
私有化知识库本地部署打造专属ai助理(FastGpt本地部署全过程及相关模型部署训练)
引言
在人工智能和机器学习领域,OneAPI是一个开放、统一的编程模型,旨在简化跨多种硬件架构的应用程序开发。FastGPT作为一个先进的知识库管理系统,结合OneAPI的强大功能,可以为用户提供一个高效、灵活且可扩展的解决方案。本文将探讨FastGPT与OneAPI之间的关系,以及它们如何协同工作来提升知识库管理的效率。
FastGPT简介
FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力,通过FastGp可以快速的进行搭建和训练一个AI助理。
OneAPI概述
OneApi的作用就是把这些API的调用进行了整合到了一起,使我们进行使用的时候完全的按照OneAPI的一套规范就能够进行调用和使用其他的大模型,无疑OneApi极大的进行提高了我们进行学习AI的效率,不用在不同的模型接口之间进行切换,也使得FastApi可以直接的通过这套规范进行训练.
FastGpt前置基础知识
5大模型类别
- LLMModule(大型语言模型) : 大型语言模型(LLM)是设计用来处理和理解人类语言的AI模型。它们通常在大量的文本数据上进行训练,能够执行语言翻译、文本摘要、问答以及文本生成等任务。 - qwen-tubo(初代的通义千问文本模型,我们日常聊天的文本模型), chat-3.5-turbo(ChatGPT3.5)
- vectorModels(向量模型) :向量模型用于将数据(通常是文本或图像)表示为高维空间中的向量。这些模型在机器学习和AI中是基础性的,用于执行相似性搜索、聚类和分类等任务LLM的模型训练就是基于向量模型.
- reRankModels(重排模型): 重排模型通常用于在初步排序或筛选后,对结果进行进一步的精细排序, 这类模型的作用的是对于结果进行重新排列,提高回答的准确率. - 例如,在搜索引擎中,重排模型可能会根据用户的点击行为或反馈来调整搜索结果的顺序。
- audioSpeechModels(音频语音模型): 音频语音模型专注于处理和分析音频数据,尤其是语音。这些模型可以用于语音识别、语音合成、情感分析等任务。
- **whisperModel(音频处理模型) **: 用于执行如语音识别、音频分类或语音到文本的转换等任务。
环境准备
Docker
FastGpt的部署,极大的进行依赖Docker环境,所以需要在你的本地,获取的服务器进行安装Docker环境.Linux进行部署Docker的环境可以进行参考我这篇博客,Windows和MacOS可参看这个官方文档.
- Linux :
- Windows和MacOs : Docker Compose 快速部署 | FastGPT
部署FastGpt和OneApi
1.下载配置文件
# 下载config.json文件
wget https://gitee.com/sigmend/FastGPT/raw/main/projects/app/data/config.json -o config.json
# 下载docker-compose.yml
wget https://gitee.com/sigmend/FastGPT/raw/main/files/deploy/fastgpt/docker-compose.yml -o docker-compose.yml
2. 启动容器
在 docker-compose.yml 同级目录下执行。请确保
docker-compose
版本最好在2.17以上,否则可能无法执行自动化命令。
# 启动容器docker-compose up -d# 等待10s,OneAPI第一次总是要重启几次才能连上Mysqlsleep10# 重启一次oneapi(由于OneAPI的默认Key有点问题,不重启的话会提示找不到渠道,临时手动重启一次解决,等待作者修复)docker restart oneapi
3. 访问OneAPI
可以通过
ip:3001
访问OneAPI,默认账号为
root
密码为
123456
。本地访问: http://localhost:3001.
4. 访问 FastGPT
目前可以通过
ip:3000
直接访问(注意防火墙)。登录用户名为
root
,密码为
docker-compose.yml
环境变量里设置的
DEFAULT_ROOT_PSW
。
如果需要域名访问,请自行安装并配置 Nginx。本地访问: http://localhost:3000
首次运行,会自动初始化 root 用户,密码为
1234
(与环境变量中的
DEFAULT_ROOT_PSW
一致),日志里会提示一次
MongoServerError: Unable to read from a snapshot due to pending collection catalog changes;
可忽略。
通过api-key进行部署训练
因为fastgpt已经内置的进行调用的chatgpt的api所以我另外做一个模型.
