
目录
一、实验目的
通过本实验,进一步理解决策树算法、朴素贝叶斯算法进行分类的原理,并掌握利用Sql Server等工具平台进行分类规则挖掘的方法,掌握挖掘结构、挖掘模型的基本概念,能够使用数据挖掘向导创建数据挖掘结构和模型,掌握数据挖掘设计器的使用方法,掌握模型查看器方法 ,理解分类规则挖掘常用的参数含义和设置方法。
二、实验内容和要求
针对实际需求,构建格式规范的数据集,并能够借助于SQL Server、Weka、SPSS等工具平台,利用决策树(Decision tree)算法、朴素贝叶斯(Naïve Bayes)算法进行分类和预测,正确分析实验结果,完成实验报告。
三、实验步骤
以下以SQL Server作为工具,完成数据集的构建和分类规则的挖掘(利用决策树分类、朴素贝叶斯分类算法)。——以下内容,仅供参考!
1、创建数据库和表
在SSMS中建立DM数据库(模拟不同群体、不同收入、不同信誉的人群是否购买计算机的事实),分别设计DST表(用于建立分类模型的事例表)、DST1表(用于预测的事例表)。DST表的结构和内容如下所示。



DST1表的结构和DST表相同,被用于预测/验证,DST1的内容如下:

DST1有3条记录,其中“是否购买计算机”列为空,待预测后确定。
2、决策树分类规则挖掘
在 Sql Server Business Intelligence Development Studio (BIDS) 采用如下步骤,基于决策树挖掘分类规则。

(1)新建一个 Analysis Services 项目 jueceshu
定义数据源DM.ds,对应的数据库为前面建立的DM数据库。

(2)建立数据源视图
定义数据源视图DM.dsv,它包含DST表,用于基于决策树建立分类模型;
定义数据源视图DM1.dsv,它包含DST1表,基于建立的决策树分类模型进行预测。
数据源视图DM.dsv:

数据源视图DM1.dsv:

(3)建立挖掘结构 DST.dmm
新建挖掘结构,在“创建数据挖掘结构”页面的“您要使用何种数据挖掘技术?”选项下,选中列表中的“Microsoft决策树”。

选择数据源视图为DM。
在“指定表类型”页面上,在DST表的对应行中选中“事例”复选框,并单击下一步按钮。

在“指定定型数据”页面中,将“编号”列设为键列,把“是否购买计算机”设为可预测列,把其它所有列设为输入列。

在“创建测试集”页面上,“测试数据百分比”选项的默认值为30%,将该选项更改为0.

在完成向导页面的“挖掘结构名称”和“挖掘模型名称”中,都输入DST。

单击“挖掘模型”选项卡,右击“Microsoft_Decision_Trees”选项,在出现的快捷菜单中选择“设置算法参数”命令。将COMPLEXITY_PENALTY,MINIMUM_SUPPORT,SCORE_METHOD,SPLIT_METHOD等参数值进行适当设置。



(4)部署决策树挖掘项目并浏览结果
先处理(部署)、再浏览。

在挖掘模型查看器中,浏览决策树分类的结果。

上面已经建立了决策树分类模型。接下来,就可以利用这个分类模型,对DST1表中3个数据样本的“是否购买计算机”列的值进行预测,步骤如下:
① 单击“挖掘模型预测”选项卡,再单击“选择输入表”对话框中的“选择事例表”命令,指定DM1数据源视图中的DST1表。

② 保持默认的字段连接关系,将DST1表中的各个列拖放到下方的列表中,选中“是否购买计算机”字段前面的“源”,从下拉列表中选择“DST”选项,而其它字段的数据直接来源于DST1表,只有“是否购买计算机”字段是采用前面训练样本集得到的决策树模型来进行预测的。

③ 在任一空白处右击,并在下拉菜单中选择“结果”,出现如下所示的分类结果。

3、朴素贝叶斯分类规则挖掘
朴素贝叶斯分类的应用,还是基于DM数据库的DST和DST1表,DST用于训练,DST1用于预测,过程此处不再进行描述(预测结果与前面的决策树预测的结果相同),请同学们自行模索。

具体步骤与决策树分类规则挖掘类似:
(1)建立挖掘结构 Bayes.dmm


(2)部署朴素贝叶斯挖掘项目并浏览结果

查看“挖掘模型”:

点击“挖掘模型查看器”:

点击“挖掘模型预测”:

查看预测结果:

