
Transformer模型善于捕捉基于内容的全局交互,而cnn则能有效地利用局部特征。在这项工作中,通过研究如何将卷积神经网络和Transformer结合起来,以参数有效的方式对音频序列的局部和全局依赖关系进行建模,从而达到两全面性。
为此,提出了用于语音识别的卷积增强Transformer,命名为Conformer。Conformer显著优于之前的Transformer和基于CNN的模型,达到了最先进的精度。
1. 引言
**基于神经网络的端到端自动语音识别(ASR)**系统近年来取得了很大的进步。递归神经网络(RNN)已经成为ASR的实际选择,因为它们可以有效地模拟音频序列中的时间依赖性。最近,基于自关注的Transformer体系结构由于能够捕获长距离交互和高训练效率,在序列建模中得到了广泛的采用。另外,卷积在ASR中也取得了成功,它通过一层一层的局部接受场逐步捕获局部上下文。
然而,具有自注意力或卷积的模型都有其局限性。虽然Transformer擅长对远程全局上下文进行建模,但它们在提取细粒度的局部特征模式方面能力较差。另一方面,卷积神经网络(CNN)利用局部信息,在视觉中被用作事实上的计算块。它们在一个局部窗口上学习共享的基于位置的核,这些核保持平移等变性,并能够捕获边缘和形状等特征。使用局部连接的一个限制是,需要更多的层或参数来捕获全局信息。为了解决这个问题,当代作品ContextNet[10]在每个残差块中采用挤压激励模块来捕获更长的上下文。然而,它在捕获动态全局上下文方面仍然有限,因为它只在整个序列上应用全局平均。
1.1 多分支架构
一种多分支架构,将输入分为两个分支:自注意力和卷积;并将它们的输出连接起来。工作目标是移动应用程序,并显示了机器翻译任务的改进。研究了如何将卷积和自注意有机地结合在ASR模型中。假设全局和局部相互作用对于参数效率都很重要。为了实现这一点,提出了一种新颖的自注意和卷积的组合,将实现两全其美——自注意学习全局交互,而卷积有效地捕获基于相对偏移量的局部相关性。受Wu等人[17,18]的启发,引入了一种新颖的自注意力和卷积的组合,夹在一对前馈模块之间,如图1所示。

2. Conformer Encoder
音频编码器首先用卷积子采样层处理输入,然后用一些共形块处理输入,如图1所示。模型的显著特征是使用Conformer块代替Transformer块,如[7,19]所示。
整型模块由四个堆叠在一起的模块组成,即前馈模块、自关注模块、卷积模块和最后的第二个前馈模块。
2.1 多头自注意力模块
采用多头自注意(MHSA),同时集成了Transformer-XL[20]中的一项重要技术,即相对正弦位置编码方案。相对位置编码允许自注意模块对不同的输入长度进行更好的泛化,并且生成的编码器对话语长度的变化具有更强的鲁棒性。使用带有dropout的prenorm残差单元[21,22],这有助于训练和正则化更深层次的模型。下面的图3说明了多头自注意块。

2.2 卷积模块
介绍了一种结合卷积模块和前馈模块的模型架构,受某些文献的启发,具体细节如下:
** 卷积模块:卷积模块首先使用了一个门控机制(gating mechanism),具体实现包括逐点卷积(pointwise convolution)和门控线性单元(GLU)。这种门控机制可以有效控制信息流。在此之后,模型采用了一层1维深度可分离卷积层,以提高卷积操作的效率和效果。为了促进深度模型的训练,卷积层之后紧接着应用了批量归一化(Batchnorm)**。该卷积块的结构:



2.3 前馈模块
** 前馈模块:前馈模块是继承自经典Transformer架构的,在多头自注意力层(MHSA layer)之后使用。这个模块由两个线性变换和夹在其中的非线性激活函数组成。此外,残差连接被添加到前馈层上,以帮助网络保留信息流,并在前馈层之后进行层归一化(Layer Normalization)**。这种结构同样被应用到语音识别的Transformer模型中。
** 预归一化残差单元:为了优化残差单元的训练过程,采用了预归一化的残差单元(pre-norm residual units),这意味着在第一层线性层之前,先对输入进行层归一化。此外,作者使用了Swish激活函数,这是一种较新的激活函数,可以提升模型的性能。同时,dropout**技术也被应用到前馈模块中,帮助正则化网络,减少过拟合。图4展示了前馈模块的具体结构。

