
Pytorch团队提出了一种纯粹通过PyTorch新特性在的自下而上的优化LLM方法,包括:
Torch.compile: PyTorch模型的编译器
GPU量化:通过降低精度操作来加速模型
推测解码:使用一个小的“草稿”模型来加速llm来预测一个大的“目标”模型的输出
张量并行:通过在多个设备上运行模型来加速模型。
我们来看看这些方法的性能比较:
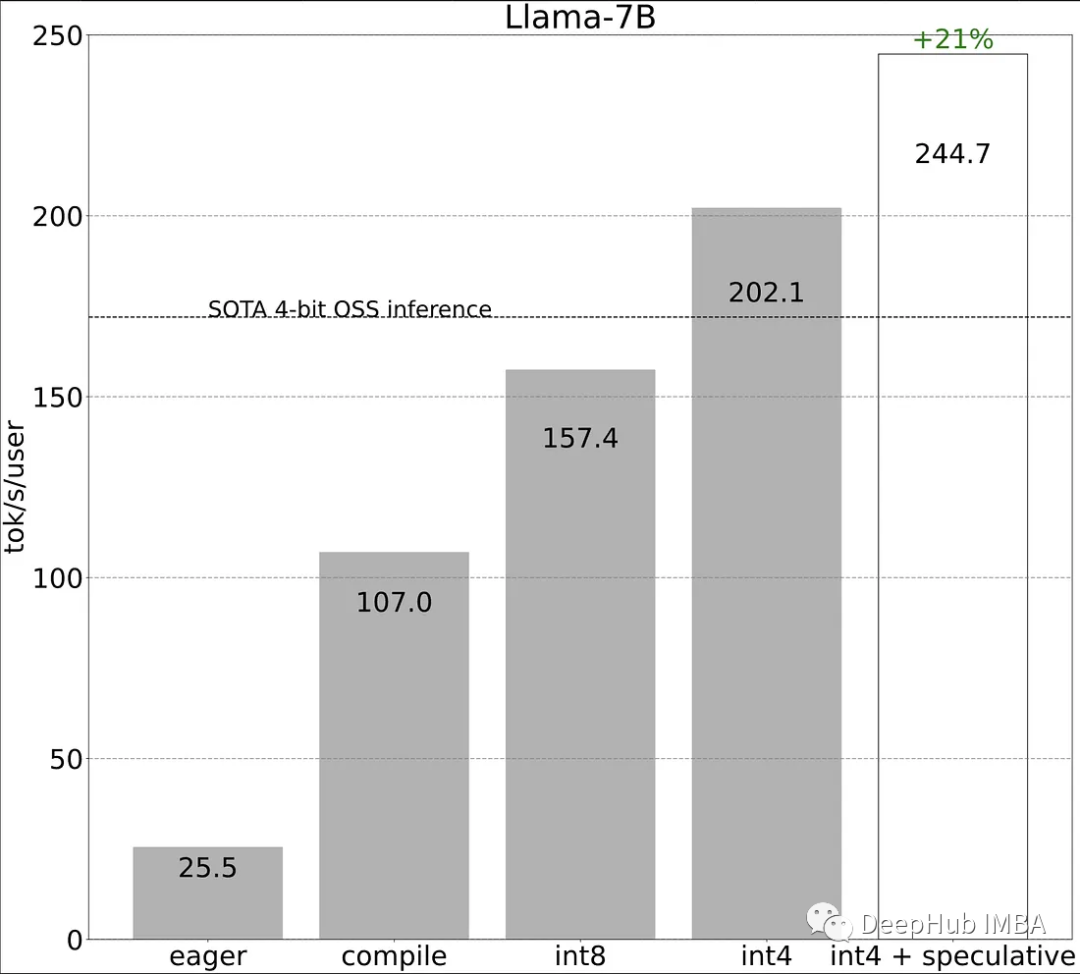
作为对比,传统的方式进行LLaMA-7b的推理性能为25tokens/秒,我们来看看看这些方法对推理性能的提高。
使用新的编译器和分配(76 TOK/S):
Pytorch分析了cpu限制的性能问题。这意味着编译开销是提高效率的首要目标。
所以使用编译器将较大的区域编译为预编译状态,每个操作的CPU调用数量会减少。这意味着该包装器现在可以在没有间隙的情况下执行,如下所示。

代码也非常简单:
torch.compile(decode_one_token, mode="reduce-overhead", fullgraph=True)
当生成更多令牌时,kv-cache会增长,每次缓存增长时都需要重新分配和复制(昂贵的计算)。声明大缓存以允许最大大小。
在预填充阶段需要分别编译两种策略。整个提示被动态处理,令牌被解码为上面所示的代码。保持这些策略并行可以进一步优化。单独使用这两种策略,可以获得3倍的推理性能提高。
