_Trans":"seasonal_index_No_Of_Trans_min","seasonal_index_Quantity":"seasonal_index_Quantity_min","seasonal_index_Total Price":"seasonal_index_Total Price_min"})
df_UK_season_ranges = pd.merge(df_UK_season_min,df_UK_season_max,on=["Itemname"])
seasonal_index_cols = ["seasonal_index_No_Of_Trans","seasonal_index_Quantity","seasonal_index_Total Price"]
for col in seasonal_index_cols:
df_UK_season_ranges[col] = df_UK_season_ranges[col+"_max"]-df_UK_season_ranges[col+"_min"]
df_UK_season_ranges[col+"_Rank"]=df_UK_season_ranges[col].rank(ascending=False)
df_UK_season_ranges = df_UK_season_ranges[["Itemname"]+[i for i in df_UK_season_ranges if "seasonal_index" in i]]
plt.figure(figsize=(15,15))
for i,col in enumerate(["seasonal_index_No_Of_Trans","seasonal_index_Quantity","seasonal_index_Total Price"]):
seasonal_items = df_UK_season_ranges.sort_values(col+"_Rank").reset_index().loc[:2,"Itemname"].tolist()
for j,item in enumerate(seasonal_items):
plt.subplot(3,3,i*3+j+1)
idxs = [k for k in df_UK_monthly.index if df_UK_monthly.loc[k,"Itemname"]==item]
tmp_df = df_UK_monthly.loc[idxs,["Itemname","Month",col.replace("seasonal_index_","")]]
tmp_df = tmp_df.pivot(index="Month",columns="Itemname",values=col.replace("seasonal_index_",""))
