【语音算法】wav2vec系列原理和使用
wav2vec系列工作由facebook AI Research团队提出,包括wav2vec、vq-wav2vec、wav2vec2.0,效仿nlp上的word2vec,是语音的一种通用特征提取器。本文重点讲解wav2vec2.0模型及其使用方法。
基于CNN网络的轴承故障诊断
内容参考:《基于卷积神经网络的轴承故障 诊断算法研究》–张伟代码参考:https://github.com/AaronCosmos/wdcnn_bearning_fault_diagnosis1 背景:基于信号处理的特征提取+分类器的传统智能诊断算法,对专家经验要求高,设计耗时且不能保证通用性,已经
【Google语音转文字】Speech to Text 超级好用的语音转文本API
Google speech to text api 语音转文本
SU-03T语音模块的使用(小智语音控制LED灯)
SU-03T语音模块控制LED灯的亮灭以及亮度调节;
使用OpenAI的Whisper 模型进行语音识别
Whisper模型是在68万小时标记音频数据的数据集上训练的,其中包括11.7万小时96种不同语言的演讲和12.5万小时从”任意语言“到英语的翻译数据。该模型利用了互联网生成的文本,这些文本是由其他自动语音识别系统(ASR)生成而不是人类创建的。该数据集还包括一个在VoxLingua107上训练的语
半小时用ChatGPT构建你的虚拟形象
大家好,欢迎来到我的频道,今天我来教大家如何用ChatGPT创建一个虚拟形象,如下图和视频所示。
开源VOSK引擎免费语音转文字部署
音频转文字,开源
ROS学习笔记17: ROS语音交互功能
到科大讯飞开放平台下载语音交互的功能包 在文件夹下执行编译命令编译,如果出现以下报错:则执行如下命令安装:,再次进行编译会出现如下警告,不必理会。2.运行语音转文字例程 在bin文件夹下会生成一个,我们运行看看这个例程。运行例程时会报错如下:解决方法是把文件复制到文件夹下: 复制完后重新运行会
提速300%,PaddleSpeech语音识别高性能部署方案重磅来袭!
PaddleSpeech 1.3版本正式发布,ASR与TTS支持高性能部署
人工智能交互系统界面设计(Tkinter界面设计)
本平台利用Tkinter模块搭建了一个人工智能系统界面,用户在界面按下按钮或者输入文本框内容,可以与系统进行数据交互,使用户能够在一个界面就完成本平台基本的Python程序功能。
分享本周所学——人工智能语音识别模型CTC、RNN-T、LAS详解
本人是一名人工智能初学者,最近一周学了一下AI语音识别的原理和三种比较早期的语音识别的人工智能模型,就想把自己学到的这些东西都分享给大家,一方面想用浅显易懂的语言让大家对这几个模型有所了解,另一方面也想让大家能够避免我所遇到的一些问题。然后因为我也只是一名小白,所以有错误的地方还希望大佬们多多指正。
MFCC特征提取
在语音识别方面,最常用到的语音特征就是梅尔倒谱系数(Mel-scaleFrequency Cepstral Coefficients,简称MFCC)。 MFCC的提取过程包括预处理、快速傅里叶变换、Mei滤波器组、对数运算、离散余弦变换、动态特征提取等步骤。
Python将语音识别成文字
theme: orange持续创作,加速成长!这是我参与「掘金日新计划 · 6 月更文挑战」的第30天,点击查看活动详情 ???? 个人主页:@青Cheng序员石头 在本教程中,我们将学习如何将语音或音频文件转换为文本格式,此处主要是用Python相关库完成功能。语音识别介绍Python支持许
音频(一)时域图、 频谱图 Spectrum
梅尔频率 倒谱 系数为了理解 梅尔频率 倒谱系数 , 我们需要先理解以下基本概念:mel frequency cepstrum coefficient1. 频谱1.1 声音信号是一维的时域信号,无法观察出频率随时间的变化规律。1.2 频谱: 如果通过傅里叶变换把它变到频域上,可以看出信
语音识别(利用python将语音转化为文字)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档文章目录前言一、申请讯飞语音端口1.点击链接进入讯飞平台主页面2.在页面注册自己的个人账户3.申请语音端口4.查看自己的端口编码二、python代码讲解1.引入库2.读入数据总结前言本篇博客讲述利用讯飞端口将语音转化为文字。一、申请讯飞
OpenAI 开源语音识别模型 Whisper 初体验
Whisper 是一个自动语音识别(ASR,Automatic Speech Recognition)系统,OpenAI 通过从网络上收集了 68 万小时的多语言(98 种语言)和多任务(multitask)监督数据对 Whisper 进行了训练。OpenAI 认为使用这样一个庞大而多样的数据集,可
语音识别芯片LD3320介绍
LD3320 芯片是一款“语音识别”芯片,集成了语音识别处理器和一些外部电路,包括AD、DA 转换器、麦克风接口、声音输出接口等。
非常全面的数字人解决方案(含源码)
数字人解决方案实际应用案例抖音虚拟主播人机交互数字站桶人首先我先给数字人重新做一个定义:“把人数字化,以行人的职责”。怎么理解呢?我举两个例子就清楚了。第一个是现在直播带货,主播成本越来越高,我们的数字人能否代替主播24小时自动带货呢?这里数字化的是主播的形象、声音、性格特质,以及商品的知识。另一个
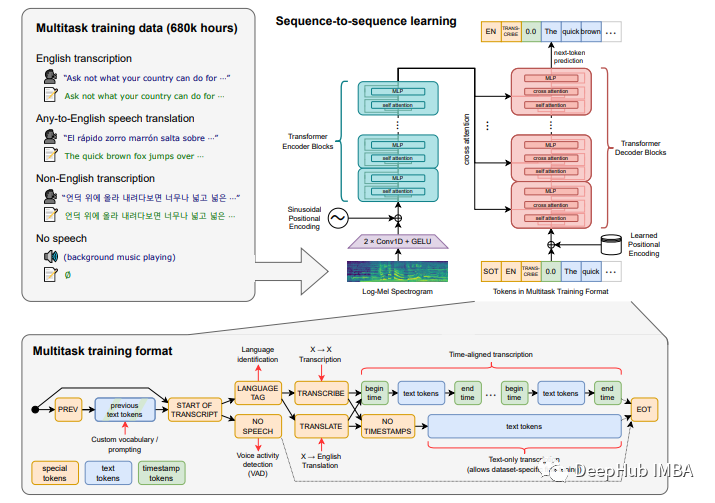
使用OpenAI的Whisper 模型进行语音识别
本文将解释用于训练的数据集的种类以及模型的训练方法,以及如何使用Whisper
人工智能:通过Python实现语音合成的案例
今天给大家介绍一下基于百度的AI语音技术SDK实现语音合成的案例,编程语言采用Python,希望对大家能有所帮助!