消除内存瓶颈,(102 TOK/S)
以静态方式为缓存分配最大内存时,会使内存问题变得更糟,因为我们上面只是让CPU计算更加高效,比如缓存肯定会加大内存的使用。
优化内存的最简单方式就是量化。量化试图将权重和计算转换为Int8甚至Int4——这将矩阵的大小减少了4 - 16倍,从而在矩阵操作期间大量节省内存。
如果有72亿个参数需要处理,每个权重需要2字节(fp16)来保存;我们可以计算每秒生成100个令牌所需的带宽。这意味着,要以每秒100个令牌的速度运行推理,我们需要处理总计1.4TB的内存吞吐量。A100的理论上限为2Tb/s,这意味着使用72%的带宽(没有瓶颈),A100可以轻松地每秒运行100个令牌。这取决于你的GPU,如果你是4090呢,大家可以计算一下,4090具有1008GBPS的内存带宽,基本上就是少了一半还要少一些。
重构问题(157.4 TOK/s)
假设对于要生成的每个新单词,要一次又一次地加载和处理所有标记。在自回归世代中我们不需要序列依赖。我们可以使用草稿模型和验证模型(缓慢但准确)并行生成下8个令牌,作为8个副本来验证生成。与验证器不匹配的草稿模型输出将被丢弃。

根据Pytorch文档,它不会降低生成文本的质量。实验也证明了这一点。当运行codellam - 34b + codellam - 7b时,能够在生成代码时获得2倍的token /s提升。当使用Llama-7B + TinyLlama-1B时,在token /s中获得1.3倍的提升。
