遥感航拍影像25篇CVPR39个数据集
本文讲解了39个数据集,关于高空卫星图和低空无人机航拍图相。本文汇总了25篇CVPR2020年和2021年的论文。本文详细介绍了这25篇论文的任务是什么,难点是什么,场景是什么。同时,本文在需要的地方解释了一些卫星图和航拍图的入门常识和前置知识,比如digital surface model的含义。
深度学习从入门到精通——基于深度学习的地震数据去噪处理
传统机器学习SVM,boosting,bahhing,knn深度学习CNN(典型),GAN地震应用方向叠前地震数据随机噪声去除,实现噪声分离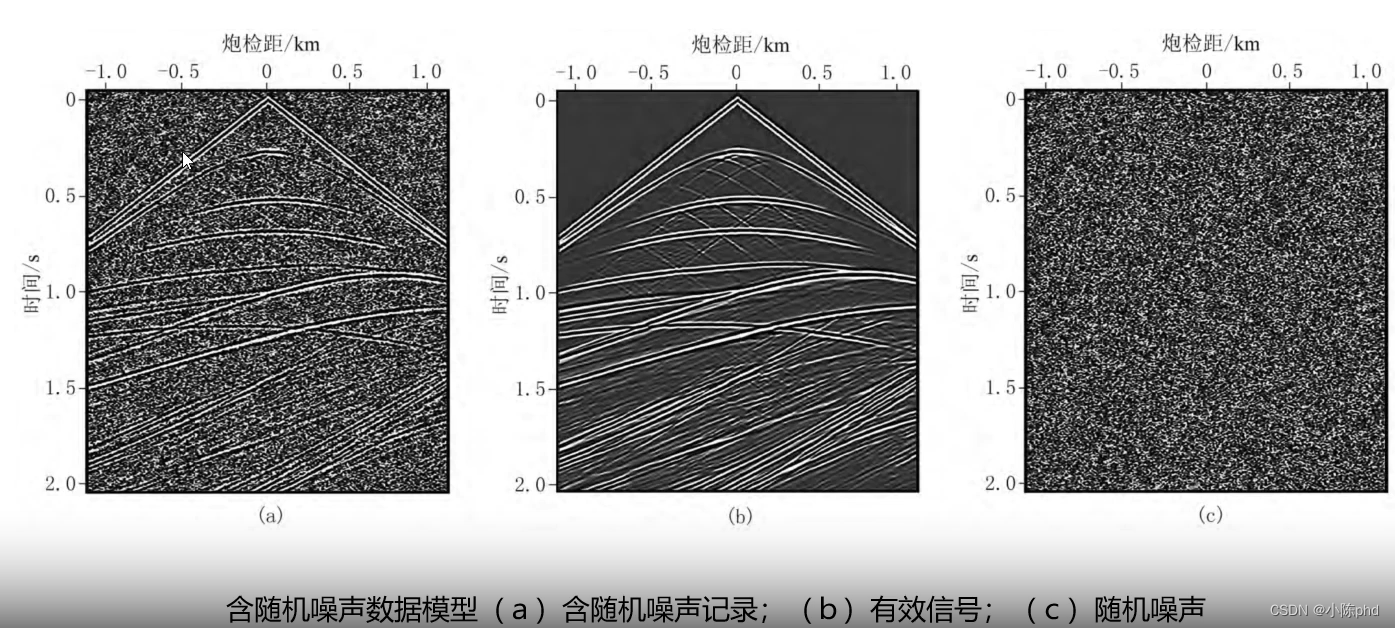面波去噪面波作
使用YOLOv5训练NEU-DET数据集
一、下载YOLOv5源码和NEU-DET(钢材表面缺陷)数据集YOLOv5源码NEU-DET(钢材表面缺陷)数据集这里的数据集已经经过处理了,下载即可若通过其他途径下载的原始数据集标签为xml格式,需要转化为txt格式XML转txt格式脚本二、数据集准备NEU-DET(钢材表面缺陷)数据集中一共有六
YOLOv7训练自己的数据集(超详细)
官方版本的YOLOv7训练自己的数据集
深度学习-inception模块介绍
深度学习-inception模块介绍
对比yolov4和yolov3
总体而言,yolov4是尝试组合一堆tricks,获取得到的模型,该模型具有训练更快、模型更轻、精度更高的特性。
tensorflow gpu版本安装教程
过程十分简陋,仅仅是个人的安装笔记,但其中粗体的注意事项大家可以参考一下,或许能解决你的报错。此过程需要提前安装好anaconda。我安装的为3.9.7的python,对应2.6.0的tensorflow安装过程分为:更新驱动NVIDIA,安装cuda和cudnn,tensorflow更新NVIDI
Windows上tensorflow的GPU死活引用不了(tensorflow 2.11无法调用GPU)
安装了多个版本的TF(tensorflow-gpu)(这个可以正常使用gpu,但是不兼容pandas,艹!实际上对CPU核心多一点(20核服务器)的,GPU提升效果也就那样哈哈哈~下载了多个版本的CUDA(12.0、11.x)(一般都有驱动程序,只需要下工具包,使用。发现回退到2.10就可以用了。不
【K210】K210学习笔记六——MaixHub在线模型训练识别数字
本文着重于如何使用MaixHub平台,在线训练模型,识别数字。MaixHub平台在近期升级了,以前只能将数据包上传训练,现在可以直接将图片上传到MaixHub平台,使用MaixHub平台打标签,然后训练模型,并且可以在MaixHub上看到识别的精准度等信息。......
VoxelNet点云检测详解