预测结果和决策树预测结果相同。
四、实验结果分析
1、决策树
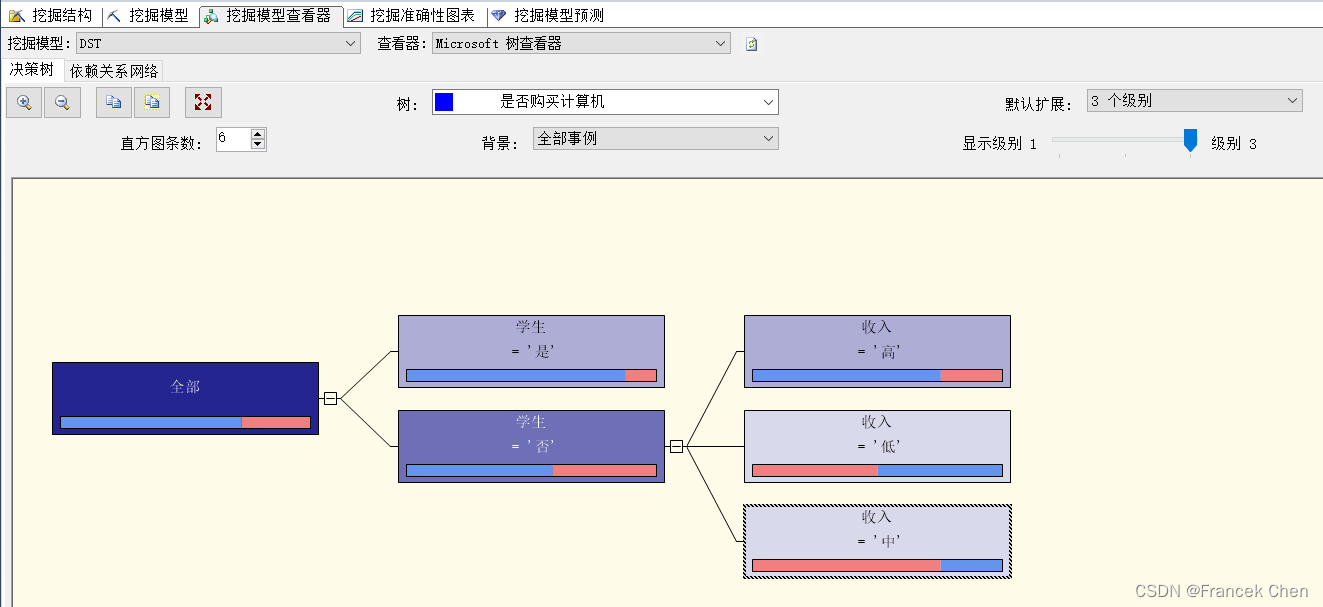
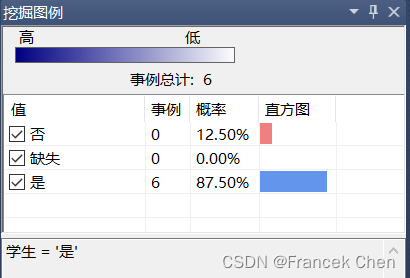
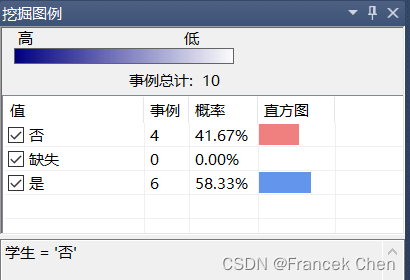
学生中,有87.5%购买计算机;非学生中,58.33%购买计算机。由此可见,学生购买计算机的概率比较大。
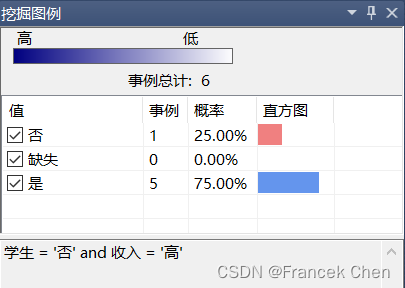
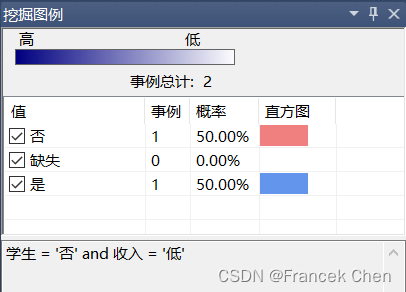
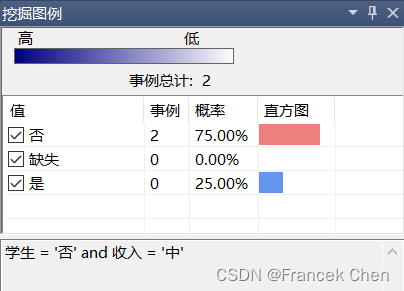
在非学生中,收入“高”的有75%购买计算机;收入“中”的有50%购买计算机;收入“低”的有25%购买计算机。由此可见,收入越高,购买计算机的概率越高。
2、依赖关系网络
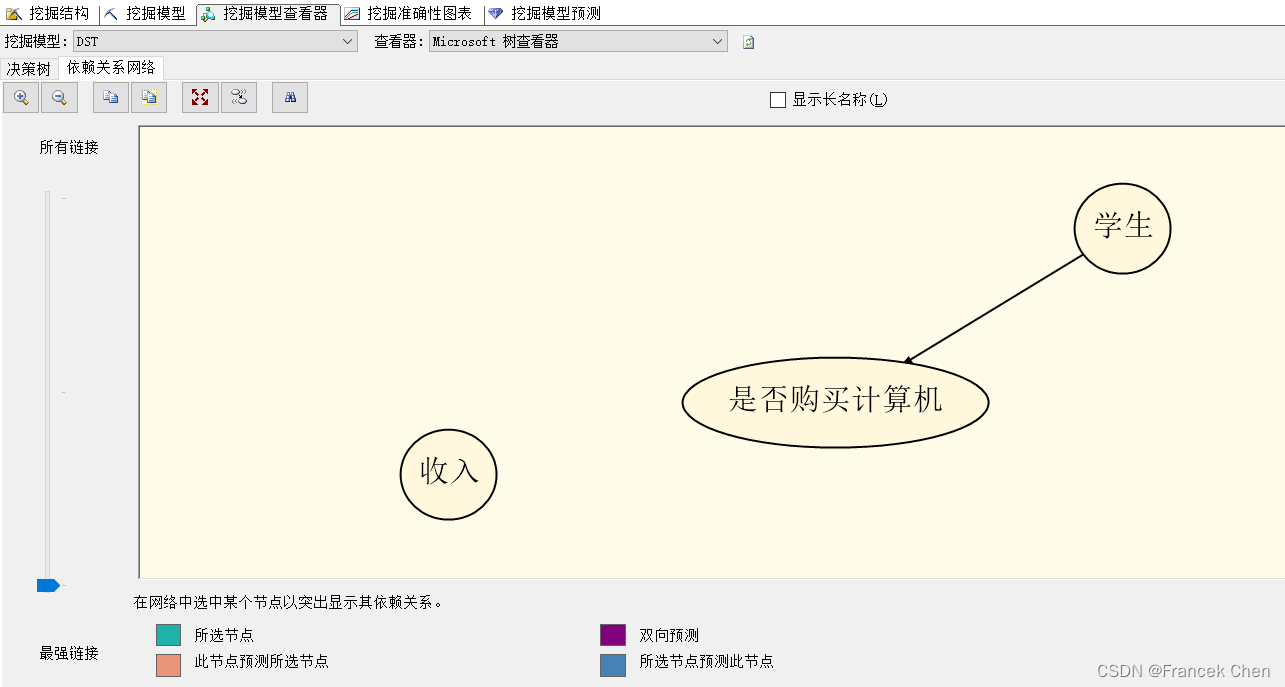
{
\{
{学生
}
\}
}
⇒
\Rightarrow
⇒
{
\{
{是否购买计算机
}
\}
}是强关联规则。
五、实验总结体会
在挖掘数据仓库中的分类规则实验前,需要对数据进行预处理和清洗,确保数据的质量和完整性,数据的完整性和准确性直接影响了挖掘结果的可信度。这包括去除重复值、处理缺失值和异常值等。
