AI大模型的使用-让AI帮你写单元测试
通过利用AI大模型的生成能力和自然语言处理技术,可以自动化地编写和执行单元测试。这不仅能提高测试效率和代码质量,还能解放开发人员的生产力,让他们专注于更复杂的任务。本文将介绍如何使用AI大模型来编写单元测试,以及这种方法的优势和局限性。
AI+新能源充电桩数据集
7+细分充电桩数据集;新能源充电桩;充电站负荷预测
大数据 | 实验四:并行化数据挖掘算法设计
k近邻法(k-nearest neighbor,k-NN)是一种基本的分类和回归方法,是监督学习方法里的一种常用方法。
【python】在【机器学习】与【数据挖掘】中的应用:从基础到【AI大模型】
Python在数据挖掘和机器学习中的应用,涵盖了数据预处理、特征工程、监督学习、非监督学习和深度学习。
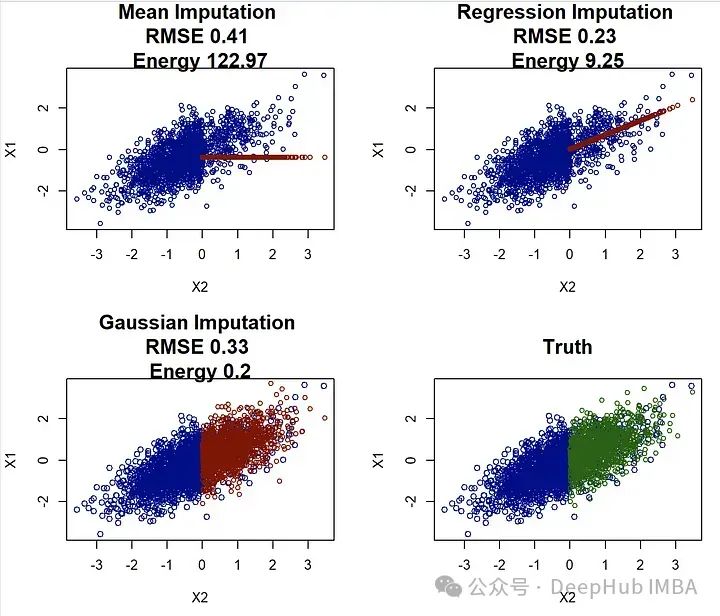
如何应对缺失值带来的分布变化?探索填充缺失值的最佳插补算法
本文将探讨了缺失值插补的不同方法,并比较了它们在复原数据真实分布方面的效果,处理插补是一个不确定性的问题,尤其是在样本量较小或数据复杂性高时的挑战,应选择能够适应数据分布变化并准确插补缺失值的方法。
大数据—数据分析概论
数据分析是指使用统计、数学、计算机科学和其他技术手段对数据进行清洗、转换、建模和解释的过程,以提取有用的信息、发现规律、支持决策和解决问题。数据分析可以应用于各种领域,包括商业、医学、工程、社会科学等。确定问题:明确要解决的问题或要回答的业务问题。设定目标:定义分析的具体目标和期望的结果,如提高销售
人工智能课程设计毕业设计——基于机器学习的贷款违约预测
另外LightGBM通过使用基于直方图的决策树算法,只保存特征离散化之后的值,代替XGBoost使用exact算法中使用的预排序算法(预排序算法既要保存原始特征的值,也要保存这个值所处的顺序索引),减少了内存的使用,并加速的模型的训练速度。Adaboost是一种迭代算法,其核心思想是针对同一个训练集
工具系列:PandasAI介绍_快速入门
所做的类似(10分钟入门pandas -> https://pandas.pydata.org/docs/user_guide/10min.html),我们希望创建最简单的方式来学习如何掌握PandasAI。由于PandasAI由LLM提供支持,您应该导入您想要用于您的用例的LLM。有时候,您可能希
hadoop学习---基于Hive的教育平台数据仓库分析案例(一)
基于hive的数据仓库搭建项目,主题是关于在线教育平台数据仓库搭建。
PySpark数据分析基础:PySpark基础功能及DataFrame操作基础语法详解_pyspark rdd(2)
这里的批处理引擎是Spark Core,也就是把Spark Streaming的输入数据按照batch size(如1秒)分成一段一段的数据(Discretized Stream),每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset),然后将Spark
数据仓库和数据挖掘基础
主要介绍数据仓库和数据挖掘的基本知识。
人工智能|机器学习——Canopy聚类算法(密度聚类)
Canopy聚类算法是一个将对象分组到类的简单、快速、精确地方法。每个对象用多维特征空间里的一个点来表示。这个算法使用一个快速近似距离度量和两个距离阈值T1 > T2 处理。Canopy聚类很少单独使用, 一般是作为k-means前不知道要指定k为何值的时候,用Canopy聚类来判断k的取值。
基于大数据的全国热门景点数据可视化分析系统
本文将介绍如何使用Python中的Pandas库进行数据挖掘,并结合Flask Web框架实现一个旅游景点数据分析系统。该系统将包括以下功能模块:热门景点概况、景点星级与评分分析、景点价格分析、景点客流量销量分析以及景点地理空间分析。通过对数据的深入挖掘和可视化展示(包括柱状图、散点图、箱型图和地图
数据仓库作业六:第9章 分类规则挖掘
数据仓库与数据挖掘第九章作业。
第八章 MobileNetv3网络详解
本文介绍了基于互补的搜索技术和新颖的架构设计的MobileNets的下一代。MobileNetV3通过硬件感知网络架构搜索(NAS)和NetAdapt算法相结合,针对移动电话CPU进行优化,随后通过新颖的架构改进技术进行了进一步提高。本文开始探索自动化搜索算法和网络设计如何相互协作,以利用互补的方法
数据仓库实验三:分类规则挖掘实验
数据仓库与数据挖掘实验三:分类规则挖掘实验。
数据仓库实验四:聚类分析实验
数据仓库与数据挖掘实验四:聚类分析实验。
AI 内容分享(十三):商品分类:AI落地实践
基于真实需求,让AI落地,使用embedding模型做大数据量分类。为数十万商品分类通常想到的办法是用NLP+特定分类算法(如是SVM)来实现,涉及数据清洗,特征提取,模型训练,调试和集成等工作。看起来是项大工程。借助现有AI的能力,可以加速实现。本文是基于真实需求场景的探索和回顾。
kaggle最全基础入门(大数据)
Kaggle是一个数据科学竞赛平台,旨在连接数据科学家和机器学习工程师,提供一个共同解决实际问题的平台。Kaggle的任务通常由公司、学术机构、政府机构等提交,这些任务涵盖了各种问题领域,例如自然语言处理、计算机视觉、数据挖掘等。竞赛参与者可以下载数据集、提交代码和模型,并与其他参赛者交流和竞争。K
淘宝电商用户行为数据分析及可视化-基于MySQL/Tableau
关注活动前后指标数据,优化推荐策略和搜索功能新增用户的数据不够理想,应观察各渠道的用户获取情况,以及竞争平台近期是否在举行促销活动。用户的活跃度应该结合平台的活动时段分析,考察是否符合预设目标值,同比环比等。本篇分析发现周末晚间20点-22点是用户活跃高峰期,应针对高峰期进行有效的营销活动,从而更容



