
基本流程
《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
数据预处理(Dataset、Dataloader)
模型搭建(nn.Module)
损失&优化(loss、optimizer)
训练(forward、backward)
一、数据处理
对于数据处理,最为简单的⽅式就是将数据组织成为⼀个 。
但许多训练需要⽤到mini-batch,直 接组织成Tensor不便于我们操作。
pytorch为我们提供了Dataset和Dataloader****两个类来方便的构建。
torch.utils.data.DataLoader(dataset,batch_size,shuffle,drop_last,num_workers)

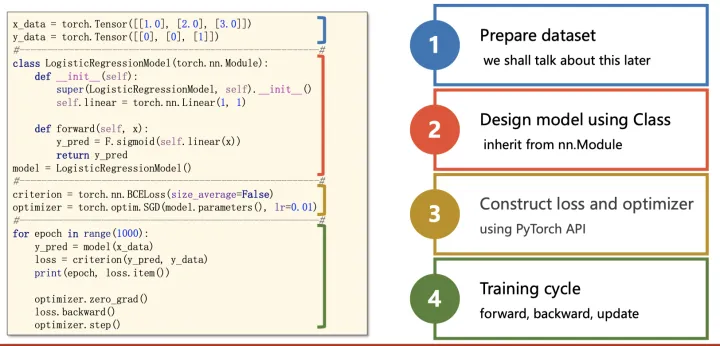
二、模型搭建
搭建一个简易的神经网络
除了采用pytorch自动梯度的方法来搭建神经网络,还可以通过构建一个继承了torch.nn.Module的新类,来完成forward和backward的重写。
# 神经网络搭建
import torch
from torch.autograd import Varible
batch_n = 100
hidden_layer = 100
input_data = 1000
output_data = 10
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
def forward(self,input,w1,w2):
x = torch.mm(input,w1)
x = torch.clamp(x,min = 0)
x = torch.mm(x,w2)
def backward(self):
pass
model = Model()
#训练
x = Variable(torch.randn(batch_n,input_data))
一点一点地看:
import torch
dtype = torch.float
device = torch.device("cpu")
N, D_in, H, D_out = 64, 1000, 100, 10
# Create random input and output data
x = torch.randn(N, D_in, device=device, dtype=dtype)
y = torch.randn(N, D_out, device=device, dtype=dtype)
# Randomly initialize weights
w1 = torch.randn(D_in, H, device=device, dtype=dtype)
w2 = torch.randn(H, D_out, device=device, dtype=dtype)
learning_rate = 1e-6
tensor 写一个粗糙版本(后面陆陆续续用pytorch提供的方法)
for t in range(500):
# Forward pass: compute predicted y
h = x.mm(w1)
h_relu = h.clamp(min=0)
y_pred = h_relu.mm(w2)
# Compute and print loss
loss = (y_pred - y).pow(2).sum().item()
if t % 100 == 99:
print(t, loss)
# Backprop to compute gradients of w1 and w2 with respect to loss
grad_y_pred = 2.0 * (y_pred - y)
grad_w2 = h_relu.t().mm(grad_y_pred)
grad_h_relu = grad_y_pred.mm(w2.t())
grad_h = grad_h_relu.clone()
grad_h[h < 0] = 0
grad_w1 = x.t().mm(grad_h)
# Update weights using gradient descent
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
三、定义代价函数&优化器
Autograd
for t in range(500):
y_pred = x.mm(w1).clamp(min=0).mm(w2)
loss = (y_pred - y).pow(2).sum()
if t % 100 == 99:
print(t, loss.item())
loss.backward()
with torch.no_grad():
w1 -= learning_rate * w1.grad
w2 -= learning_rate * w2.grad
w1.grad.zero_()
w2.grad.zero_()
对于需要计算导数的变量(w1和w2)创建时设定requires_grad=True,之后对于由它们参与计算的变量(例如loss),可以使用loss.backward()函数求出loss对所有requires_grad=True的变量的梯度,保存在w1.grad和w2.grad中。
在迭代w1和w2后,即使用完w1.grad和w2.grad后,使用zero_函数清空梯度。
nn
model = torch.nn.Sequential(
torch.nn.Linear(D_in, H),
torch.nn.ReLU(),
torch.nn.Linear(H, D_out),
)
loss_fn = torch.nn.MSELoss(reduction='sum')
learning_rate = 1e-4
for t in range(500):
y_pred = model(x)
loss = loss_fn(y_pred, y)
if t % 100 == 99:
print(t, loss.item())
model.zero_grad()
loss.backward()
with torch.no_grad():
for param in model.parameters():
param -= learning_rate * param.grad
optim
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
for t in range(500):
y_pred = model(x)
loss = loss_fn(y_pred, y)
if t % 100 == 99:
print(t, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
四、训练
迭代进行训练以及测试,其中训练的函数
train
里就保存了进行梯度下降求解的方法
# 定义训练函数,需要
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
# 从数据加载器中读取batch(一次读取多少张,即批次数),X(图片数据),y(图片真实标签)。
for batch, (X, y) in enumerate(dataloader):