plt.plot(tmp_df, marker='o')
plt.ylabel(col.replace("seasonal_index_",""))
plt.title(item)
plt.show()
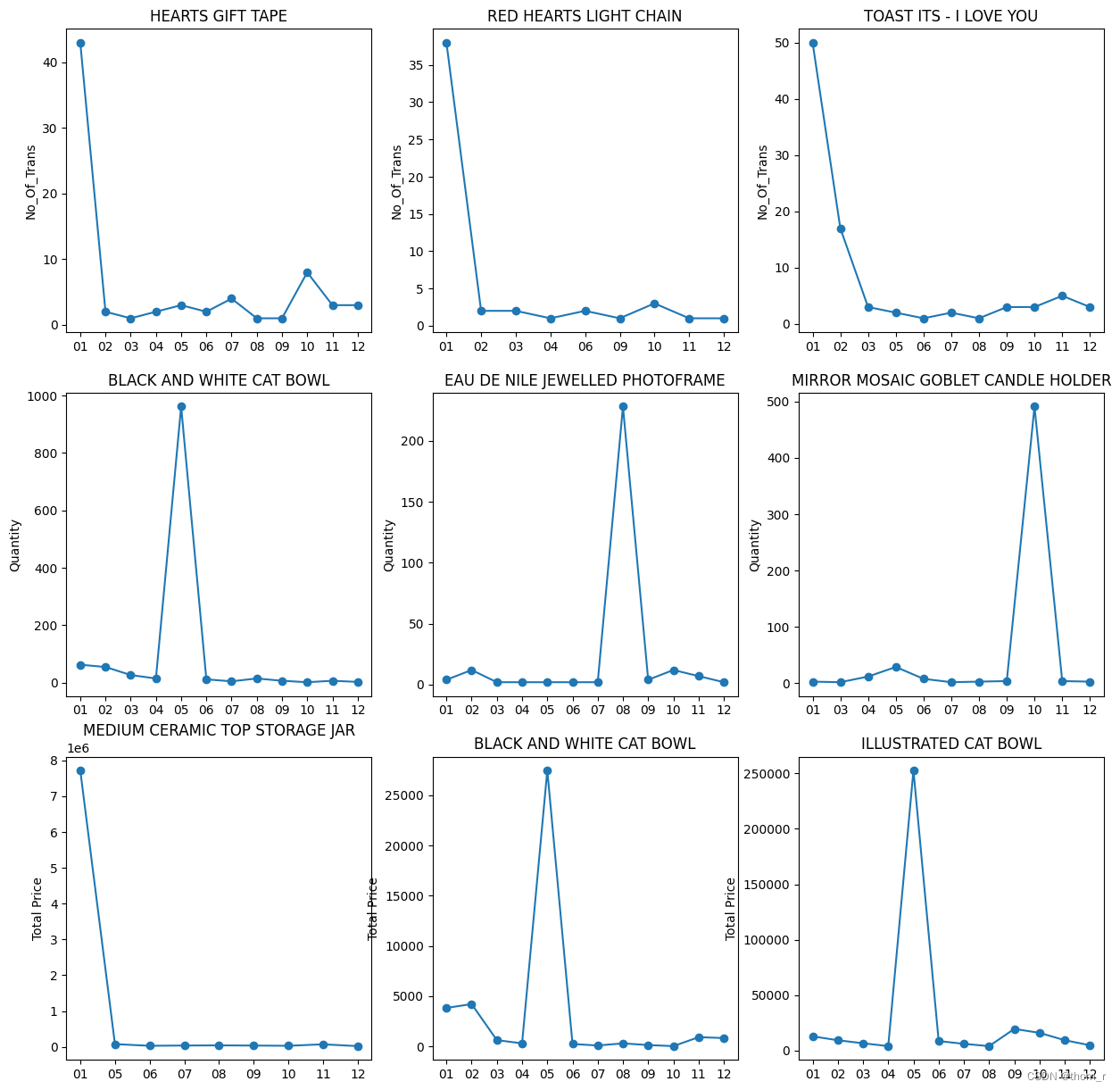
此处分别从销售额/销售量/成交量3个维度构造了季节指数,并将极差排名前3的商品作了折线统计图。从途中来看,这些商品全都是“集中在某一个月份十分畅销,但是在其他月份相对无人问津”。
ranges = RANK_DF.groupby(["Dimension","item"]).first(["Range"]).reset_index()[["Dimension","item","Range"]]
## No_Of_Trans
plt.figure(figsize=(20,20))
range_df = ranges[ranges["Dimension"]=="No_Of_Trans"]
titles = ["All","Season One","Season Two","Season Three","Season Four"]
for n in range(5):
plt.subplot(5,1,n+1)
df = dfs[n].copy().reset_index()
df = df.loc[[i for i in df.index if df.loc[i,"Itemname"] in item_set_No_Of_Trans],["Itemname","No_Of_Trans"]]
df=df.sort_values("No_Of_Trans",ascending=False)
df = df.iloc[:10,:]
df = pd.merge(df,range_df,left_on="Itemname",right_on="item",how="left")
plt.barh(df["Itemname"]+" "+df["Range"].astype("str"),df["No_Of_Trans"])
plt.title("No_Of_Trans "+titles[n])
plt.show()
plt.figure(figsize=(20,20))
range_df = ranges[ranges["Dimension"]=="Quantity"]
titles = ["All","Season One","Season Two","Season Three","Season Four"]
for n in range(5):
plt.subplot(5,1,n+1)
df = dfs[n].copy().reset_index()
df = df.loc[[i for i in df.index if df.loc[i,"Itemname"] in item_set_Quantity],["Itemname","Quantity"]]