使用qwen-turbo模型
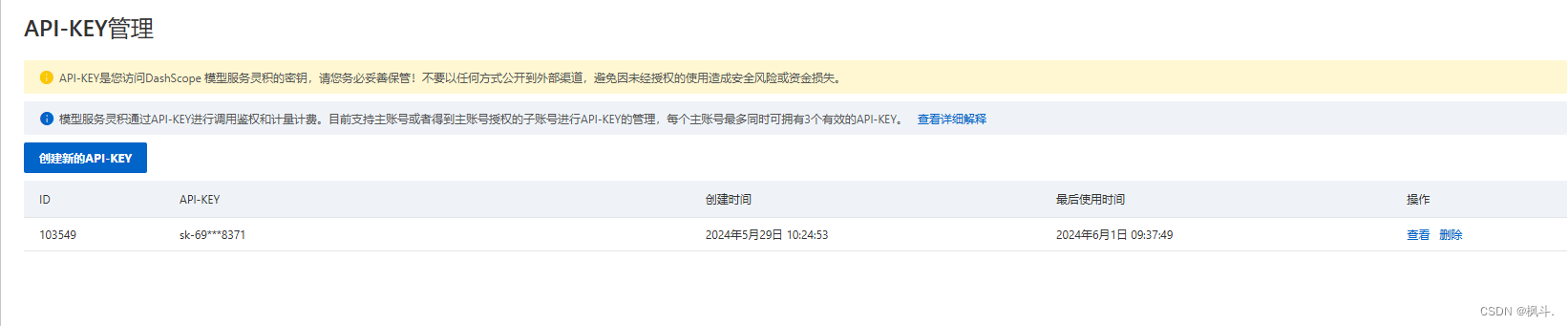
1.获取api-key
- 模型服务灵积-API-KEY管理 (aliyun.com),创建获取一个key进行保存后续进行使用.
2.oneApi添加渠道
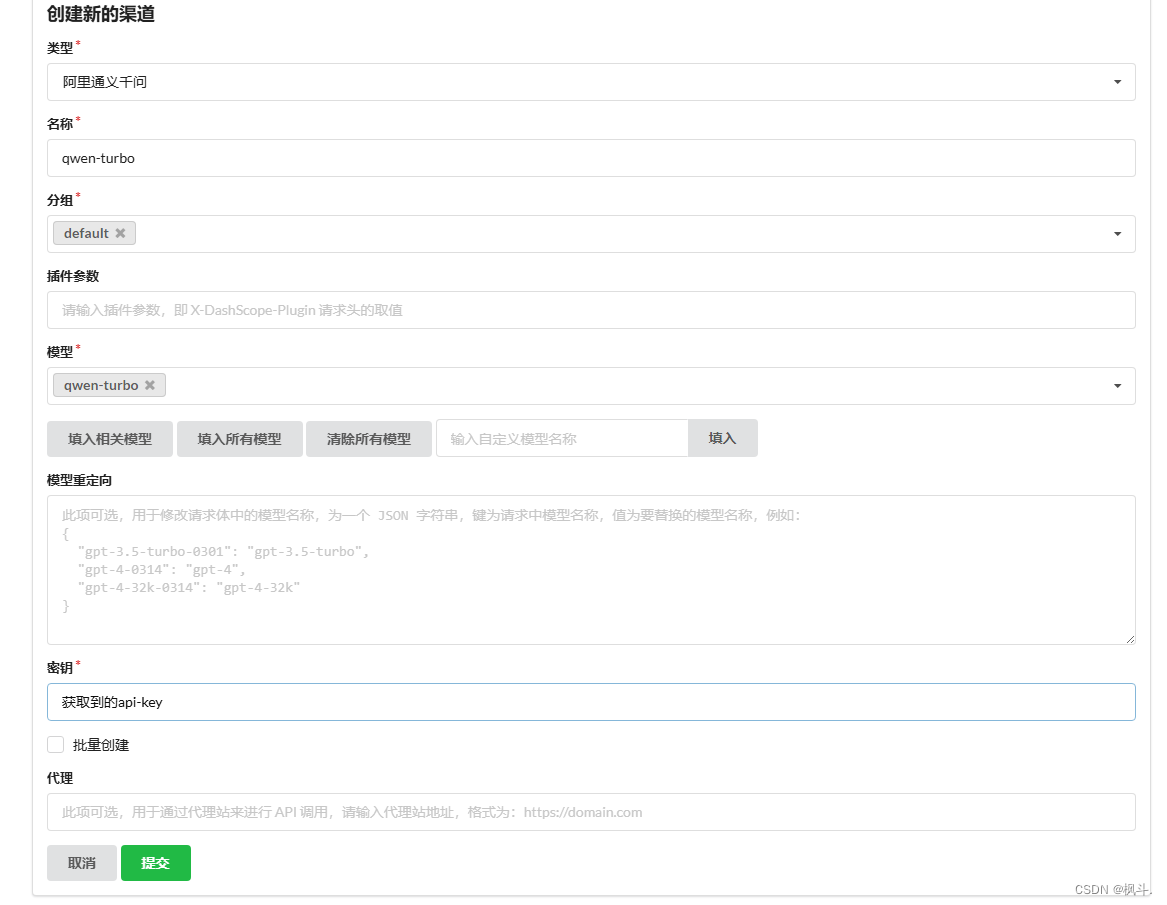
说明: 这个语言模型,在在外面进行测试是能够进行通过的,但是如果是其他的模型,是无法进行通过的但是,不用在意显示的错误没有联通.
3.修改config.js文件
把刚刚进行在oneApi进行添加的模型渠道进行添加到配置文件的ImlModule中.
"llmModels":[{"model":"qwen-turbo","name":"通义千问chat","avatar":"/imgs/model/qwen.svg","maxContext":128000,"maxResponse":4000,"quoteMaxToken":100000,"maxTemperature":1.2,"charsPointsPrice":0,"censor":false,"vision":true,"datasetProcess":true,"usedInClassify":true,"usedInExtractFields":true,"usedInToolCall":true,"usedInQueryExtension":true,"toolChoice":true,"functionCall":true,"customCQPrompt":"","customExtractPrompt":"","defaultSystemChatPrompt":"","defaultConfig":{}}]
参数说明查看: 配置文件介绍 | FastGPT.
4.进行重启docker
docker compose down
docker compose up -d
5.fastgpt进行使用qwen-turbo
- 应用 - -> 创建引用
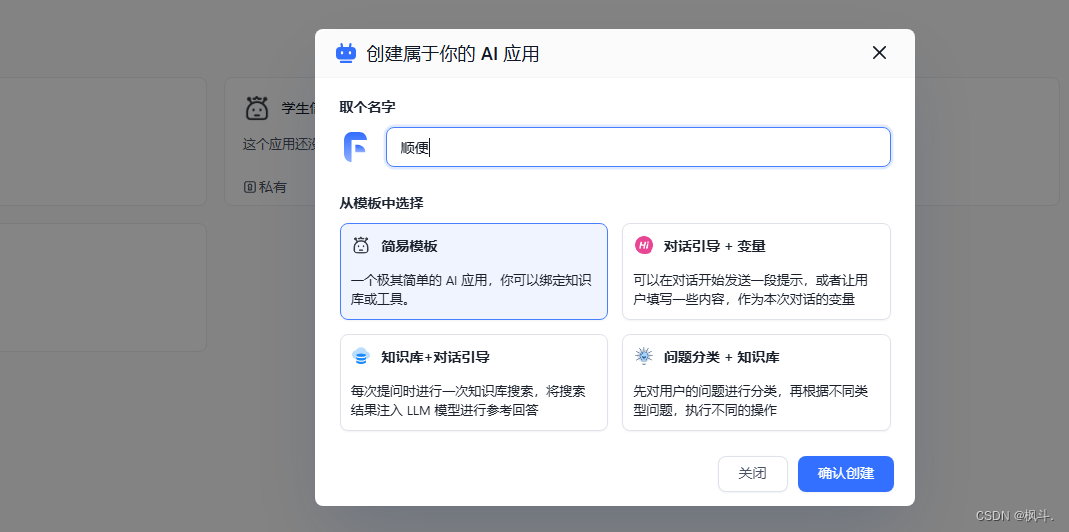
- 选择刚刚创建的模型,我这里设置的是 通义千问chat和config.json配置的名字相同
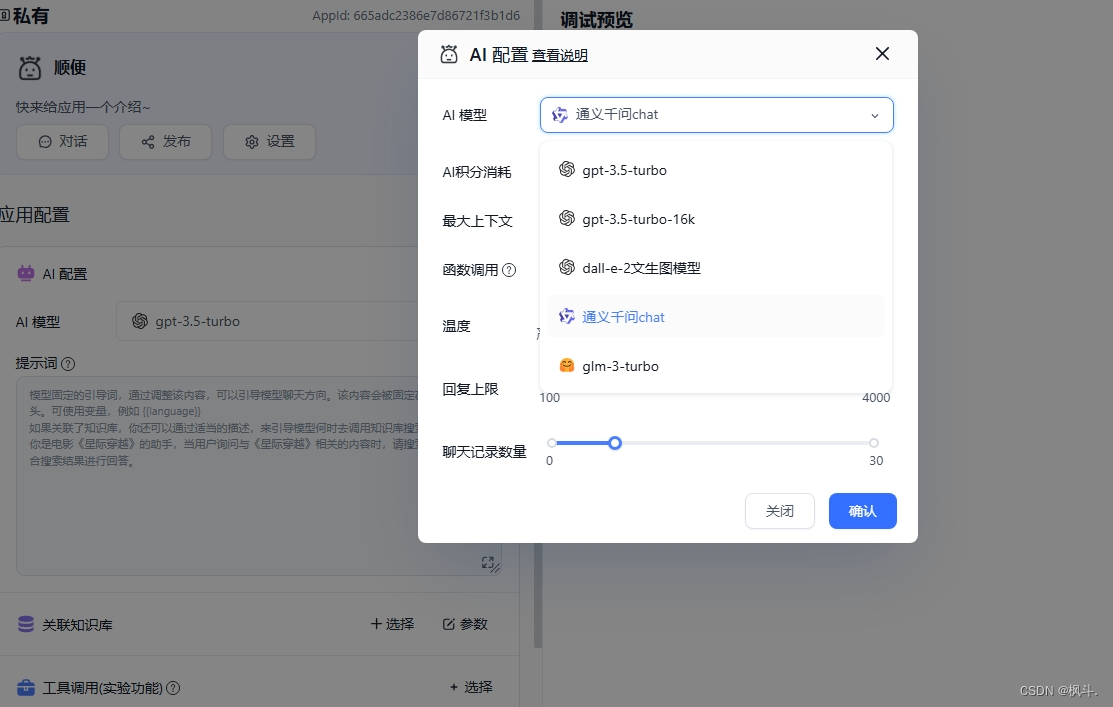
- 点击发布开始聊天
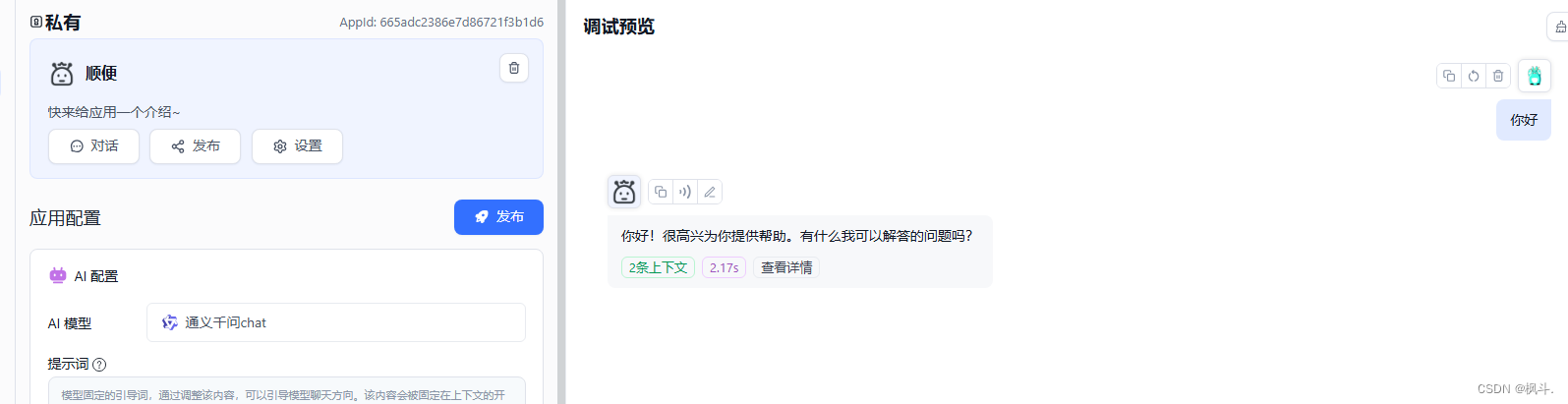
至此就基本的部署完成了一个大语言模型,进行聊天.
