利用傅里叶变换实现时序数据的解耦
为了更详细地说明如何利用傅里叶变换来解耦时序数据,我们可以通过一个具体的例子来解释整个过程,包括如何提取趋势、周期性成分和噪声。假设我们有一组时序数据,表示某个地区的每日温度变化。在进行傅里叶变换之前,需要对数据进行一些预处理工作。例如,去除数据中的长期趋势成分。可以使用移动平均或多项式拟合等方法来
sheng的学习笔记-AI-规则学习(rule learning)
机器学习中的“规则”(rule)通常是指语义明确、能描述数据分布所隐含的客观规律或领域概念、可写成“若……,则……”形式的逻辑规则。“规则学习”(rule learning)是从训练数据中学习出一组能用于对未见示例进行判别的规则。一条规则形如:在数理逻辑中“文字”专指原子公式(atom)及其否定。
人工智能两个要素:机器学习算法+大数据
大数据是用于训练AI的,也就是AI算法通过大量的数据去学习AI中算法的参数与配置,使得AI的预测结果与实际的情况越吻合。用于AI的数据越多,AI的算法能力越强。比如要训练AI的识别手写数字的能力,必须要有很多写了数字的图片,同时每张图片上的数字是有准确标准答案的。这个要素应该是最重要的,没有算法的支
四种处理器(CPU、GPU、TPU、DCU)
具有高速的内存带宽和大容量的存储器,以支持大规模的模型和数据。概念:是一种专门在个人电脑、工作站、游戏机、移动设备(平板电脑、智能手机)上图像运算工作的微处理器。用途:用于高效地执行人工智能和机器学习任务、用于图像识别、语音识别、自然语言处理、云计算平台等服务。用途:广泛应用于游戏、视频编辑、科学计
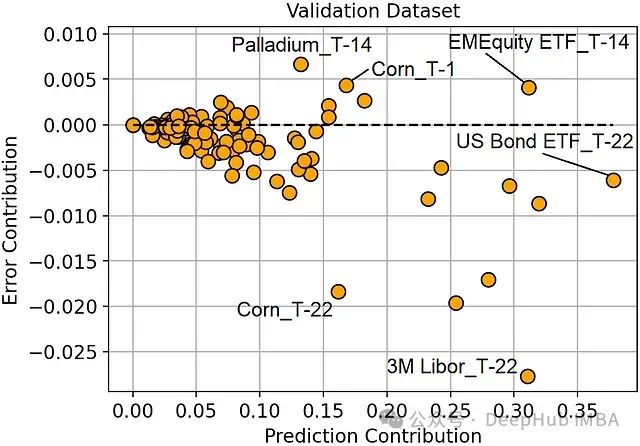
机器学习模型中特征贡献度分析:预测贡献与错误贡献
本文将探讨特征重要性与特征有效性之间的关系,并引入两个关键概念:预测贡献度和错误贡献度。
AI数字人硅基数字人模型训练模型网络结构和训练代码
AI数字人实时数字人硅基数字人模型推理代码和模型网络结构
Datawhale X 李宏毅苹果书 AI夏令营
阅读李宏毅老师苹果书及搭配视频的一次记录
足球比赛是否存在预测法?AI+泊松分布足球预测方法详解