df=df.sort_values("Quantity",ascending=False)
df = df.iloc[:10,:]
df = pd.merge(df,range_df,left_on="Itemname",right_on="item",how="left")
plt.barh(df["Itemname"]+" "+df["Range"].astype("str"),df["Quantity"])
plt.title("Quantity "+titles[n])
plt.show()
plt.figure(figsize=(20,20))
range_df = ranges[ranges["Dimension"]=="Total Price"]
titles = ["All","Season One","Season Two","Season Three","Season Four"]
for n in range(5):
plt.subplot(5,1,n+1)
df = dfs[n].copy().reset_index()
df = df.loc[[i for i in df.index if df.loc[i,"Itemname"] in item_set_Total_Price],["Itemname","Total Price"]]
df=df.sort_values("Total Price",ascending=False)
df = df.iloc[:10,:]
df = pd.merge(df,range_df,left_on="Itemname",right_on="item",how="left")
plt.barh(df["Itemname"]+" "+df["Range"].astype("str"),df["Total Price"])
plt.title("Total Price "+titles[n])
plt.show()
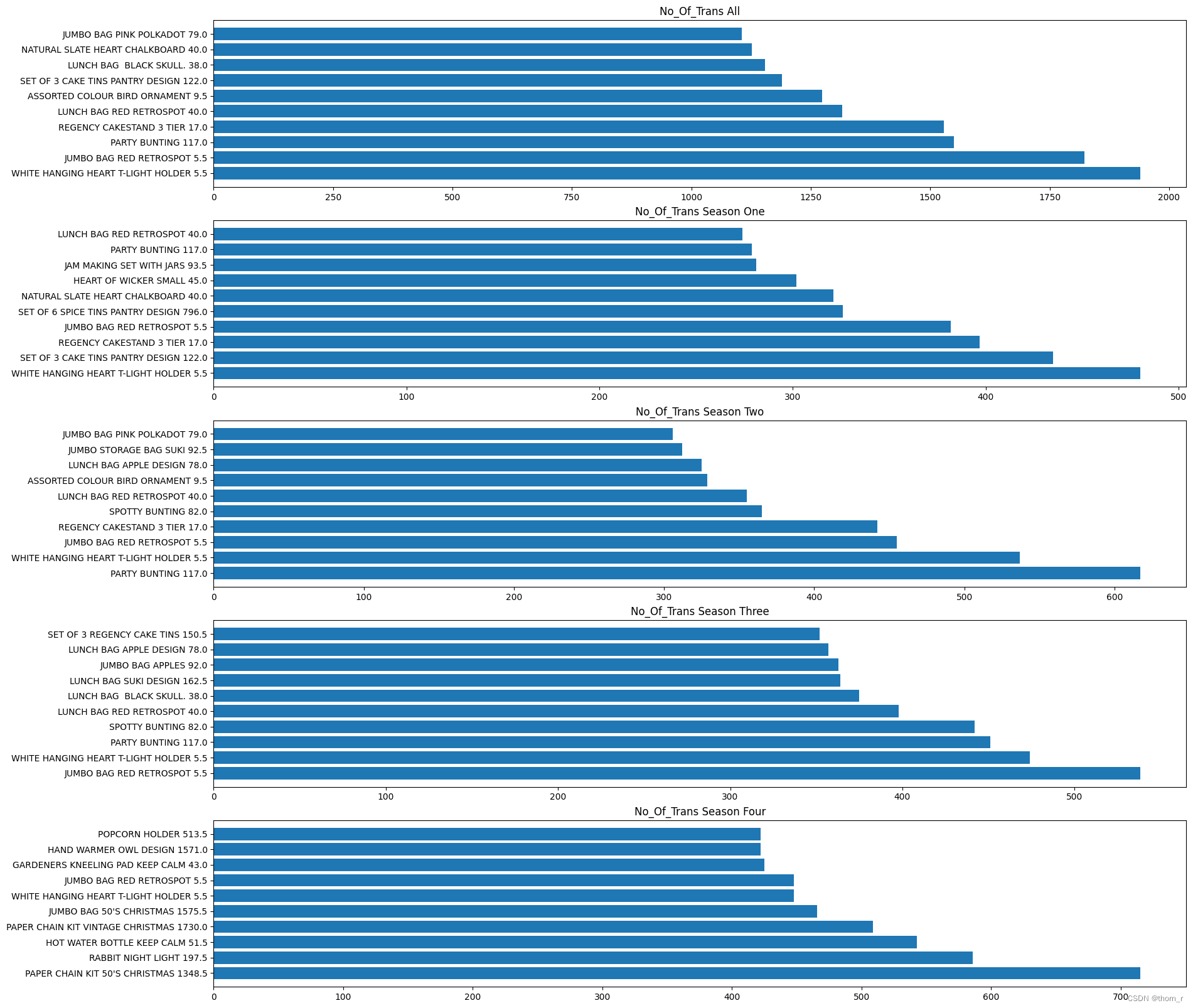
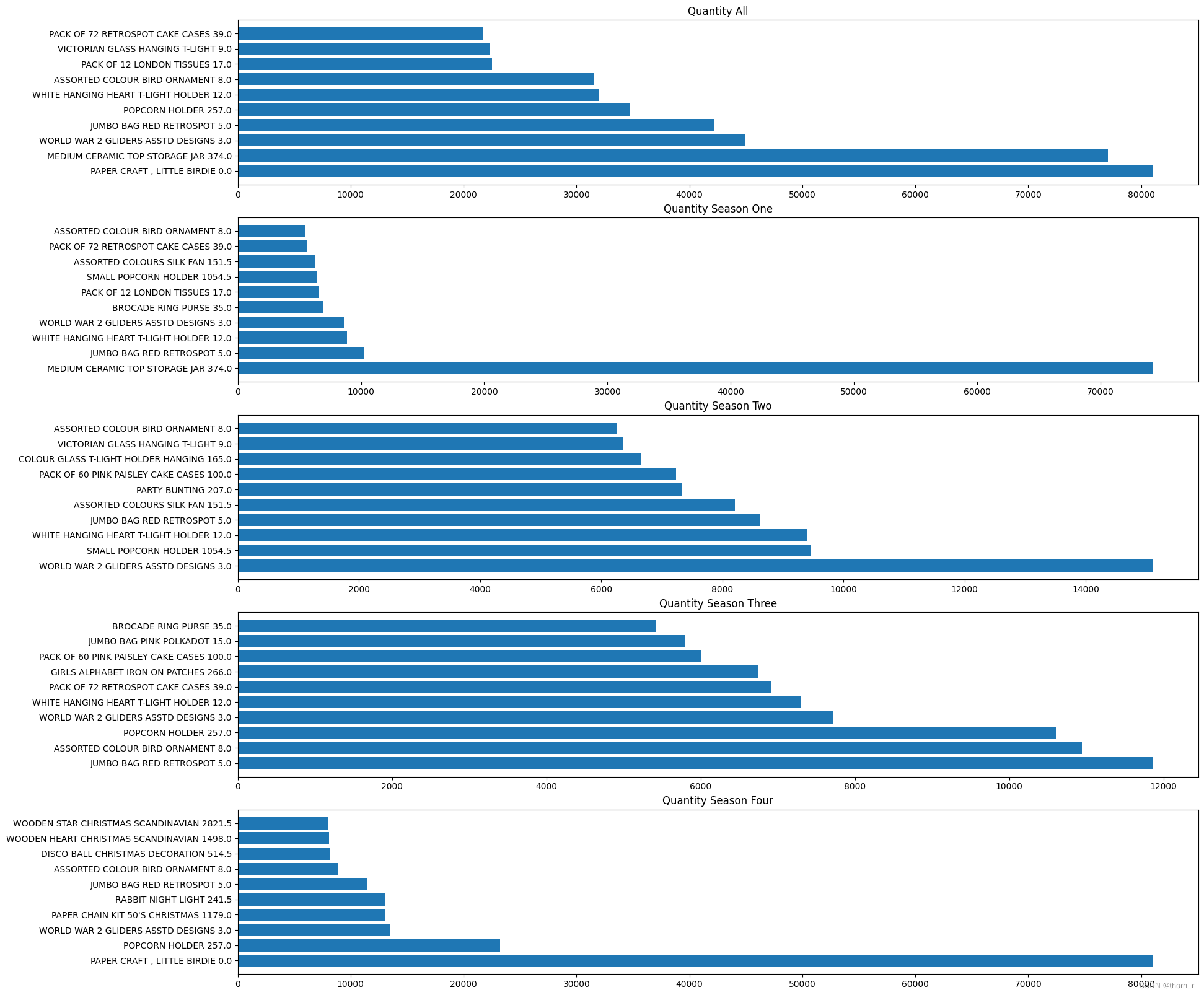
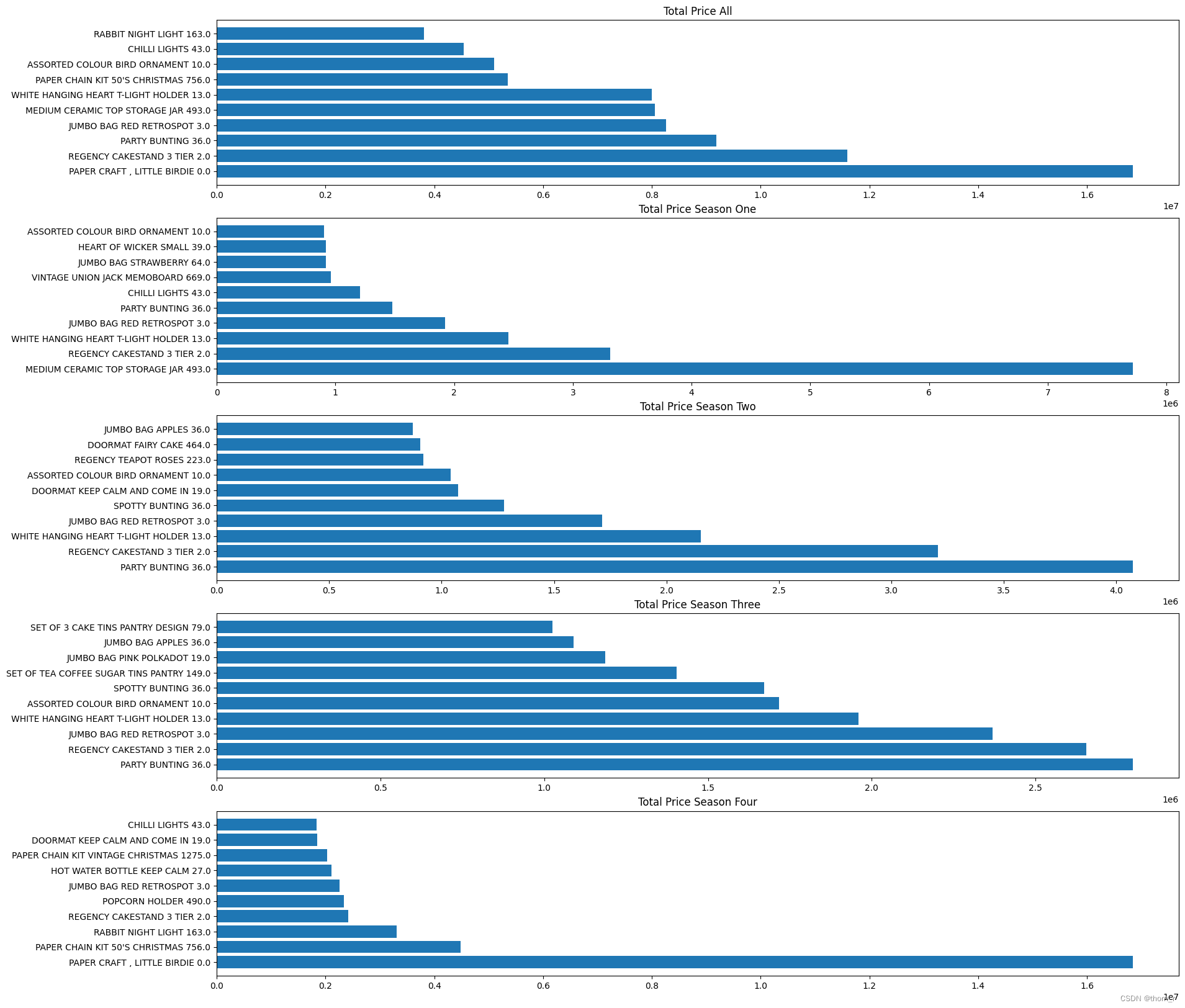
最终将全年的top10以及每个季度的top10作图,图中商品旁边标出了它对应销售额/销售量/成交量的排名的极差,可以看到,虽然大多数在全年销售中获得的top10排名极差都较小(总共有3000+个商品),但是在总销售额的全年top10中,依然有一个明显存在季节性效应的商品(PAPER CHAIN KIT 50's CHRISMAS)。
3、同一个商品在不同维度上是否排名差距较大