部署m3e向量索引模型搭建个人知识库
1.拉取镜像m3e镜像
docker pull registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api:latest
2.启动m3e的镜像
docker run -p6100:6008 -d registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api
3.接入 One API
添加一个渠道,参数如下:密钥默认设置为: sk-aaabbbcccdddeeefffggghhhiiijjjkkk,
- Base URl: 本机的id地址:端口号
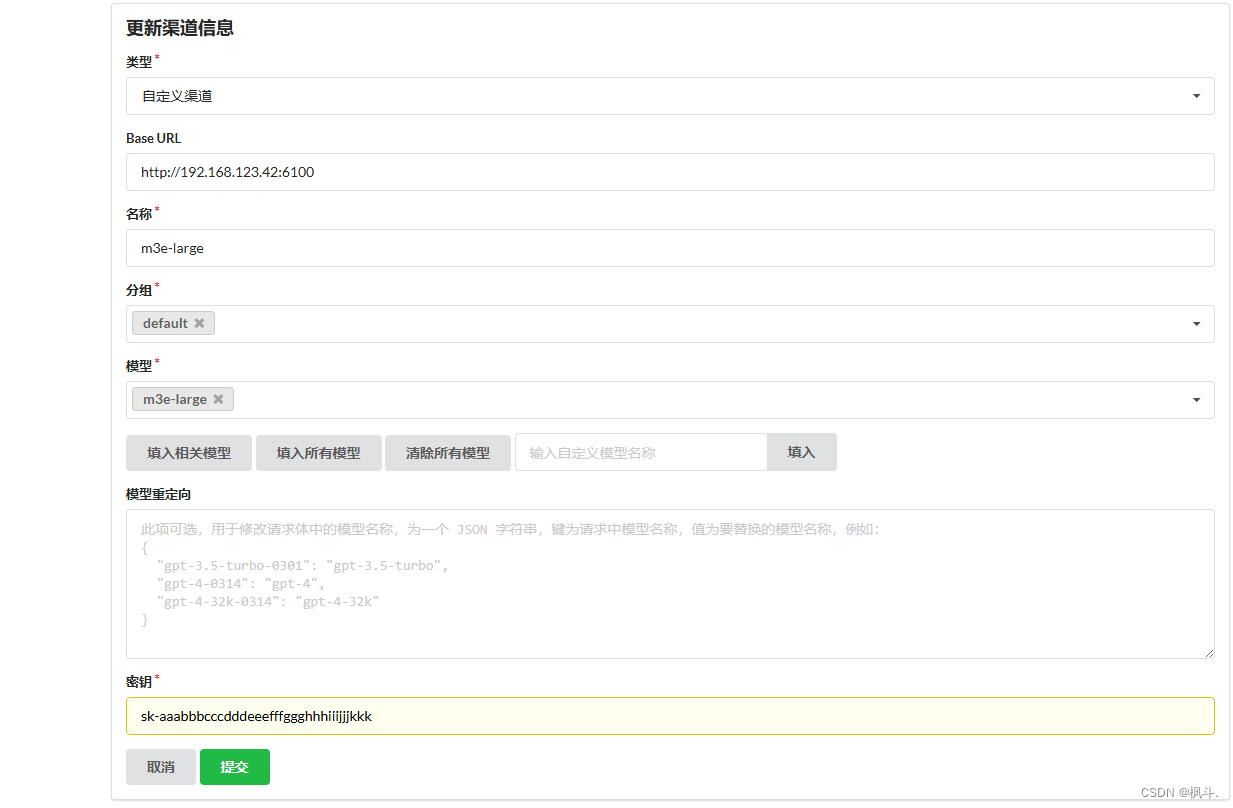
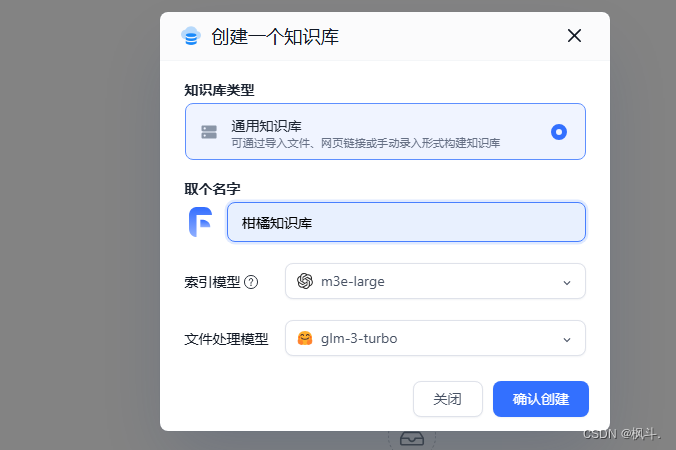
4.Fast创建个人知识库
我这里以训练一个柑橘的个人知识库为例进行训练.文件处理模型,选择前面进行部署的qwen-turbo模型即可,索引模型选择m3e.
5.导入文本数据集
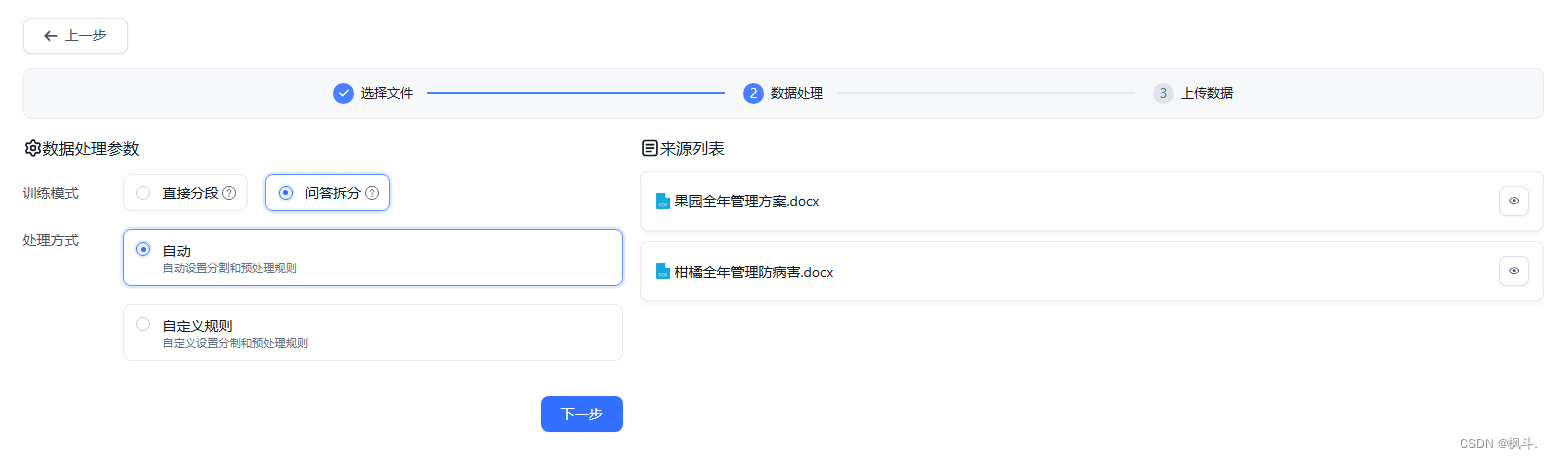
后续上传数据等待,索引完成即可.
