


专栏:机器学习笔记
pycharm专业版免费激活教程见资源,私信我给你发
python相关库的安装:pandas,numpy,matplotlib,statsmodels
总篇:学习路线
第一卷:线性回归模型
逻辑回归(Logistic Regression)是一种适用于二分类问题的机器学习方法。本文将围绕一个具体的乳腺癌检测案例,详细讲解如何在PyCharm中使用逻辑回归模型进行预测。我们将从数据准备、数据预处理、模型训练、模型评估和结果可视化几个方面进行详细说明,并通过完整的代码示例展示每个步骤。
案例背景
在本案例中,我们将使用经典的乳腺癌数据集(Breast Cancer Dataset)进行乳腺癌检测预测。该数据集包含569个样本,每个样本有30个特征,并标记为良性(0)或恶性(1)。我们的目标是使用这些特征训练一个逻辑回归模型,预测新的样本是良性还是恶性。
具体问题
我们需要解决以下几个具体问题:
- 如何加载并理解乳腺癌数据集。
- 如何对数据进行预处理以适合逻辑回归模型的训练。
- 如何训练逻辑回归模型并进行预测。
- 如何评估模型的性能。
- 如何对结果进行可视化以便于解释。
1. 环境准备
首先,确保你的开发环境中已经安装了必要的Python库:
pip install numpy pandas scikit-learn matplotlib seaborn
小李的理解
安装库是机器学习的基础步骤。我们需要安装一些流行的Python库,如
numpy
、
pandas
、
scikit-learn
、
matplotlib
和
seaborn
,这些库分别用于数值计算、数据处理、机器学习模型、绘图和数据可视化。
知识点
- 库的安装:使用
pip install命令安装所需的Python库。- 常用库:了解并熟悉常用的机器学习和数据处理库。
2. 数据准备
2.1 导入必要的库和数据集
我们使用
scikit-learn
库中的乳腺癌数据集。
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
# 加载数据集
data = load_breast_cancer()
X = data.data
y = data.target
小李的理解
scikit-learn
提供了很多常用的数据集,
load_breast_cancer()
是用来加载乳腺癌数据集的方法。
X
是特征数据,
y
是目标标签(0表示良性,1表示恶性)。
知识点
- 数据集加载:使用
scikit-learn中的方法加载内置数据集。- 特征与标签:特征数据用于模型训练,目标标签用于分类。
2.2 数据集基本信息
将数据转换为Pandas DataFrame格式以便查看和处理,并打印数据集的前几行进行初步了解。
# 将数据转换为DataFrame格式
df = pd.DataFrame(X, columns=data.feature_names)
df['target'] = y
# 查看数据集的基本信息
print("数据集前五行:\n", df.head())
print("\n数据集描述统计信息:\n", df.describe())
print("\n数据集信息:")
df.info()
运行结果

小李的理解
我们使用
pandas
库将数据转换为DataFrame格式,这样可以方便地查看和处理数据。使用
head()
查看数据的前几行,使用
describe()
查看数据的描述统计信息,使用
info()
查看数据的基本信息,包括每列的数据类型和非空值数量。
知识点
- DataFrame:
pandas的核心数据结构,类似于电子表格,可以方便地操作和分析数据。- 数据描述:通过
head()、describe()和info()方法快速了解数据的基本情况。
注意事项
- 数据完整性:在加载数据时,确保数据没有缺失值。本数据集没有缺失值。
- 数据类型:特征值都是浮点型,而目标值是整数型。逻辑回归适用于这些数据类型。
3. 数据预处理
3.1 划分训练集和测试集