df_UK_all = df_UK_monthly.groupby(["Itemname"]).sum(["No_Of_Trans","Quantity","Total Price"]).reset_index()
df_UK_all["No_Of_Trans_Rank"] = df_UK_all["No_Of_Trans"].rank(ascending=False)
df_UK_all["Quantity_Rank"] = df_UK_all["Quantity"].rank(ascending=False)
df_UK_all["Total Price_Rank"] = df_UK_all["Total Price"].rank(ascending=False)
Rank_Gaps = [max(df_UK_all.loc[i,"No_Of_Trans_Rank"],df_UK_all.loc[i,"Quantity_Rank"],df_UK_all.loc[i,"Total Price_Rank"])\
- min(df_UK_all.loc[i,"No_Of_Trans_Rank"],df_UK_all.loc[i,"Quantity_Rank"],df_UK_all.loc[i,"Total Price_Rank"])\
for i in range(df_UK_all.shape[0])]
df_UK_all["Rank_Gaps"] = Rank_Gaps
df_ranked_all = df_UK_all.sort_values("Rank_Gaps",ascending=False).reset_index(drop=True)
plt.figure(figsize=(20,20))
for i in range(5):
plt.subplot(5,1,i+1)
sub = df_ranked_all.iloc[i,:]
item_name = sub["Itemname"]
sub = dict(sub)
sub_df = pd.DataFrame({"index":["No_Of_Trans_Rank","Quantity_Rank","Total Price_Rank"],\
"Value":[sub["No_Of_Trans_Rank"],sub["Quantity_Rank"],sub["Total Price_Rank"]]})
plt.barh(sub_df["index"],sub_df["Value"])
plt.title(item_name)
plt.show()
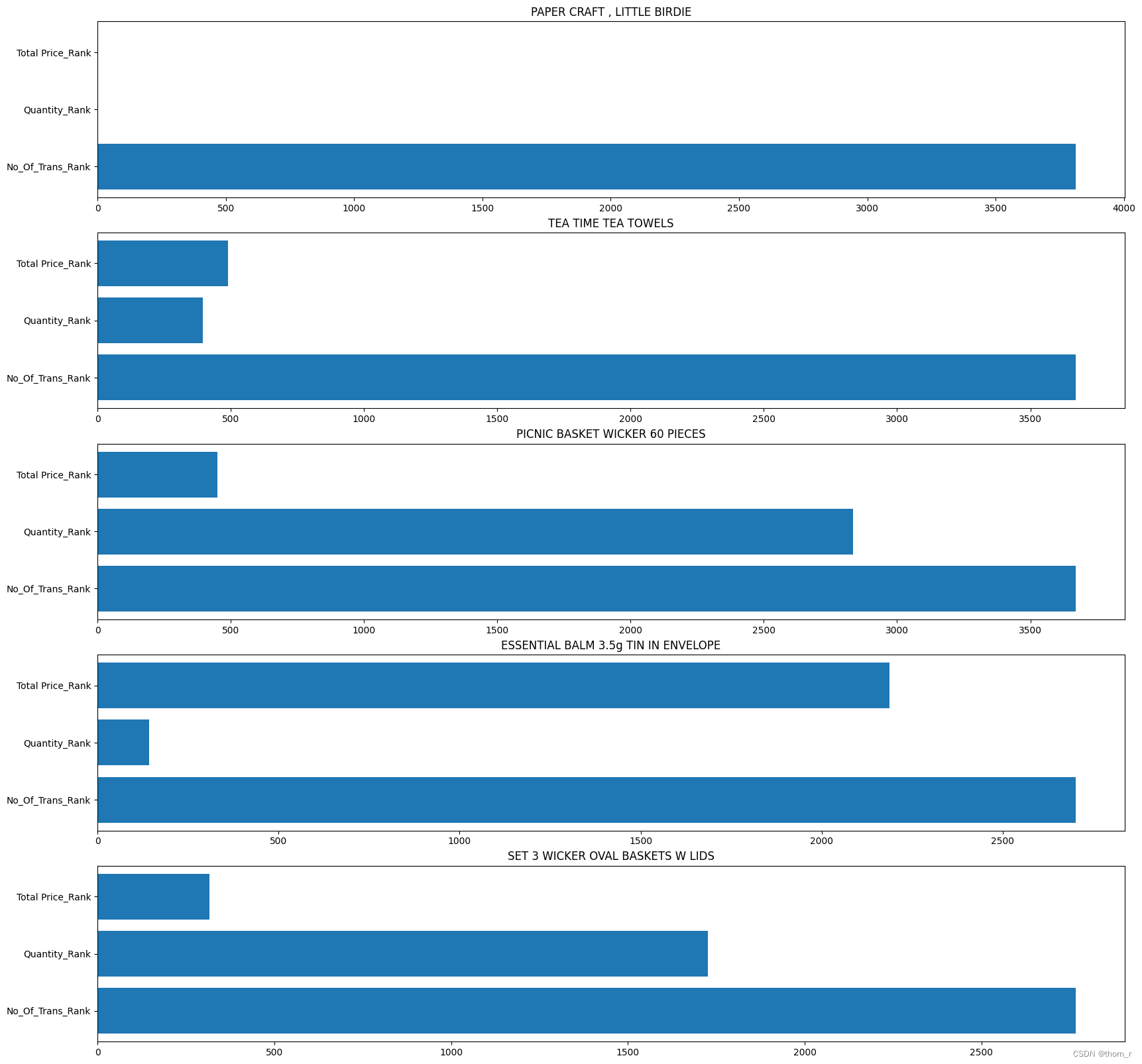
这里计算了每件商品在销售额、销售量、成交量上的排名并将这三个排名相差最大的5个商品列出了。可以发现上图中的商品,有些虽然销售额与销售量名列前茅,但是成交量却排名靠后。特别是第一名(PAPER CRAFT, LITTLE BRIDE),实际看表格数据时会发现它只有1个单子,但是那1个单子却订了8万多个这个商品。