2.4 Conformer Block
Conformer模块包含两个前馈模块,夹在多头自注意力模块和卷积模块之间,如图1所示。这种三明治结构的灵感来自Macaron-Net [18], Macaron-Net提出将Transformer块中原有的前馈层替换为两个半步前馈层,一个在注意层之前,一个在注意层之后。与在Macron-Net中一样,在前馈(FFN)模块中使用了半步残差权重。第二个前馈模块之后是层归一化。从数学上讲,这意味着,对于向Conformer块 i 输入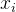,该块的输出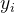为:
半步残差权重是指在两个前馈模块之间引入轻量级的残差连接,确保网络能够更好地利用这些层之间的相互关系
其中,FFN为前馈模块,MHSA为多头自注意力模块,Conv为卷积模块。
3. 实验
3.1 数据
首先,实验数据来自 **LibriSpeech 数据集**,该数据集包含 970 小时的标注语音数据,以及一个额外的包含 8 亿个单词的仅文本语料库,用于构建语言模型(Language Model, LM)。
** 特征提取**:从语音信号中提取了 80 维滤波器组(filterbank)特征,这些特征是从一个 25 毫秒的窗口中计算出来的,时间步长为 10 毫秒。
** 数据增强**:使用了 SpecAugment 数据增强技术,通过遮罩(masking)来增强数据的多样性。具体参数包括 F=27,以及最大遮罩时间长度为语句长度的 5%。
3.2. Conformer 转录器
实验中使用了三种模型,分别是 **small**、**medium** 和 **large** 模型,参数量分别为 1000 万、3000 万和 1.18 亿。通过改变网络深度、模型维度、注意力头数等组合进行搜索,选取了表现最优的模型。所有模型的解码器部分均使用了单层 LSTM。
** 正则化**:在每个残差单元的输出中,使用了 dropout 正则化技术,丢弃率为 0.1。此外,还引入了 变分噪声 来进一步增加模型的鲁棒性。同时,所有可训练的权重上都添加了
L2 正则化
,权重为 1e-6。
** 优化器**:使用 Adam 优化器,参数设置为 β1 = 0.9,β2 = 0.98,ϵ = 1e-9。训练过程中采用了 Transformer 学习率调度策略,进行了 10k 的 warm-up 步骤,学习率峰值为 0.05/√d,其中 d 是模型编码器的维度。
** 语言模型**:使用了 3 层 LSTM 语言模型,隐藏层宽度为 4096。语言模型的字词水平困惑度(word-level perplexity)在开发集上为 63.9。使用 浅层融合 技术(shallow fusion),通过网格搜索调节语言模型权重 λ。
3.4 消融实验
3.4.1 Conformer Block vs Transformer Block
** 卷积模块**:Conformer 块中包含一个卷积模块,这是与 Transformer 块最大的区别之一。
** Macaron 风格的 FFN 对**:Conformer 使用了 Macaron-Net 风格的两层前馈神经网络(FFN),而不是像 Transformer 块那样只使用单层 FFN。
** 卷积子块** 是 Conformer 块中最重要的特性,删除它会显著降低模型性能。Macaron 风格的 FFN 对 的表现也比具有相同参数量的单个 FFN 更好。使用 Swish 激活函数 可以加快 Conformer 模型的收敛速度。
3.4.2 卷积与自注意力模块的组合
研究了不同方式组合 **卷积模块** 和 **多头自注意力模块 (MHSA)** 的效果。**使用轻量卷积代替深度卷积** 会导致性能显著下降,尤其是在 dev-other 数据集上。**将卷积模块放在 MHSA 之前** 会使得模型性能轻微下降。**并行的 MHSA 和卷积模块**(将输出连接)导致性能不如原始架构。
将卷积模块放在 MHSA 模块之后是最优的设计。
3.4.3 Macaron 风格的前馈神经网络模块
Conformer 模块使用的是 **Macaron 风格的前馈神经网络对 (FFN)**,它将自注意力和卷积模块夹在中间,并使用半步残差连接。研究结果表明,与使用单个 FFN 或全步残差相比,Macaron 风格的 FFN 对表现更优。
3.4.4 注意力头的数量
当注意力头的数量增加到 16 时,模型的准确率特别是在 dev-other 数据集上得到了提升,超过这个数量后效果趋于平稳。
3.4.5 卷积核大小的影响
随着卷积核大小的增大,性能逐渐提高,最佳性能出现在卷积核大小为 17 和 32 时,但当卷积核大小增至 65 时,性能有所下降。
版权归原作者 托比-马奎尔 所有, 如有侵权,请联系我们删除。