综上所述,AI与泊松分布的结合已经成为了如今足球预测的“通解”,也是目前潜力较大的预测方案,随着AI技术的不断提升,以及开发者对于AI的深入利用,AI不仅会与泊松分布融合,还将与蒙特卡洛、贝叶斯、ELO等个项技术相互结合促进,得以让足球预测的命中率更进一步。示例系统提取码:91r7。
AI:285-YOLOv8改进深度解析 | DynamicHead检测头的原论文复现与性能评估
DynamicHead是YOLOv8中一个重要的改进组件,主要用于提高检测头的灵活性和适应性。该改进通过动态调整卷积核和特征图,从而更好地适应不同大小和形状的目标物体。DynamicHead的核心思想是根据输入图像的特征自适应地调整检测头的参数,以提高检测性能。
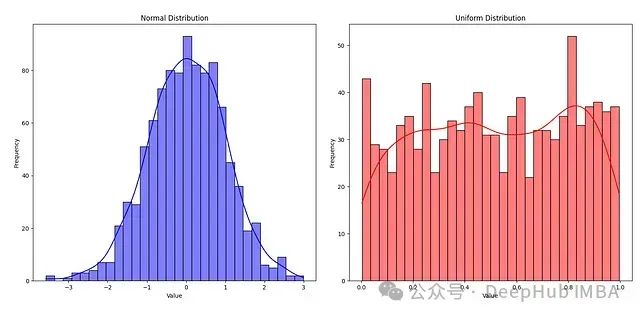
概率分布深度解析:PMF、PDF和CDF的技术指南
本文将深入探讨概率分布,详细阐述概率质量函数(PMF)、概率密度函数(PDF)和累积分布函数(CDF)这些核心概念,并通过实际示例进行说明。
【AI大模型】ChatGPT模型原理介绍(下)
2020年5月, OpenAI发布了GPT-3, 同时发表了论文“Language Models are Few-Shot Learner”《小样本学习者的语言模型》.通过论文题目可以看出:GPT-3 不再去追求那种极致的不需要任何样本就可以表现很好的模型,而是考虑像人类的学习方式那样,仅仅使用极少
吴恩达机器学习 第三课 week3 强化学习(月球着陆器自动着陆)
Coursera课程 吴恩达机器学习 第3课 :无监督学习、推荐算法和强化学习
Kaggle竞赛——手写数字识别(Digit Recognizer)
竞赛使用的是 MNIST (Modified National Institute of Standards and Technology, 美国国家标准与技术研究院修改版) 手写图像数据集,其中训练集42000条,测试集28000条,每条数据有784 个像素点,即原始图像的像素为 28 * 28。
如何预测足球比赛的胜平负进球数?也许我们可以这么做