4、探索客单价、客单量与平均售价
现在构造以下3个KPI:
客单量(UPT)= 销售量(Quantity)/成交量(No_Of_Trans)
平均售价(ASP)= 销售额(Total Price)/ 销售量(Quantity)
客单价(ATV)= 销售额(Total Price)/ 成交量(No_Of_Trans)
df_UK_monthly_KPI = df_UK_monthly.groupby(["Month"]).sum(["No_Of_Trans","Quantity","Total Price"]).reset_index()
df_UK_monthly_KPI["UPT"] = df_UK_monthly_KPI["Quantity"]/df_UK_monthly_KPI["No_Of_Trans"]
df_UK_monthly_KPI["ATV"] = df_UK_monthly_KPI["Total Price"]/df_UK_monthly_KPI["No_Of_Trans"]
df_UK_monthly_KPI["ASP"] = df_UK_monthly_KPI["Total Price"]/df_UK_monthly_KPI["Quantity"]
plt.plot(df_UK_monthly_KPI["Month"],df_UK_monthly_KPI["UPT"])
plt.title("Unit Per Transaction")
plt.show()
plt.plot(df_UK_monthly_KPI["Month"],df_UK_monthly_KPI["ATV"])
plt.title("Average Transaction Value")
plt.show()
plt.plot(df_UK_monthly_KPI["Month"],df_UK_monthly_KPI["ASP"])
plt.title("Average Selling Price")
plt.show()
plt.plot(df_UK_monthly_KPI["Month"],df_UK_monthly_KPI["No_Of_Trans"])
plt.title("No_Of_Trans")
plt.show()
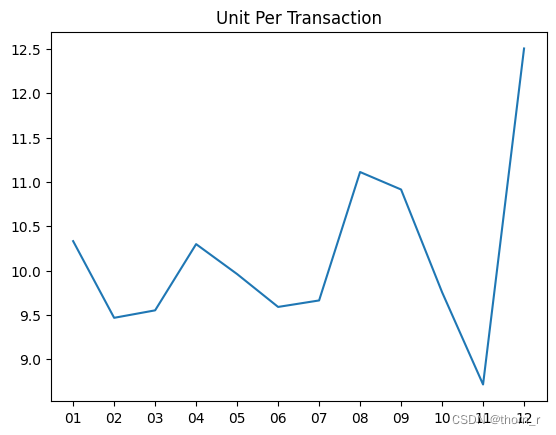
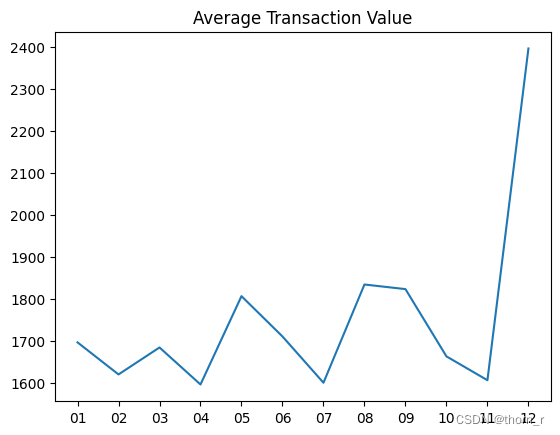
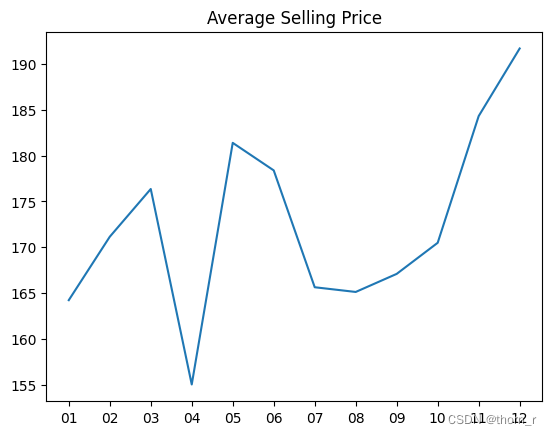
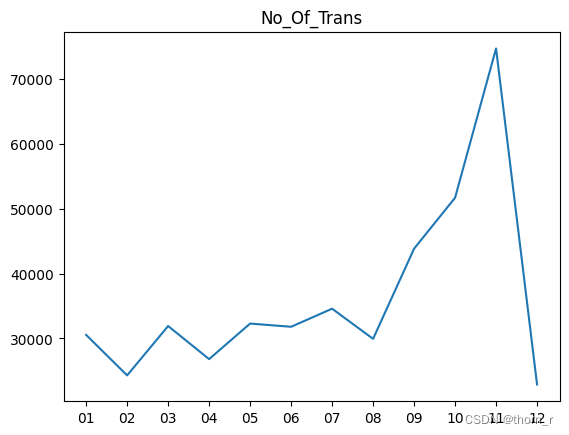
这里可以得出一个非常有趣的结论。11月的高销售额实际上是由于11月的高交易量。尽管12月份的销售额再次下降,但12月份的订单大多都是大单子。