将数据集划分为训练集和测试集,以便后续模型的训练和评估。
from sklearn.model_selection import train_test_split
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 打印训练集和测试集的大小
print(f'训练集样本数: {X_train.shape[0]}')
print(f'测试集样本数: {X_test.shape[0]}')
运行结果
小李的理解
我们将数据集分为训练集和测试集,训练集用于训练模型,测试集用于评估模型的性能。
train_test_split
函数将数据按70%训练集和30%测试集的比例进行划分,并使用
random_state=42
保证每次运行结果一致。
知识点
- 数据划分:使用
train_test_split函数将数据集分为训练集和测试集。- 随机种子:
random_state参数保证结果的可重复性。
注意事项
- 随机种子:
random_state=42保证每次运行结果一致,方便调试和复现。- 测试集比例:通常使用70%的数据进行训练,30%的数据进行测试,但具体比例可以根据实际情况调整。
3.2 数据标准化
由于不同特征的取值范围不同,需要对数据进行标准化处理,使每个特征的取值范围相同。
from sklearn.preprocessing import StandardScaler
# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 打印标准化后的部分数据
print(f'标准化后的训练数据前五行:\n {X_train[:5]}')
运行结果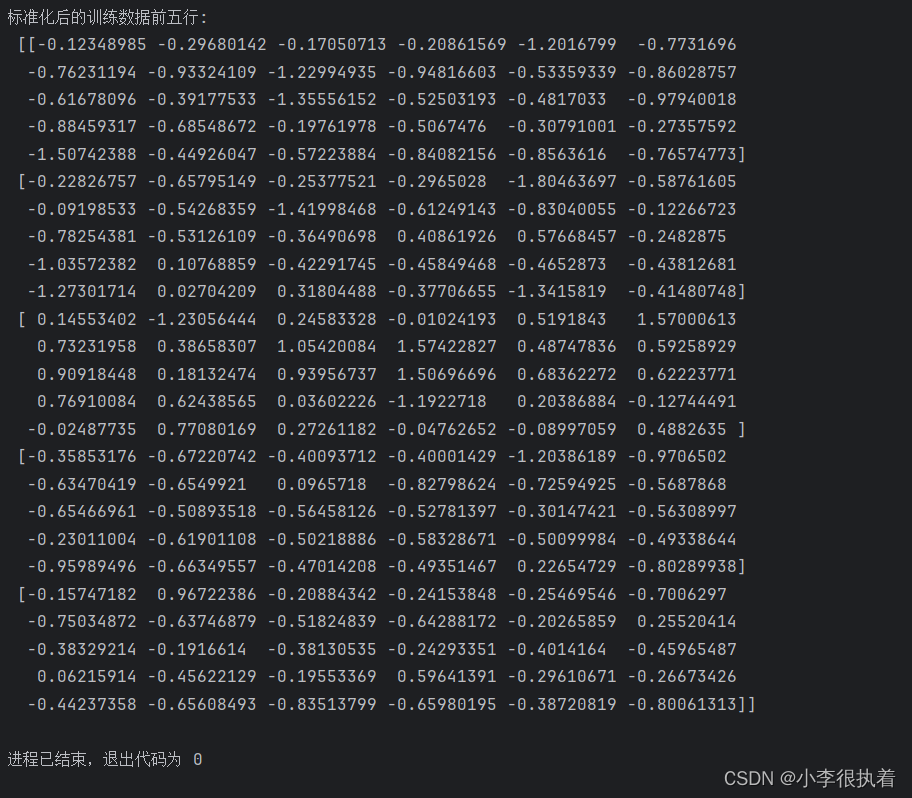
小李的理解
标准化是将每个特征缩放到均值为0、标准差为1的范围内,这样可以消除不同特征之间的量纲差异,使模型训练更加稳定。我们使用
StandardScaler
进行标准化,只对训练数据拟合,然后对训练和测试数据进行转换。
知识点
- 标准化:使用
StandardScaler将数据标准化,以消除特征之间的量纲差异。- 数据泄漏:在标准化时,只对训练数据进行拟合,然后对训练和测试数据进行转换。
注意事项
- 标准化方法:我们使用
StandardScaler将每个特征缩放到均值为0、标准差为1的范围内。- 数据泄漏:在标准化时,我们仅对训练数据拟合(fit),然后对训练和测试数据进行转换(transform),以避免数据泄漏。
4. 模型训练
4.1 初始化和训练逻辑回归模型
使用
scikit-learn
库中的逻辑回归模型对训练数据进行拟合。
from sklearn.linear_model import LogisticRegression
# 初始化逻辑回归模型
model = LogisticRegression(max_iter=10000)
# 训练模型
model.fit(X_train, y_train)
# 打印模型的训练结果
print("逻辑回归模型训练完成")
运行结果

小李的理解
我们使用
LogisticRegression
类来初始化逻辑回归模型,并设置最大迭代次数为10000,以确保模型能够收敛。然后,我们使用训练数据拟合模型。
知识点
- 逻辑回归模型:
LogisticRegression类用于初始化逻辑回归模型。- 最大迭代次数:
max_iter参数用于设置模型的最大迭代次数,以确保模型能够收敛。
注意事项
- 最大迭代次数:
max_iter=10000确保模型能够收敛,即使数据集较大或特征较多。- 默认参数:初学者可以先使用默认参数,之后可以尝试调整参数以优化模型性能。
5. 模型评估
5.1 预测结果
使用训练好的模型对测试集进行预测。
# 预测
y_pred = model.predict(X_test)
# 打印预测结果的前十个
print(f'预测结果前十个: {y_pred[:10]}')
运行结果

小李的理解