# 将数据存到显卡
X, y = X.to(device), y.to(device)
# 得到预测的结果pred
pred = model(X)
# 计算预测的误差
# print(pred,y)
loss = loss_fn(pred, y)
# 反向传播,更新模型参数
optimizer.zero_grad() #梯度清零
loss.backward() #反向传播
optimizer.step() #更新参数
# 每训练10次,输出一次当前信息
if batch % 10 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
设置为测试模型并设置不计算梯度,进行测试数据集的加载,判断预测值与实际标签是否一致,统一正确信息个数
# 将模型转为验证模式
model.eval()
# 测试时模型参数不用更新,所以no_gard()
with torch.no_grad():
# 加载数据加载器,得到里面的X(图片数据)和y(真实标签)
for X, y in dataloader:
加载数据
pred = model(X)#进行预测
# 预测值pred和真实值y的对比
test_loss += loss_fn(pred, y).item()
# 统计预测正确的个数
correct += (pred.argmax(1) == y).type(torch.float).sum().item()#返回相应维度的最大值的索引
test_loss /= size
correct /= size
print(f"correct = {correct}, Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
附录
mark一下很有用的博客
pytorch代码编写入门 - 简书
推荐给大家!Pytorch编写代码基本步骤思想 - 知乎
用pytorch实现神经网络_徽先生的博客-CSDN博客_pytorch 神经网络
Dataset、DataLoader
① 创建一个 Dataset 对象
② 创建一个 DataLoader 对象
③ 循环这个 DataLoader 对象,将xx, xx加载到模型中进行训练
DataLoader详解_sereasuesue的博客-CSDN博客_dataloader
都会|可能会_深入浅出 Dataset 与 DataLoader
Pytorch加载自己的数据集(使用DataLoader读取Dataset)_l8947943的博客-CSDN博客_pytorch dataloader读取数据
可以直接调用的数据集
https://www.pianshen.com/article/9695297328/
nn.Sequential
pytorch教程之nn.Sequential类详解——使用Sequential类来自定义顺序连接模型_LoveMIss-Y的博客-CSDN博客_sequential类
nn.Module
torch.nn.Module**是torch.nn.functional**中方法的实例化
pytorch教程之nn.Module类详解——使用Module类来自定义模型_LoveMIss-Y的博客-CSDN博客_torch.nn.module
对应Sequential的三种包装方式,Module有三种写法
model.train() 和 model.eval()
model.train()
for epoch in range(epoch):
for train_batch in train_loader:
...
zhibiao = test(epoch, test_loader, model)
def test(epoch, test_loader, model):
model.eval()
for test_batch in test_loader:
...
return zhibiao
【Pytorch】model.train() 和 model.eval() 原理与用法_想变厉害的大白菜的博客-CSDN博客_pytorch train()
pytroch:model.train()、model.eval()的使用_像风一样自由的小周的博客-CSDN博客_model.train()放在程序的哪个位置
model = ...
dataset = ...
loss_fun = ...
# training
lr=0.001
model.train()
for x,y in dataset:
model.zero_grad()
p = model(x)
l = loss_fun(p, y)
l.backward()
for p in model.parameters():
p.data -= lr*p.grad
# evaluating
sum_loss = 0.0
model.eval()
with torch.no_grad():
for x,y in dataset:
p = model(x)
l = loss_fun(p, y)
sum_loss += l
print('total loss:', sum_loss)
https://www.jb51.net/article/211954.htm
损失
MAE:
import torch
from torch.autograd import Variable
x = Variable(torch.randn(100, 100))
y = Variable(torch.randn(100, 100))
loos_f = torch.nn.L1Loss()
loss = loos_f(x,y)
MSE:
import torch
from torch.autograd import Variable
x = Variable(torch.randn(100, 100))
y = Variable(torch.randn(100, 100))
loos_f = torch.nn.MSELoss()#定义
loss = loos_f(x, y)#调用
torch.nn中常用的损失函数及使用方法_加油上学人的博客-CSDN博客_nn损失函数
优化器
pytorch 优化器调参以及正确用法 - 简书
训练&测试
基于pytorch框架下的一个简单的train与test代码_黎明静悄悄啊的博客-CSDN博客
图神经网络
- GCN、GAT
图神经网络及其Pytorch实现_jiangchao98的博客-CSDN博客_pytorch 图神经网络
- 用DGL
PyTorch实现简单的图神经网络_梦家的博客-CSDN博客_pytorch图神经网络
一文看懂图神经网络GNN,及其在PyTorch框架下的实现(附原理+代码) - 知乎
图神经网络的不足
•扩展性差,因为训练时需要用到包含所有节点的邻接矩阵,是直推性的(transductive)
•局限于浅层,图神经网络只有两层
•不能作用于有向图
- 用PyG
图神经网络框架-PyTorch Geometric(PyG)的使用__Old_Summer的博客-CSDN博客_pytorch-geometric
版权归原作者 sinat_38007523 所有, 如有侵权,请联系我们删除。