
Theta方法整合了两个基本概念:分解时间序列和利用基本预测技术来估计未来的价值。
每个数据科学爱好者都知道,时间序列是按一定时间间隔收集或记录的一系列数据点。例如,每日温度或经济指标的月值。把时间序列想象成不同成分的组合,趋势(数据移动的一般方向),季节性(随时间重复的规律模式)和噪声(不能归因于趋势或季节性的随机波动)是时间序列预测的常用方法

什么是θ方法?
Theta方法核心思想是将时间序列数据分解为两个或多个子序列,然后对每个子序列分别应用简单的指数平滑技术。

Theta方法的关键在于其分解过程,它将原始时间序列通过一种特定的“Theta线”分解技术,把时间序列分解为趋势组件和随机波动组件。这种分解有助于更清晰地看到数据中的趋势和周期性变化,从而使预测更为准确。
在应用Theta方法时,通常会使用两条Theta线:一条用于捕捉序列的长期趋势(通常称为Theta(0)),另一条用于描述更短期的波动(Theta(2))。这两个组件经过适当的处理和组合,最终形成最终的预测模型
Theta方法修改时间序列以突出显示不同的组件。这是通过在原始序列中添加或减去趋势分量来完成的。例如,如果我们选择Theta值为2,则我们创建了一个趋势影响加倍的新系列。如果θ为0,则完全去除趋势,只关注周期性和不规则成分。
在对序列进行处理后,它受到基本预测技术的影响,如指数平滑,通过平滑短期波动来突出长期模式。Theta方法的优点在于其简便性和对数据不高的需求,使得它非常适合对于时间序列数据进行快速而有效的预测。此外这种方法在多个预测比赛中表现出色,证明了其有效性。
在Python中创建用于时间序列分析的Theta方法算法
如果你正在试图预测一家商店未来的销售额。你会注意到,这些年来销售额总体上是增长的(趋势),但每年12月的销售额也有一个高峰(季节性)。最重要的是,由于各种不可预测的因素(噪音),销售额会随机波动。
Theta方法可以帮助分离这些不同的影响,从而更容易理解潜在的模式。通过分别关注和预测每个组成部分,然后将这些预测结合起来,可以对未来的销售做出更可靠的预测。
下面我们在Python中创建一个非常简单的算法,它使用Theta方法来预测ISM PMI的未来值。
PMI是指美国供应管理协会(ISM)的采购经理人指数(PMI)。这是一个受到广泛关注的经济指标,可以洞察制造业和服务业的整体健康状况。
PMI指数高于50表明制造业或服务业正在扩张,而低于50则意味着收缩。
算法代码如下:
importnumpyasnp
importpandasaspd
importmatplotlib.pyplotasplt
fromstatsmodels.tsa.holtwintersimportExponentialSmoothing
deftheta_decomposition(time_series, theta):
trend=np.polyval(np.polyfit(np.arange(len(time_series)), time_series, 1), np.arange(len(time_series)))
deseasonalized=time_series-trend
theta_series=deseasonalized+ (theta*trend)
returntheta_series, trend
defforecast_theta(time_series, theta, forecast_horizon):