我们使用
predict
方法对测试数据进行预测,得到每个样本的预测标签。然后,我们打印预测结果的前十个样本。
知识点
- 模型预测:使用
predict方法对测试数据进行预测。- 预测标签:
predict方法返回每个样本的预测标签。
注意事项
- 预测输出:
predict方法输出每个样本的预测标签。- 预测概率:可以使用
predict_proba方法获取每个样本属于每个类别的概率。
5.2 计算准确率
计算模型在测试集上的准确率。
from sklearn.metrics import accuracy_score
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
运行结果
小李的理解
准确率是模型正确预测的样本数占总样本数的比例,是评估模型性能的一个重要指标。
知识点
- 准确率:使用
accuracy_score函数计算模型的准确率。- 模型评估:准确率是评估模型性能的一个重要指标。
注意事项
- 准确率定义:准确率是正确预测的样本数占总样本数的比例。
- 适用场景:对于类别不平衡的问题,仅使用准确率可能会导致误导,应结合其他指标。
5.3 混淆矩阵
生成并打印混淆矩阵,混淆矩阵可以直观地显示模型的分类性能。
from sklearn.metrics import confusion_matrix
# 混淆矩阵
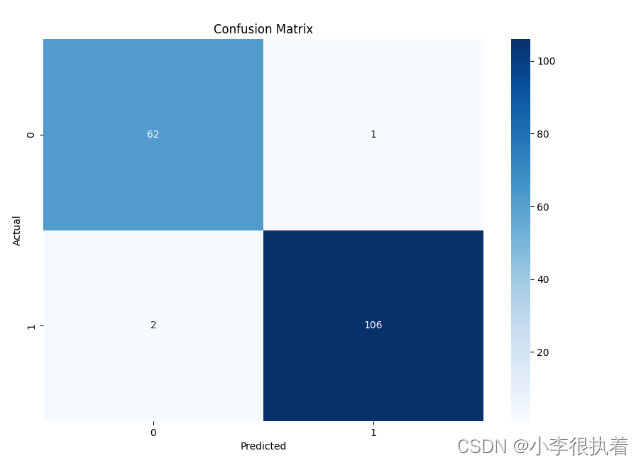
conf_matrix = confusion_matrix(y_test, y_pred)
print('Confusion Matrix:')
print(conf_matrix)
运行结果

小李的理解
混淆矩阵是一个矩阵,用来评价分类模型的性能。矩阵的每一行表示实际类别,每一列表示预测类别。
知识点
- 混淆矩阵:使用
confusion_matrix函数生成混淆矩阵。- 矩阵解读:混淆矩阵的每一行表示实际类别,每一列表示预测类别。
注意事项
- 混淆矩阵解读: - 左上(TP):正确预测为正类的数量- 右上(FP):错误预测为正类的数量- 左下(FN):错误预测为负类的数量- 右下(TN):正确预测为负类的数量
- 评估模型:通过混淆矩阵可以计算精确度、召回率等指标。
5.4 分类报告
生成并打印分类报告,报告包括精确度、召回率和F1分数等指标。
from sklearn.metrics import classification_report
# 分类报告
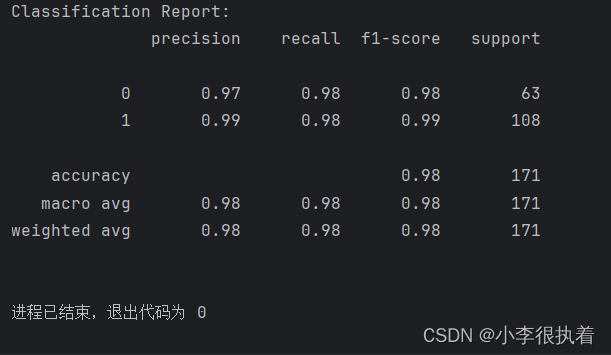
class_report = classification_report(y_test, y_pred)
print('Classification Report:')
print(class_report)
运行结果
小李的理解
分类报告提供了每个类别的精确度、召回率和F1分数,以及整体的宏平均(macro avg)和加权平均(weighted avg)指标。这些指标可以帮助我们更全面地评估模型的性能。
知识点
- 分类报告:使用
classification_report函数生成分类报告。- 评估指标:分类报告包括精确度、召回率和F1分数等指标。
注意事项
- 精确度(Precision):预测为正类的样本中实际为正类的比例。
- 召回率(Recall):实际为正类的样本中被正确预测为正类的比例。
- F1分数(F1-score):精确度和召回率的调和平均数,综合考虑模型的准确性和召回能力。
6. 结果可视化
6.1 绘制混淆矩阵
使用Seaborn库对混淆矩阵进行可视化。
import matplotlib.pyplot as plt
import seaborn as sns
# 绘制混淆矩阵
plt.figure(figsize=(10, 7))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues')