Int4 (202 TOK/s)
从浮点数变为Int8可以减少内存带宽,我们可以通过将其降低到Int4来测试极限(最小值为-2147483648)。最大值为2147483647)。考虑到INT的范围仍然从负到正十亿,有足够的细微差别,在获得额外提升推理速度的同时,不会失去太多的准确性。
把上面所有的东西结合起来(240 TOK/s)
当所有上述方法一起使用时,由于不同策略的协同作用,还会带来额外的21%的收益。
总结
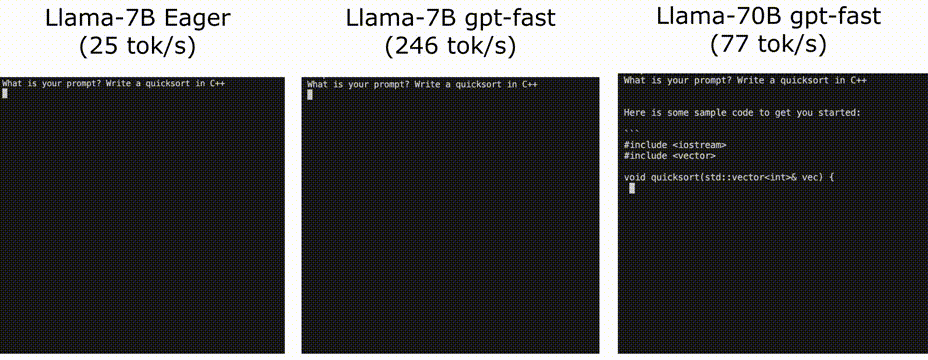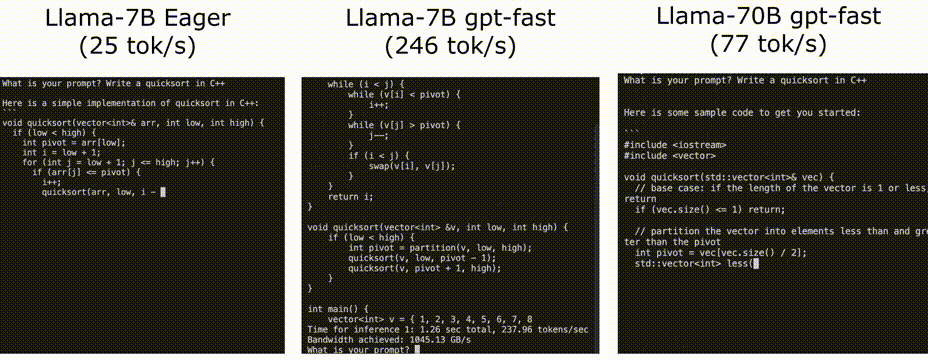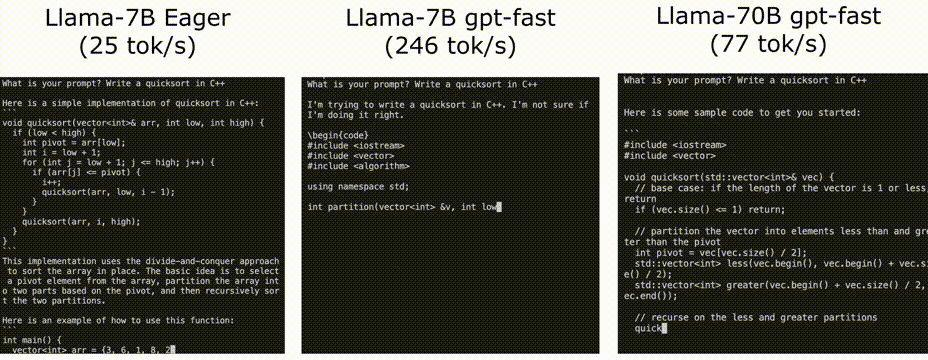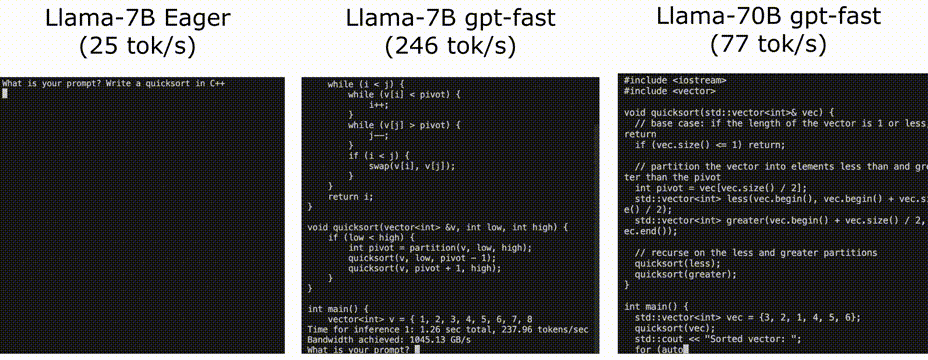
可以看到,我们最终获得了10倍左右的提高 25 TOK/s -》 246 TOK/s
使用Llama-7B,我们能够使用编译+ int4量化+推测解码达到246 tok/s。通过llama-70B,我们还可以将张量并行性提高到80 tok/s。这些都接近或超过SOTA性能数字!
本文代码:
https://github.com/pytorch-labs/gpt-fast
作者:Dr. Mandar Karhade, MD. PhD