# Decompose the time series
theta_series, trend=theta_decomposition(time_series, theta)
# Fit an Exponential Smoothing model on the theta series
model=ExponentialSmoothing(theta_series, seasonal='add', seasonal_periods=12).fit()
# Forecast the future values
forecast_values=model.forecast(forecast_horizon)
# Add the trend component back to the forecasted values
trend_forecast=np.polyval(np.polyfit(np.arange(len(time_series)), time_series, 1),
np.arange(len(time_series), len(time_series) +forecast_horizon))
final_forecast=forecast_values+trend_forecast
returnfinal_forecast
if__name__=="__main__":
time_series=pd.read_excel('ISM_PMI.xlsx')
time_series['Date'] =pd.to_datetime(time_series['Date'])
time_series.set_index('Date', inplace=True)
time_series=time_series['Value']
# Set theta and forecast horizon
theta=0
forecast_horizon=12
# Forecast future values
forecast_values=forecast_theta(time_series, theta, forecast_horizon)
# Plot the original series and the forecast
plt.figure(figsize=(10, 6))
plt.plot(time_series[-100:,], label='ISM PMI')
plt.plot(pd.date_range(start=time_series.index[-1], periods=forecast_horizon+1, freq='M')[1:], forecast_values, label='Forecast', color='red')
plt.title('Theta Method')
plt.xlabel('Date')
plt.ylabel('ISM PMI')
plt.legend()
plt.grid()
plt.show()
这里我们选择在Theta方法中使用指数平滑算法。
下图显示了使用Theta方法对未来12个月ISM PMI的预测。
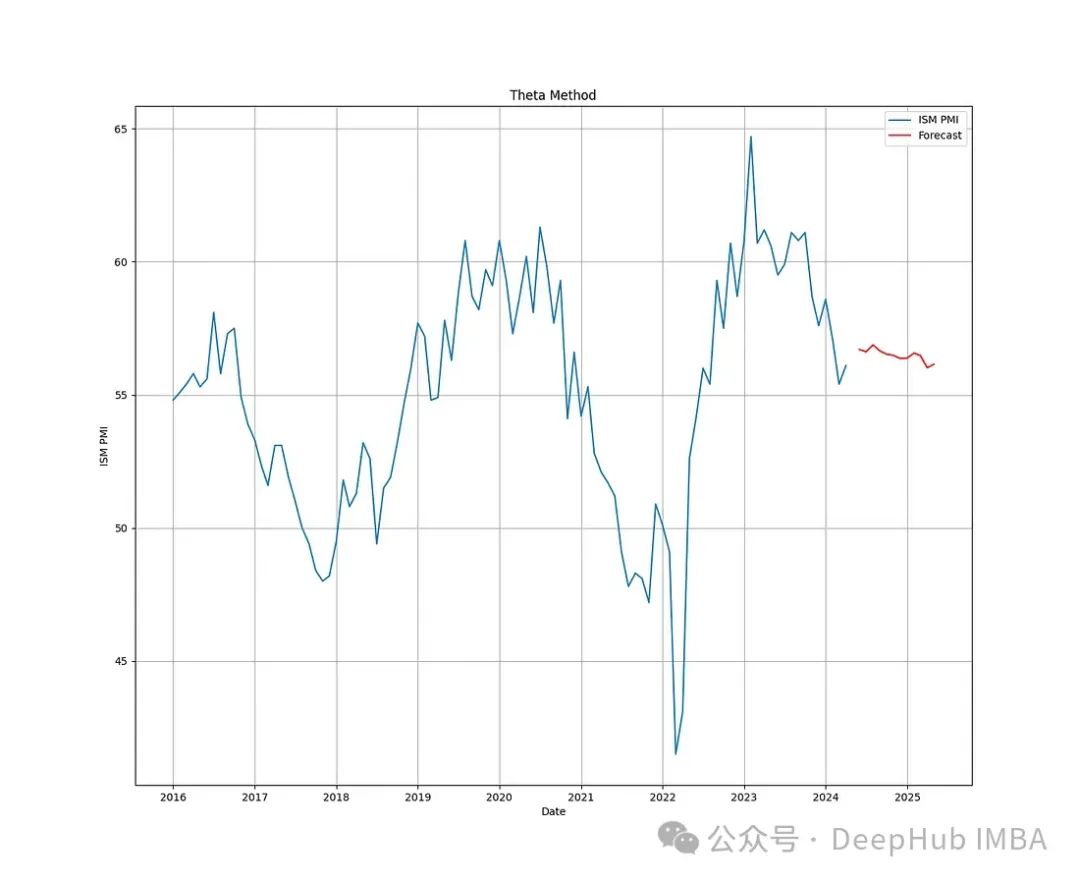
我们上面演示了简单的指数平滑算法,因为Theta方法包含了2个步骤:
1、分解时间序列;2、对不同的子序列应用适当的预测
