大数据产业链图谱_产业链全景图_大数据行业市场分析
大数据产业链上游为基础支持层,包括数据源、数据采集、底层技术、数据安全等环节,中游为数据处理层,包括数据分析、数据挖掘、数据可视化等环节,下游主要为行业应用、解决方案及通用产品。
Probit 回归模型及 Stata 具体操作步骤
在经济学领域,Probit 回归模型常用于研究消费者的购买决策、企业的投资行为以及市场的进入与退出等问题。综上所述,Probit 回归模型在不同学科领域都有着丰富的应用和研究成果,为我们解决实际问题提供了有力的方法支持。然而,随着研究问题的日益复杂和数据类型的多样化,对 Probit 回归模型的创新
回归分析:生存分析与Cox比例风险模型技术教程
生存分析是一种强大的统计工具,用于处理时间到事件的数据,特别是在存在审查数据的情况下。Kaplan-Meier估计提供了生存率的直观估计,Log-Rank检验用于比较不同组的生存曲线,而Cox比例风险模型则用于分析生存时间与多个协变量之间的关系。这些方法在医学、工程和许多其他领域都有广泛的应用。Co
二分类损失 - BCELoss详解
BCELoss (Binary Cross-Entropy Loss) 是用于二分类问题的损失函数。它用于评估预测值和实际标签之间的差异。在 PyTorch 中,BCELoss是一个常用的损失函数。以下是 BCELoss 的详细计算过程和代码实现。
Elasticsearch中磁盘水位线的深度解析
Elasticsearch的磁盘水位线是一种强大的工具,它帮助管理员监控和管理Elasticsearch集群的磁盘使用情况,防止数据丢失和系统性能下降。通过合理配置和使用磁盘水位线,可以确保Elasticsearch集群的稳定性和可靠性。
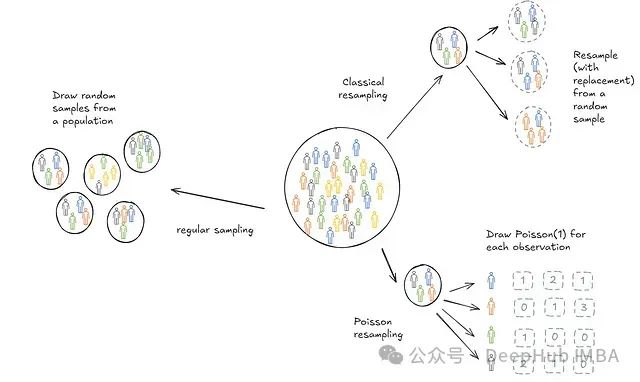
泊松自助法(Poisson Bootstrap Sampling):大型数据集上的自助抽样
泊松自助抽样(Poisson Bootstrap Sampling)是一种用于统计分析中的重采样技术,特别是在机器学习和数据科学中用于模型评估和误差估计。
足球预测:AI技术如何预测比赛结果
综上所述,AI预测能够综合各类算法,并结合数据挖掘、机器学习等应用来预测足球比赛,得出来的预测结果也有着可观的准确度,对AI预测感兴趣的小伙伴,可以扫描下方图片,领取AI预测工具。
云端数据挖掘:释放大数据潜力的智能钥匙
随着大数据时代的到来,数据已经成为企业和组织最宝贵的资源之一。然而,如何有效利用这些数据,挖掘出有价值的信息和洞察,成为了一个挑战。云服务提供了一种灵活、可扩展的解决方案,允许用户在云端进行数据分析和处理。本文将详细介绍如何使用云服务进行数据分析,并提供一些示例代码,以帮助读者更好地理解和应用这一技
Tableau可视化和仪表盘
过程写的很简洁,因为我觉得熟悉软件更重要,复习可以再跟着视频多做几遍,记录下来用处可能不大。
地方招商之变:告别税收引商,产业链招商成新引擎!
8月1日,我国实施《公平竞争审查条例》,标志着地方“税收奖补”式招商引资模式日暮途穷。地方招商引资模式正在向基于数字化基础的“产业链招商”模式转型,产业链招商通过补链强链、供应吸附、资源共聚等方式能够有效提高招商质量和效率,促进产业集群,降低产业风险,帮助区域提升产业链水平、完整度和竞争力,保障和促
揭秘!国内10大低代码构建平台
通过内置的移动设备管理(MDM)功能,Zoho Creator实现了一键式的移动应用部署和分发,使得开发者可以轻松地将应用部署到目标用户的移动设备上,无需通过应用商店。Zoho Creator 提供了一个直观的拖放界面,用户可以通过简单的拖拽操作来设计和构建应用界面,无需编写任何代码,极大地简化了开
【独立站经验分享】独立站品牌运营模式最全解析!全篇干货!
我们也可以。
cuda12.2 linux gpu torch环境记录
显示是12.2的版本,然后去官网查看相对应的安装GPUpytorch的命令。首先,先查看服务器CUDA 版本:nvcc --version。首先在虚拟环境conda安装GPU的pytorch环境,安装以后查看是否成功。
Datawhale AI 夏令营 市场博弈和价格预测 EDA 探索性数据分析
基于挑战赛“市场博弈和价格预测”使用探索性数据分析(EDA)深入理解赛题。
【理论篇】数据挖掘 第四章 数据仓库与联机分析处理
数据仓库是一个面向主题的、集成的、时变的、非易失的数据集合,支持管理者的决策过程”。面向主题的(subject-oriented):数据仓库围绕一些重要主题,如顾客、供应商、产品和销售组织;集成的(integrated):通常,构造数据仓库是将多个异构数据源,如关系数据库、一般文件和联机事务处理记录
建筑业数据挖掘:Scala爬虫在大数据分析中的作用
数据的挖掘和分析对于市场趋势预测、资源配置优化、风险管理等方面具有重要意义,特别是在建筑业这一传统行业中。Scala,作为一种强大的多范式编程语言,提供了丰富的库和框架,使其成为开发高效爬虫的理想选择。本文将探讨Scala爬虫在建筑业大数据分析中的作用,并提供实现代码示例。
大数据环境下的房地产数据分析与预测研究的设计与实现
其中,number_1代表数据总条数,max_2表示最高单价的房屋信息,mean_3为平均单价,max_4为最高总价的房屋信息,index_5和values_5分别为每个区域的平均房屋单价的降序排列的索引和值,index_6和values_6为部分市区的平均总价的索引和值,number_7为单价分区
《数据仓库与数据挖掘》自测
1. 数据仓库的主要特征不包括以下哪一项?A. 数据量大B. 异构数据整合C. 事务处理D. 支持决策分析2. OLAP的核心功能是:A. 事务处理B. 多维数据分析C. 数据清洗D. 数据转换3. 以下哪个不是元数据的分类?A. 数据源元数据B. 数据模型元数据C. 数据仓库映射元数据D. 数据备
Tableau 嵌入网页的用户查看权限设计(后端到前端全流程)
大家好啊,今天想要跟大家聊一下Tableau从后端到前端的用户权限设计。先在这里说一下我的权限设计思路,这个思路也是我之前自己在项目上编写设计文档,写代码开发,在生产环境实际部署并一直使用的。
1.25、最近邻向量量化(LVQ) 网络训练对输入向量进行分类
最近邻向量量化(LVQ)是一种用于对输入向量进行分类的神经网络模型。以下是LVQ的一些关键特点和总结:LVQ利用一组原型向量(参考向量)表示不同的类别,在训练过程中调整原型向量的权重以逼近输入向量。LVQ训练过程中,网络通过计算输入向量与每个原型向量之间的距离,并更新距离最近的原型向量的权重。当LV