5、(待定)探索客户价值
此处把Customer ID不为空的数据当做是会员数据
df_monthly_CustomerID = df_UK.groupBy(["CustomerID","Month"]).agg(F.countDistinct(F.col("BillNo")).alias("No_Of_Trans"),F.sum(F.col("Quantity")).alias("Quantity")
,F.sum(F.col("Total Price")).alias("Total Price")).toPandas()
df_by_CustomerID_by_Item = df_UK.groupBy(["CustomerID","Itemname"]).agg(F.countDistinct(F.col("BillNo")).alias("No_Of_Trans"),F.sum(F.col("Quantity")).alias("Quantity")
,F.sum(F.col("Total Price")).alias("Total Price")).toPandas()
df_monthly_CustomerID["CustomerID"] = df_monthly_CustomerID["CustomerID"].astype(str)
df_monthly_CustomerID["isMember"] = [str(i)!='99999' for i in df_monthly_CustomerID["CustomerID"]]
df_monthly_Member = df_monthly_CustomerID[df_monthly_CustomerID["isMember"]==True].groupby("Month").sum(["No_Of_Trans","Total Price"]).sort_index()
df_monthly_Non_Member = df_monthly_CustomerID[df_monthly_CustomerID["isMember"]==False].reset_index()
df_monthly_Non_Member.index=df_monthly_Non_Member["Month"]
df_monthly_Non_Member = df_monthly_Non_Member.sort_index()
plt.figure(figsize=(8,8))
plt.bar(df_monthly_Member.index,df_monthly_Member["Total Price"],color="#66c2a5",label="Member")