6.创建个人ai助理
应用点击创建个人知识库,进行关联柑橘知识库
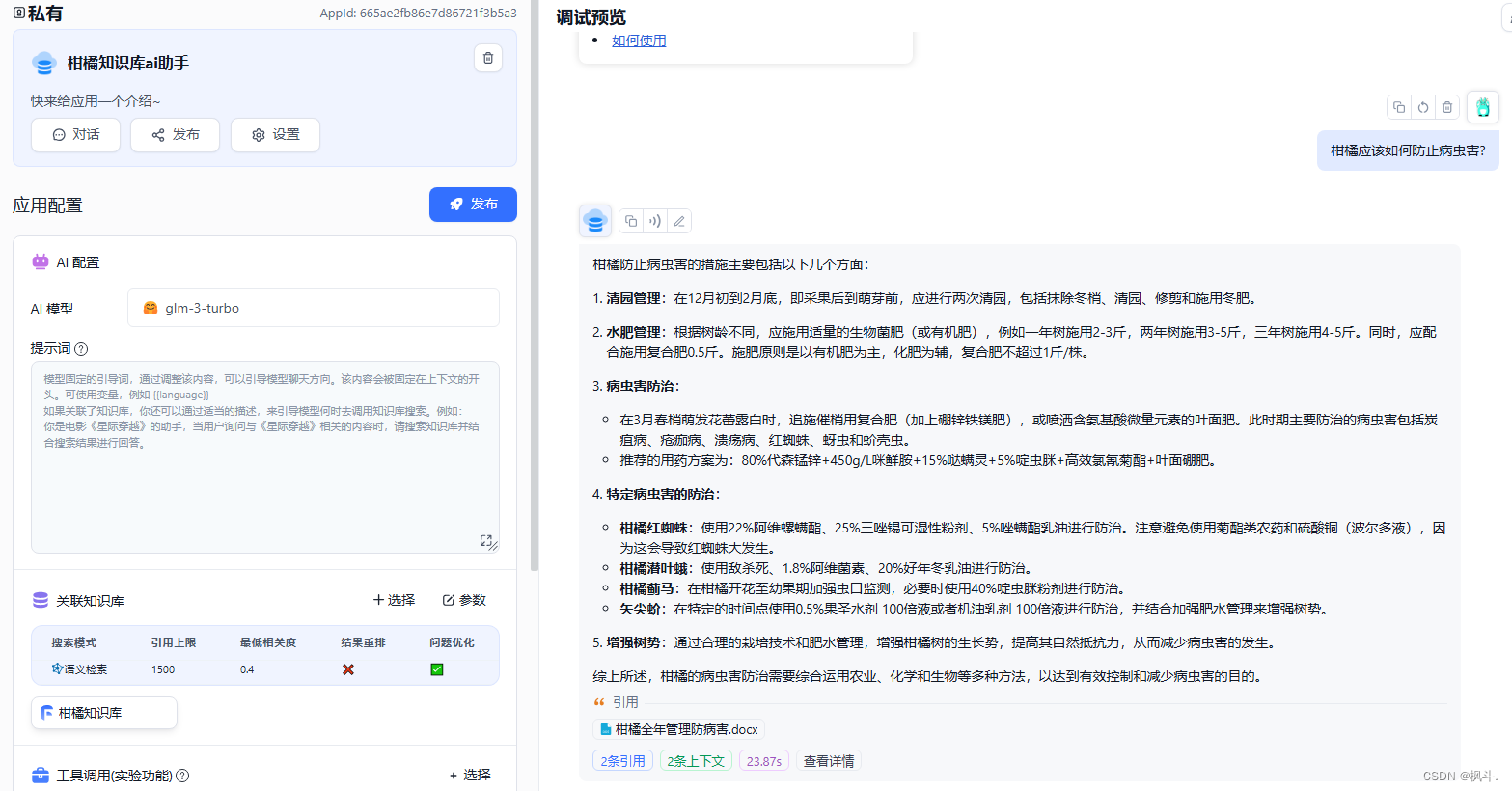
注意: 记得点击发布以后再进行提问哦!
版权归原作者 枫斗. 所有, 如有侵权,请联系我们删除。