预测足球比赛的进球数是一个复杂的任务,涉及到多种统计和机器学习方法。从泊松回归模型到Elo评分系统,再到蒙特卡罗模拟和现代的机器学习技术,每种方法都有其独特的优点和局限性。为了提高预测的准确性,在实际应用中,为了便利性,我们应当以AI技术为基底,整合并串联各项技术算法,以此确保系统的预测命中率,同时
人工智能、机器学习和深度学习有什么区别?应用领域有哪些?
人工智能、机器学习和深度学习有什么区别?应用领域有哪些?
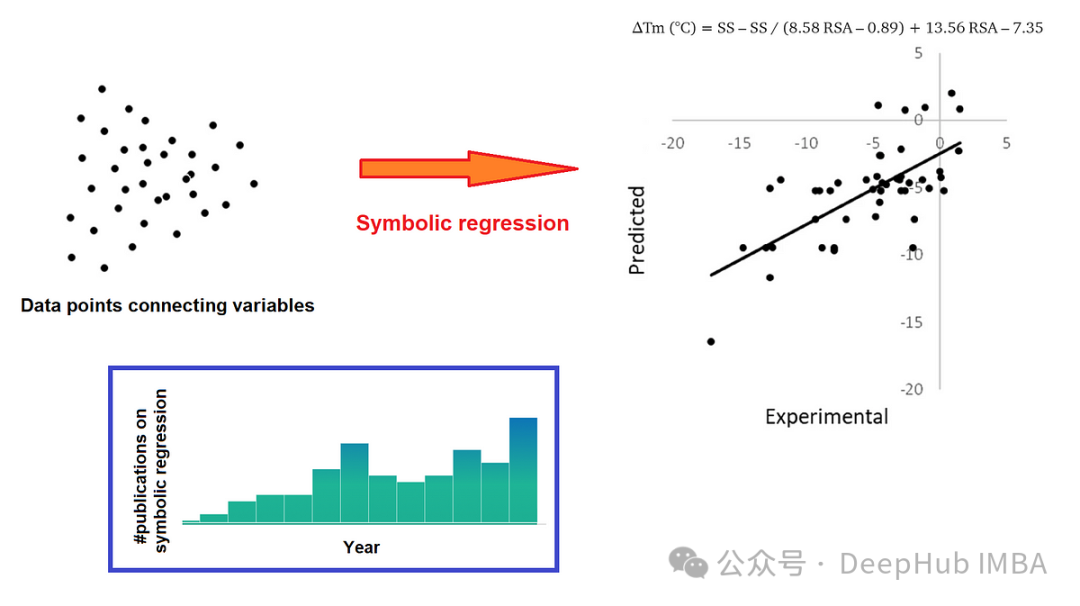
数据稀缺条件下的时间序列微分:符号回归(Symbolic Regression)方法介绍与Python示例
有多种方法可以处理时间序列数据中的噪声。本文将介绍一种在我们的研究项目中表现良好的方法,特别适用于时间序列概况中数据点较少的情况。
OpenAI O1:人工智能推理能力的新里程碑
例如,在国际数学奥林匹克的选拔考试(AIME)中,O1模型的正确率达到了74%至93%,远超GPT-4o模型的12%。首先,O1模型的使用价格非常昂贵,尤其是O1-preview版,其输入和输出token的价格分别是GPT-4o的3倍和4倍。此外,在某些情况下,O1模型的推理速度较慢,需要更长的时间
Splitwise:使用相位分裂实现高效生成式 LLM 推理
24年5月来自华盛顿大学和微软的论文“Splitwise: Efficient Generative LLM Inference Using Phase Splitting”。
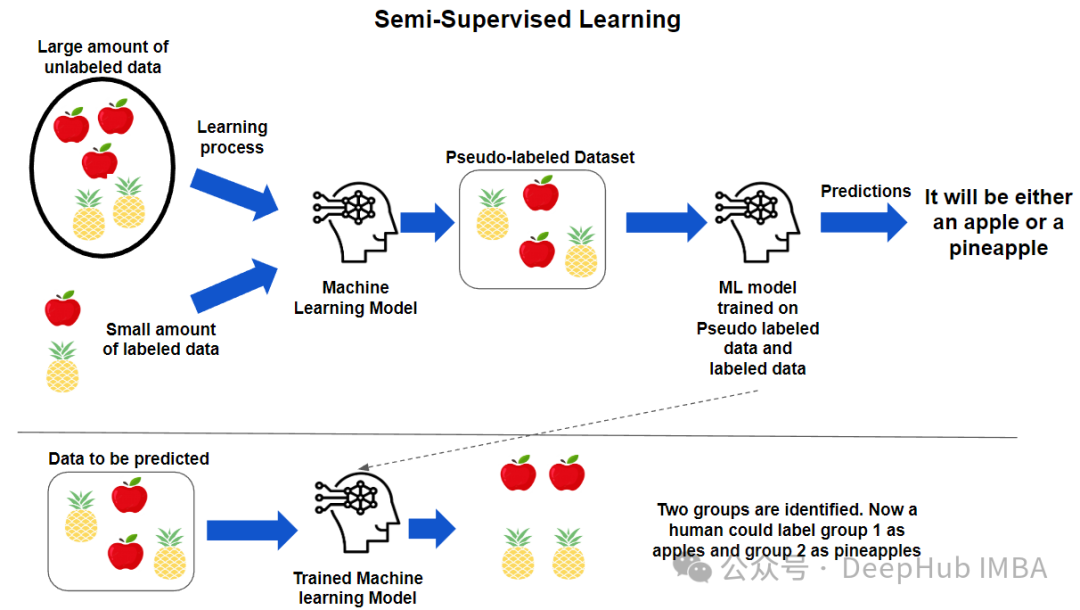
利用未标记数据的半监督学习在模型训练中的效果评估
本文将介绍三种适用于不同类型数据和任务的半监督学习方法。我们还将在一个实际数据集上评估这些方法的性能,并与仅使用标记数据的基准进行比较。
【人工智能】Transformers之Pipeline(十八):文本生成(text-generation)
本文对transformers之pipeline的文本生成(text-generation)从概述、技术原理、pipeline参数、pipeline实战、模型排名等方面进行介绍,读者可以基于pipeline使用文中的2行代码极简的使用NLP中的文本生成(text-generation)模型。