选择合适的特征对于挖掘有效规则至关重要。使用特征选择技术来排除不相关或冗余的特征,以及特征提取技术来创建新的、更有信息量的特征。用特征选择算法来确定最相关的特征,以提高分类模型的准确性和效率。根据实验的目标和数据的特点,选择适合的分类模型。常用的分类算法包括决策树、朴素贝叶斯、支持向量机等。可以通过交叉验证等方法来评估模型的性能。
决策树是一种基于树形结构的分类算法,通过对特征进行逐步划分来进行决策。易于理解和解释,可视化效果好。适用于离散型和连续型数据,处理分类和回归问题都有效。对数据的预处理要求相对较低,对异常值和缺失值有一定的鲁棒性。可以处理大规模数据集,对于非线性关系的数据有较好的适应能力。能够输出清晰的规则,便于理解和应用。
朴素贝叶斯是一种基于贝叶斯定理的概率分类算法,假设特征之间相互独立。计算简单,适用于大规模数据集。主要用于文本分类和情感分析等任务,对于高维度数据和稀疏数据表现较好。需要注意处理连续型数据和处理缺失值的方法。训练和预测速度快,对于数据量大、特征维度高的情况下表现优秀。对于噪声数据有一定的鲁棒性。
在实验结束后,需要对分类模型进行评估。常用的评估指标包括准确率、召回率、F1值等。同时,可以使用混淆矩阵来分析分类结果的详细情况。对于实验结果,需要进行解释和分析。可以通过特征重要性分析、规则提取等方法来理解分类模型的决策过程。
版权归原作者 Francek Chen 所有, 如有侵权,请联系我们删除。