所以这两种方法都可以使用不同的方法进行,我们下面做一个简单的总结:
分解时间序列
Theta方法的分解主要是通过处理时间序列的趋势和季节性组件来实现,其核心思想是将原始序列转化为更简单的子序列,然后对这些子序列进行预测。这种方法虽然在原始提出时没有特别复杂的分解方法,但它依赖于一种关键的转换,即“Theta线”。下面是几种常用于时间序列分解的方法,这些方法可以与Theta方法结合使用或作为其分解步骤的参考:
- 趋势和季节性分解:- 经典分解:将时间序列分解为趋势、季节性和随机成分。这种方法通常假设季节性和趋势成分的长度是固定的。- STL分解(季节性和趋势分解):这是一种更为灵活的分解方法,允许季节性组件随时间变化,适用于处理复杂的季节性模式。
- 指数平滑状态空间模型:- 单一指数平滑:用于没有趋势和季节性的数据。- 双重指数平滑:添加趋势成分的处理。- 三重指数平滑(Holt-Winters方法):同时处理趋势和季节性变化。
- 差分:- 季节性差分:用于减少数据中的季节性效应。- 一阶或高阶差分:用于使非平稳序列平稳化,通过消除趋势成分。
- Theta线:- Theta(0)和Theta(2)线:在原始的Theta方法中,时间序列通过调整二阶差分的系数来创建两条Theta线。Theta(0)通常适用于平滑处理,捕捉更长期的趋势;Theta(2)则强调更短期的波动。
通过这些分解技术,可以更好地理解和预测时间序列数据的动态。在实际应用中,选择哪种分解方法取决于数据的特点以及预测的具体需求。Theta方法的优点在于它通过一个相对简单的处理过程,将复杂的时间序列转换为更易于分析和预测的形式。
子序列预测
移动平均(MA):
这是一种简单的技术,通过计算时间序列中一定数量的最近数据点的平均值来进行预测。这种方法适用于平滑数据并预测短期趋势。
指数平滑(Exponential Smoothing):
单一指数平滑适用于没有明显趋势和季节性的数据;双重指数平滑用于有趋势无季节性的数据;三重指数平滑(Holt-Winters方法)适用于同时具有趋势和季节性的数据。
自回归模型(AR):
自回归模型是通过前几期的数据值来预测未来值,这种模型假设未来的值与历史值之间存在线性关系。
机器学习方法:
线性回归、决策树和随机森林、深度学习的方法
总结
Theta方法是一种时间序列预测技术,因其操作简单和有效性而在许多应用场景中得到了广泛的使用。这种方法主要通过分解时间序列并应用简单的指数平滑来预测未来的值,特别是在处理具有明显趋势的数据时表现出色。它的主要优势在于易于实施和理解,对于非专业人士也较为友好,且由于其简洁性,Theta方法在计算成本上相当低,适合于大规模数据集的快速预测。
但是Theta方法也存在一些局限。首先,它在原始版本中并不直接处理季节性变化,这可能会限制其在处理季节性明显的时间序列数据时的适用性。此外,该方法对时间序列的趋势做了线性假设,这意味着它可能无法很好地处理趋势非线性或更复杂模式的数据。尽管Theta方法在多个预测比赛中表现优异,但它的理论基础相对薄弱,主要是基于经验的应用导向,这在某些统计严谨性要求较高的场合可能是一个缺点。
尽管Theta方法本身简单,但要达到最佳预测效果,选择合适的参数和组合策略是必需的,这有时需要依靠预测者的经验和实验。因此尽管Theta方法在许多情况下非常有用,但它也需要在特定的应用背景下进行适当的调整和优化。