
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
本篇博客讲述利用讯飞端口将语音转化为文字。
一、申请讯飞语音端口
1.点击链接进入讯飞平台主页面
2.在页面注册自己的个人账户
ps:注册账户是完全免费的,因为我之前已经注册过一个了,这里就不重复介绍了,注册之后看个人情况进行个人认证,这个不影响之后的操作。
3.申请语音端口

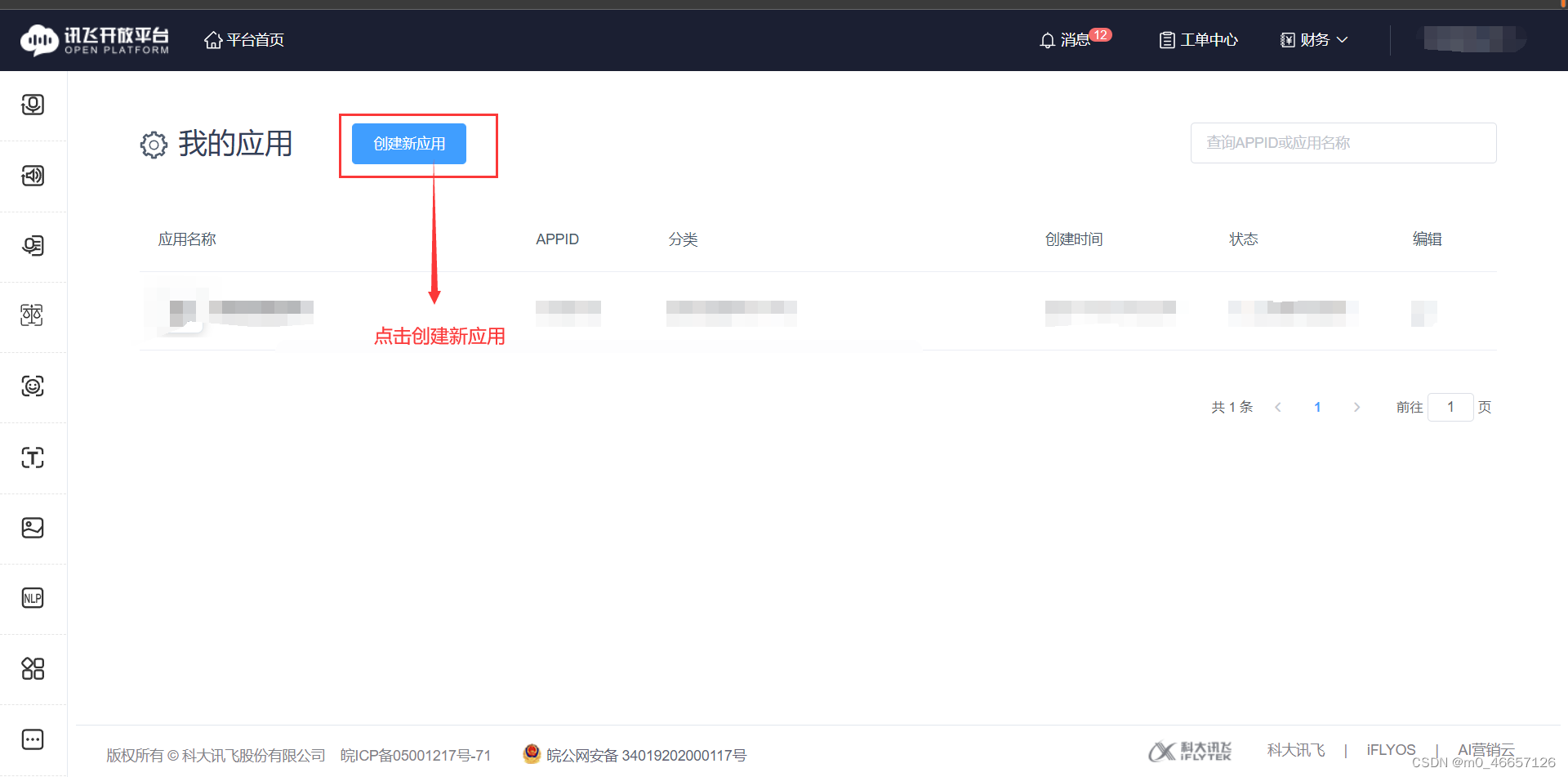
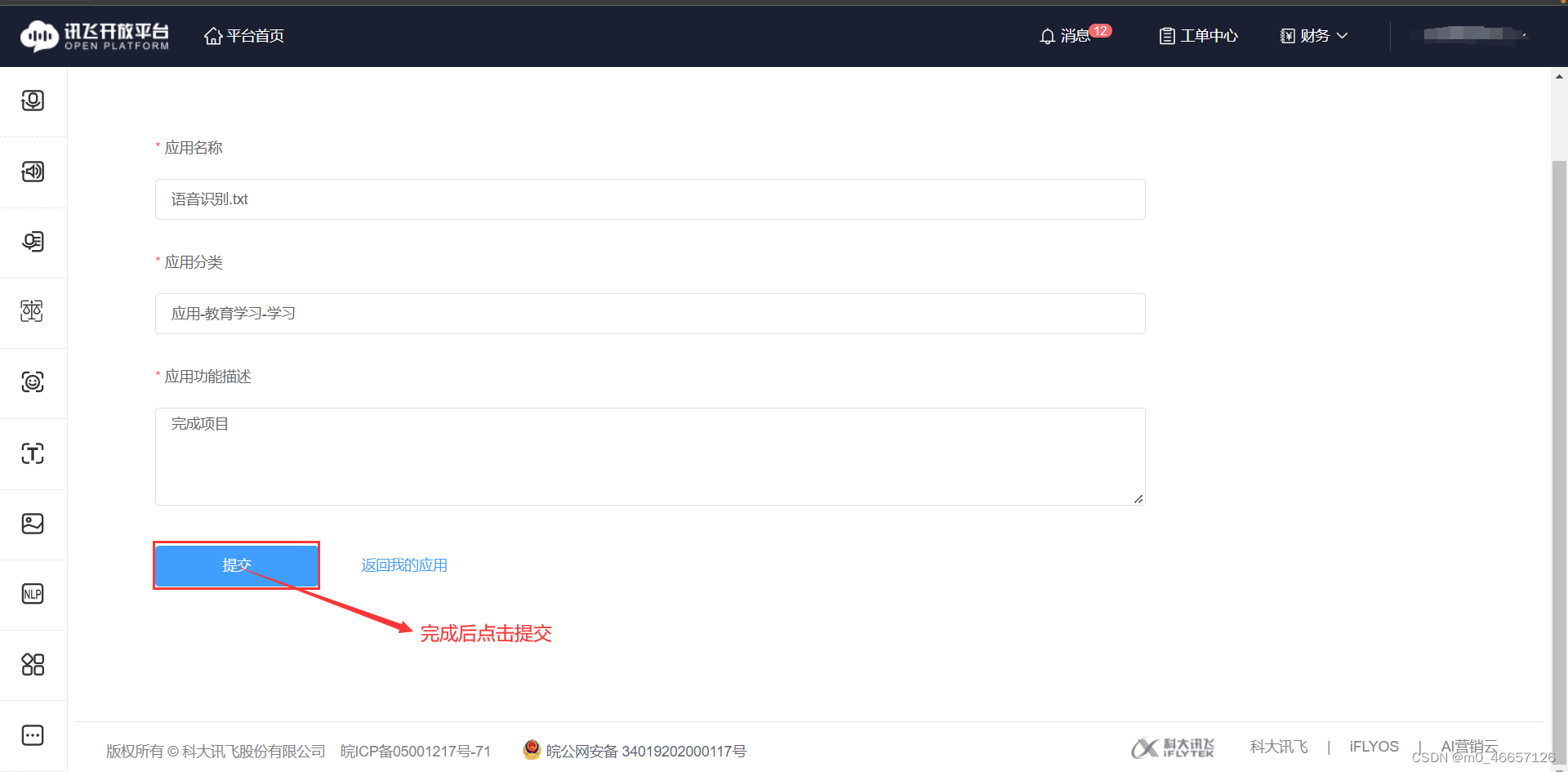
ps:申请内容大概像我这样写就行,名字重复的话换一个
4.查看自己的端口编码
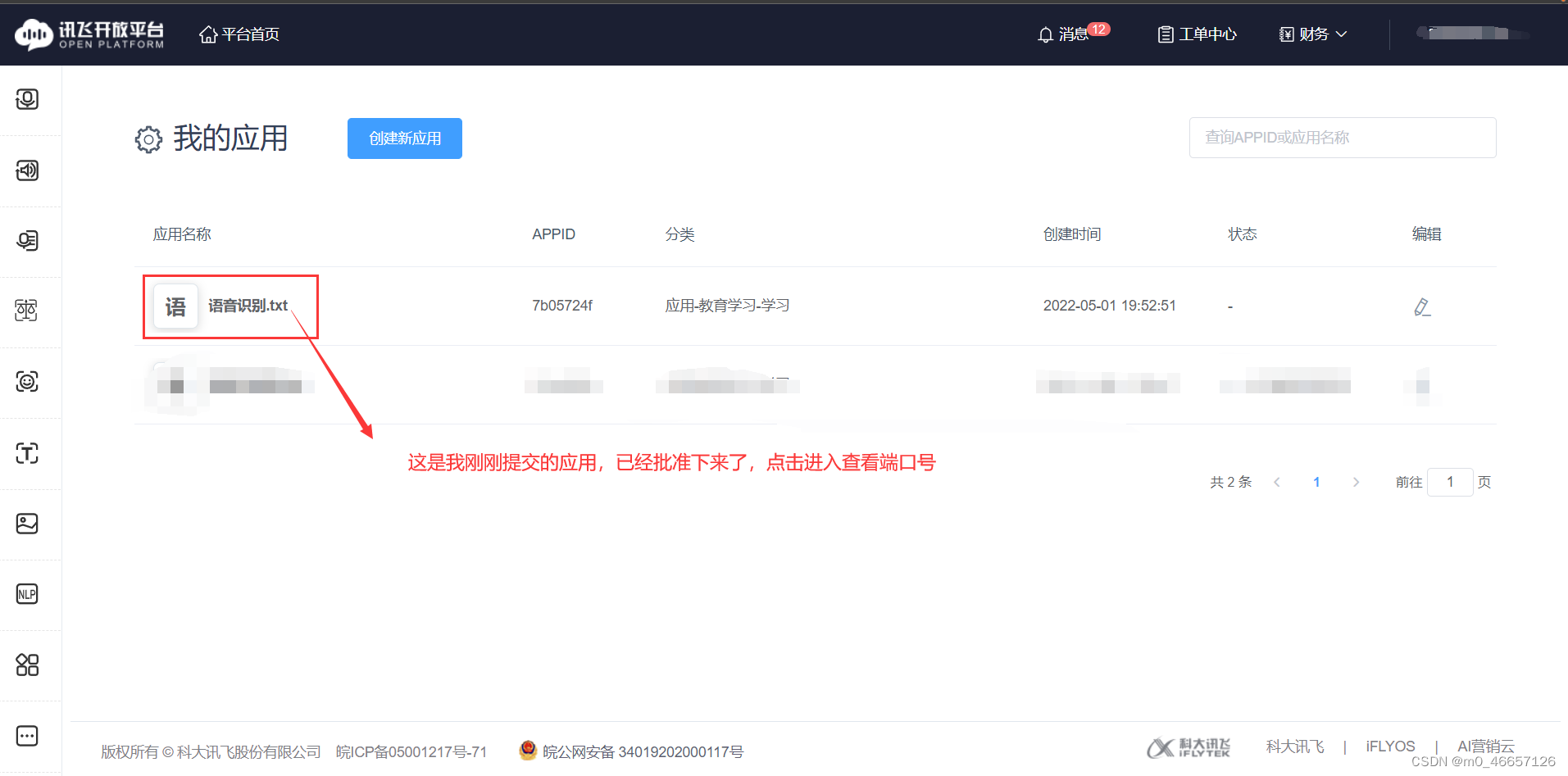
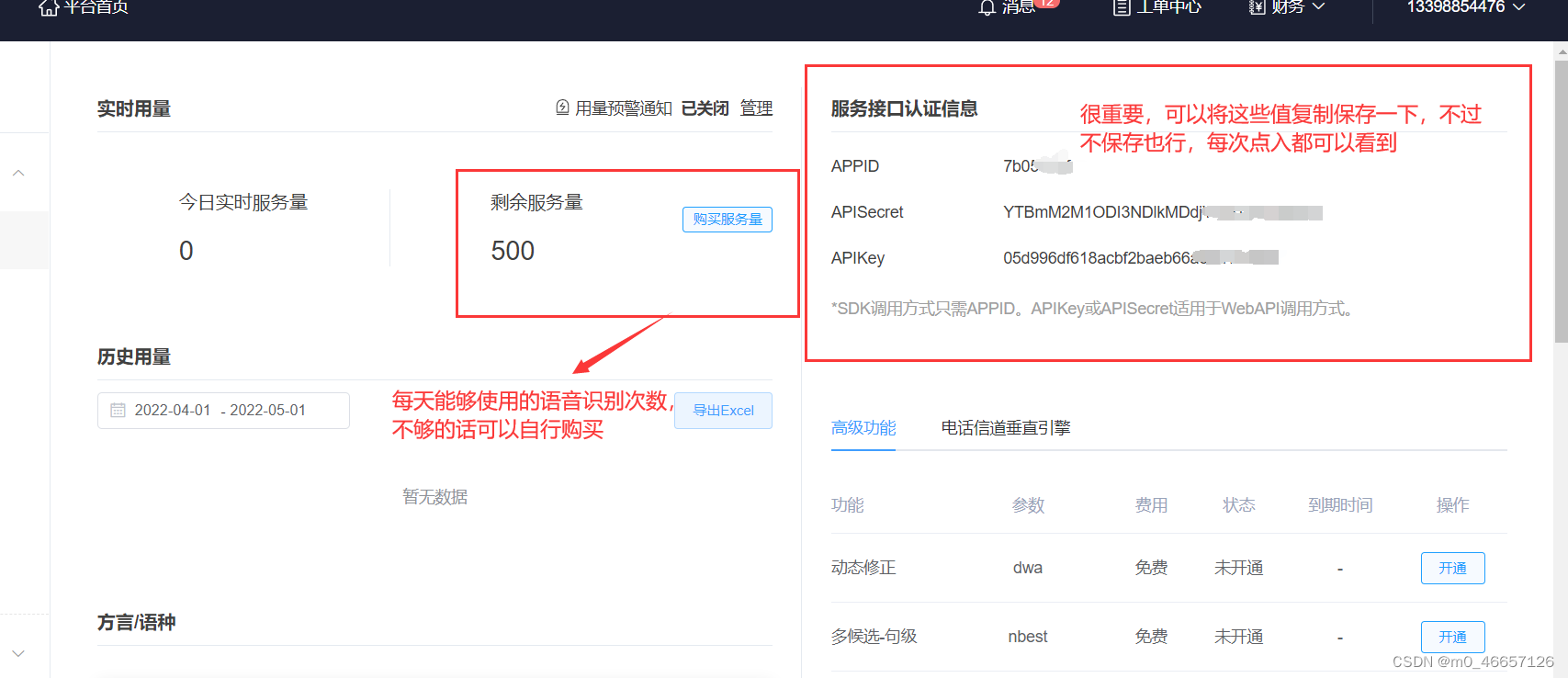
二、python代码讲解
1.代码如下(实例)
代码如下(示例):
#使用语音
import threading
import websocket
import hashlib
import base64
import hmac
import json
from urllib.parse import urlencode
import time