plt.bar(df_monthly_Non_Member.index,df_monthly_Non_Member["Total Price"],bottom=df_monthly_Member["Total Price"],color="#8da0cb",label="Non-Member")
plt.legend()
plt.show()
df_monthly_Member_No_of_Trans = df_monthly_CustomerID[df_monthly_CustomerID["isMember"]==True].groupby("Month").sum("No_Of_Trans").sort_index()
plt.figure(figsize=(8,8))
plt.bar(df_monthly_Member_No_of_Trans.index,df_monthly_Member_No_of_Trans["No_Of_Trans"],color="#66c2a5",label="Member")
plt.bar(df_monthly_Non_Member.index,df_monthly_Non_Member["No_Of_Trans"],bottom=df_monthly_Member_No_of_Trans["No_Of_Trans"],color="#8da0cb",label="Non-Member")
plt.legend()
plt.show()

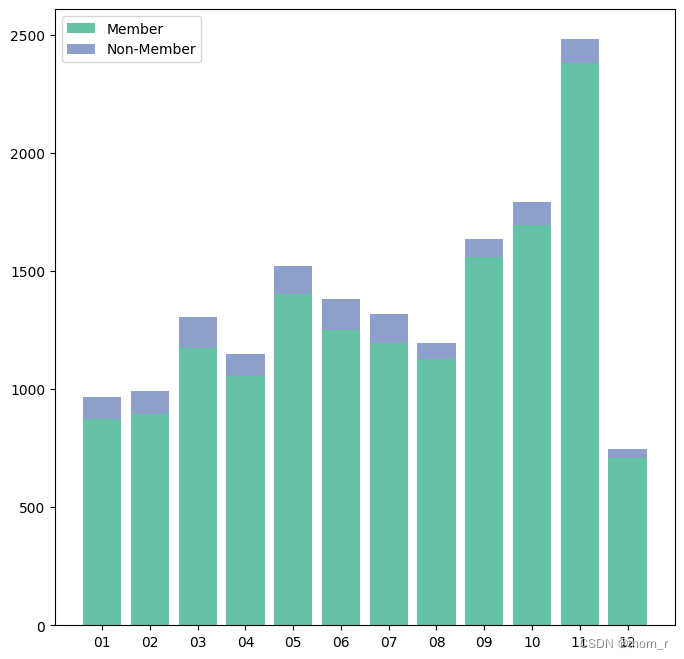
从图中来看,无论是交易量还是销售额,都是会员销售占大多数的。这样的结论对我而言过于反直觉,因此我没有做后续的分析。
三、关联规则分析
关联规则分析为的就是发现商品与商品之间的关联。通过计算商品之间的支持度、置信度与提升度,分析哪些商品有正向关系,顾客愿意同时购买它们。
此处使用了pyspark自带的FPGrowth算法。它和APRIORI算法一样都是计算两两商品之间支持度置信度与提升度的算法,虽然算法流程不同,但是计算结果是一样的。
from pyspark.ml.fpm import FPGrowth,FPGrowthModel
df_UK_concatenated=df_UK.groupby(["BillNo","Itemname"]).agg(F.sum("Quantity").alias("Quantity")).groupby("BillNo").agg(F.collect_list(F.col("Itemname")).alias("items"))
model = FPGrowth(minSupport=0.03,minConfidence=0.3)
model = model.fit(df_UK_concatenated.select("items"))
res = model.associationRules.toPandas()
import itertools