plt.title('Confusion Matrix')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()
可视化结果
小李的理解
通过绘制混淆矩阵,我们可以直观地看到模型的分类效果。
seaborn
库提供了简洁的绘图方法,使得可视化更加美观和易于理解。
知识点
- 数据可视化:使用
seaborn库进行数据可视化。- 混淆矩阵图:通过绘制混淆矩阵图,可以直观地展示模型的分类效果。
注意事项
- 图像解释:混淆矩阵图表提供了直观的分类性能展示。
- 颜色选择:可以根据需要调整颜色映射,以便于区分不同类别。
完整代码
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
import matplotlib.pyplot as plt
import seaborn as sns
# 1. 加载数据集
data = load_breast_cancer()
X = data.data
y = data.target
# 2. 数据准备
df = pd.DataFrame(X, columns=data.feature_names)
df['target'] = y
# 查看数据集的基本信息
print("数据集前五行:\n", df.head())
print("\n数据集描述统计信息:\n", df.describe())
print("\n数据集信息:")
df.info()
# 3. 数据预处理
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 打印训练集和测试集的大小
print(f'训练集样本数: {X_train.shape[0]}')
print(f'测试集样本数: {X_test.shape[0]}')
# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 打印标准化后的部分数据
print(f'标准化后的训练数据前五行:\n {X_train[:5]}')
# 4. 模型训练
# 初始化逻辑回归模型
model = LogisticRegression(max_iter=10000)
# 训练模型
model.fit(X_train, y_train)
# 打印模型的训练结果
print("逻辑回归模型训练完成")
# 5. 模型评估
# 预测
y_pred = model.predict(X_test)
# 打印预测结果的前十个
print(f'预测结果前十个: {y_pred[:10]}')
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
# 混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
print('Confusion Matrix:')
print(conf_matrix)
# 分类报告
class_report = classification_report(y_test, y_pred)
print('Classification Report:')
print(class_report)
# 6. 结果可视化
# 绘制混淆矩阵
plt.figure(figsize=(10, 7))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues')
plt.title('Confusion Matrix')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()

结论
通过本文的讲解,在PyCharm中使用逻辑回归模型进行乳腺癌检测的预测。从数据准备、数据预处理、模型训练到结果评估与可视化,提供了详细的步骤和代码示例。通过这些步骤,你可以掌握如何应用逻辑回归模型进行疾病预测,并根据模型的评估结果优化和改进模型。
版权归原作者 小李很执着 所有, 如有侵权,请联系我们删除。