1、前言 精确的点云检测在很多三维场景的应用中都是十分重要的一环,比如家用机机器人、无人驾驶汽车等场景。然而高效且准确的点云检测在pointnet网络提出之前,一直没能取得很好的进展,因为传统的手工点云特征提取没有很好的泛化性能。所以VoxelNet是一个端到端的点云检测模型。直接使用深度学习
关于Pytorch中的train()和eval()(以及no_grad())
这三个函数实际上很常见,先来简单看下使用方法train()是nn.Module的方法,也就是你定义了一个网络model,那么表示将该model设置为训练模式,一般在开始新epoch训练时,我们会首先执行该命令:同train()一样,其用法和含义也一样,eval()是nn.Module的方法,也就是你
如何搭建深度学习环境及复现GitHub代码
在终端进行训练的话没法看到代码的细节,因此我们可以在pycharm中进行。conda activate name-of-env(接下来运行的内容就是基于这个环境的)在base这个土壤上搭建环境(不同的小房子),因为不同的代码运行需要不同的环境才能运行。在训练自己的网络时,只需要改变datasets中
LSTM实现多变量输入多步预测(Seq2Seq多步预测)时间序列预测(PyTorch版)
本专栏整理了《深度学习时间序列预测案例》,内包含了各种不同的基于深度学习模型的时间序列预测方法,例如LSTM、GRU、CNN(一维卷积、二维卷积)、LSTM-CNN、BiLSTM、Self-Attention、LSTM-Attention、Transformer等经典模型,包含项目原理以及源码,每一
【FMCW雷达人体行为识别——多普勒谱提取】
主要内容为英国格拉斯哥大学公开的一个人体行为的数据集。结合示例代码进行了分析,最终构建图片数据集用于后续的识别分类。解决了伪彩图保存时遇到的白边、尺寸变化的问题,同时通过批处理的方式加快了效率。............
BLIP2-图像文本预训练论文解读
BLIP-2,基于现有的图像编码器预训练模型,大规模语言模型进行预训练视觉语言模型;BLIP-2通过轻量级两阶段预训练模型Querying Transformer缩小模态之间gap,第一阶段从冻结图像编码器学习视觉语言表征,第二阶段基于冻结语言模型,进行视觉到语言生成学习;BLIP-2在各种视觉-语
GRU时间序列数据分类预测
GRU实现
使用GRU进行天气变化的时间序列预测
一个天气时间序列数据集,它由德国耶拿的马克思 • 普朗克生物地球化学研究所的气象站记录。在这个数据集中,每 10 分钟记录 14 个不同的量(比如气温、气压、湿度、风向等),其中包含2009-2016多年的记录。数据集下载地址GRU(Gate Recurrent Unit)是循环神经网络(Recur
zero-shot, one-shot和few-shot
zero-shot, one-shot和few-shot
BartModel 源码解析
BartModel的代码真的有太多的坑了