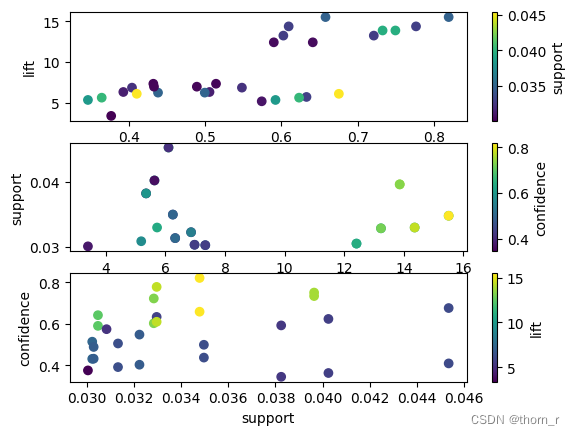
combs = [('confidence', 'lift', 'support'),('lift', 'support', 'confidence'),('support', 'confidence', 'lift')]
for i,(x,y,c) in enumerate(combs):
plt.subplot(3,1,i+1)
sc = plt.scatter(res[x],res[y],c=res[c],cmap='viridis')
plt.xlabel(x)
plt.ylabel(y)
plt.colorbar(sc,label=c)
plt.show()
res.sort_values("support",ascending=False).head(6)
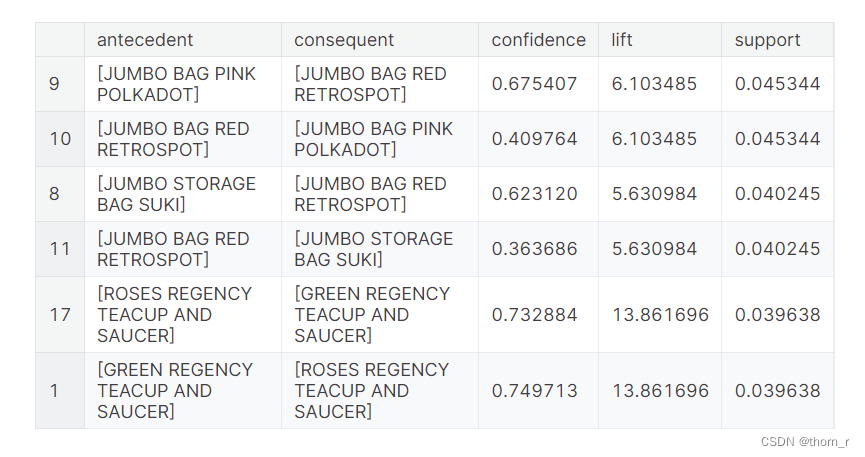
上图是支持度(support)前三的商品组合(每2条实际上是同一组商品)。
支持度指的是2件商品同时出现的概率。
res.sort_values("confidence",ascending=False).head(5)
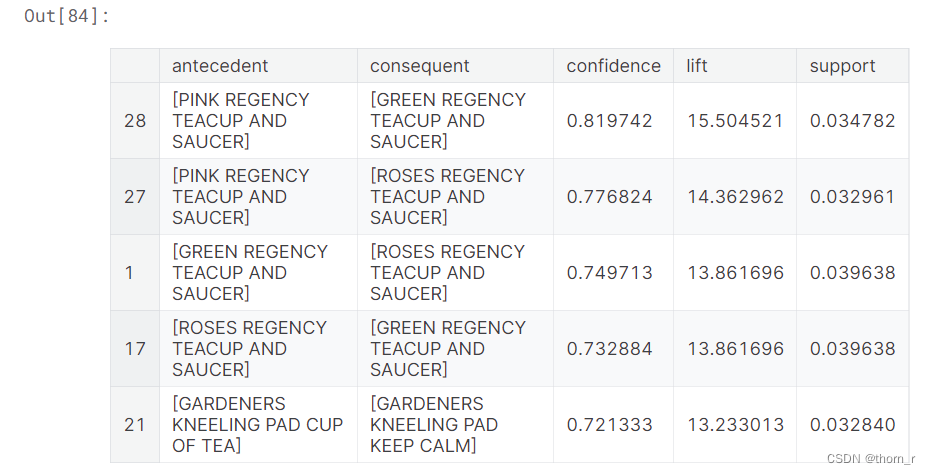
上图是置信度(confidence)前5的商品组合,置信度指的是当商品A被购买时,商品B也被购买的概率。
res.sort_values("lift",ascending=False).head(6)
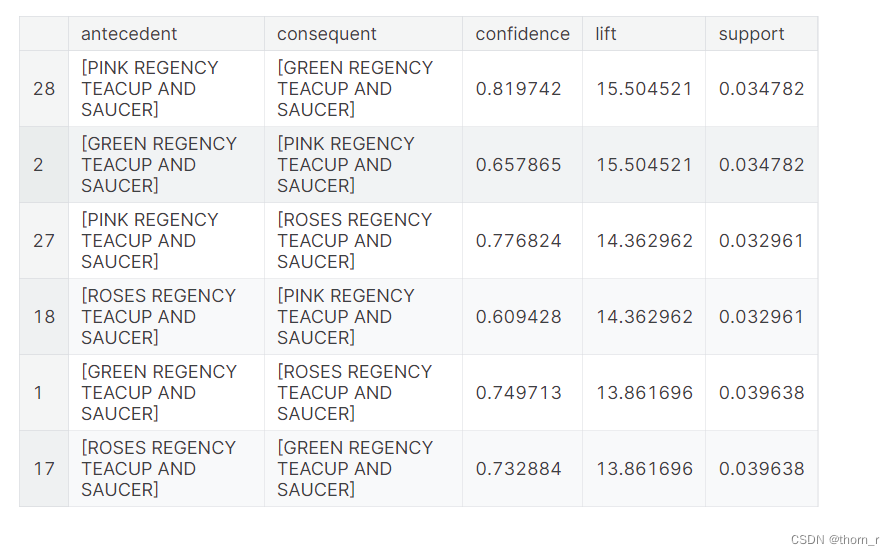
上图是提升度(lift)前三的商品组合(每2条实际上是同一组商品)。 提升度可以看做是2件商品之间是否存在正向/反向的关系。
最后将提升度降序排列打印出来:
res.sort_values("lift",ascending=False)
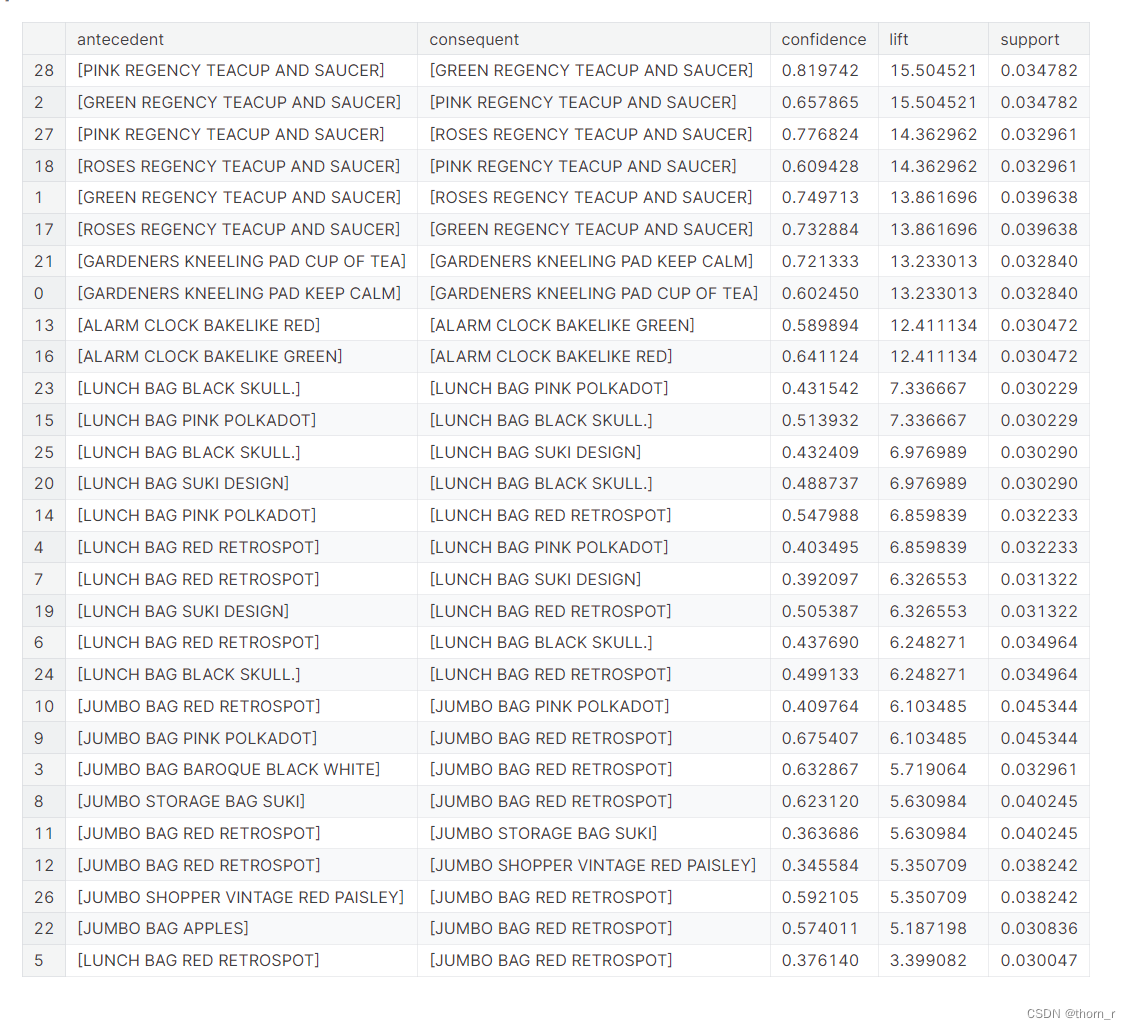
我们发现顾客最常见的组合是不同颜色的杯子和碟子。
其他产品,如午餐袋、Jumbo Bag或闹钟也处于同样的情况。
总的来说,最常见的组合是同一种产品不同的颜色。
四、结论
1、英国2011年时11月份销售量急剧上升,12月份又有所回落
2、11月的销售量高是因为11月的成交量大,而在12月,虽然销售量相对较小,但实际上12月的每笔交易都是大交易,数量和价格都很大。
3、许多产品都有季节性影响,即使是当年销量排名前10的产品(PAPER CHAIN KIT 50’s CHRISMAS)
4、有些产品虽然交易量很少,但销量却遥遥领先(如PAPER CRAFT, LITTLE BIRDIE, 2011年只有1笔交易,但销量第一)。
5、最常见的组合是同一产品不同颜色的组合。最典型的例子就是杯子和碟子。
版权归原作者 thorn_r 所有, 如有侵权,请联系我们删除。