# 该模块为客户端和服务器端的网络套接字提供对传输层安全性(通常称为“安全套接字层”)
# 的加密和对等身份验证功能的访问。
import ssl
from wsgiref.handlers import format_date_time
from datetime import datetime
from time import mktime
import _thread as thread
import pyaudio
STATUS_FIRST_FRAME =0 # 第一帧的标识
STATUS_CONTINUE_FRAME =1 # 中间帧标识
STATUS_LAST_FRAME =2 # 最后一帧的标识
class Ws_Param(object):
# 初始化
def __init__(self, APPID, APIKey, APISecret):
self.APPID = APPID
self.APIKey = APIKey
self.APISecret = APISecret
# 公共参数(common)
self.CommonArgs ={"app_id": self.APPID}
# 业务参数(business),更多个性化参数可在官网查看
self.BusinessArgs ={"domain":"iat","language":"zh_cn","accent":"mandarin","vinfo":1,"vad_eos":10000}
# 生成url
def create_url(self):
url ='wss://ws-api.xfyun.cn/v2/iat'
# 生成RFC1123格式的时间戳
now = datetime.now()
date =format_date_time(mktime(now.timetuple()))
# 拼接字符串
signature_origin ="host: "+"ws-api.xfyun.cn"+"\n"
signature_origin +="date: "+ date +"\n"
signature_origin +="GET "+"/v2/iat "+"HTTP/1.1"
# 进行hmac-sha256进行加密
signature_sha = hmac.new(self.APISecret.encode('utf-8'), signature_origin.encode('utf-8'),
digestmod=hashlib.sha256).digest()
signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8')
authorization_origin ="api_key=\"%s\", algorithm=\"%s\", headers=\"%s\", signature=\"%s\""%(
self.APIKey,"hmac-sha256","host date request-line", signature_sha)
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
# 将请求的鉴权参数组合为字典
v ={"authorization": authorization,"date": date,"host":"ws-api.xfyun.cn"}
# 拼接鉴权参数,生成url
url = url +'?'+urlencode(v)#print("date: ",date)#print("v: ",v)
# 此处打印出建立连接时候的url,参考本demo的时候可取消上方打印的注释,比对相同参数时生成的url与自己代码生成的url是否一致
#print('websocket url :', url)return url
# 收到websocket消息的处理
def on_message(ws, message):
try:
code = json.loads(message)["code"]
sid = json.loads(message)["sid"]if code !=0:
errMsg = json.loads(message)["message"]print("sid:%s call error:%s code is:%s"%(sid, errMsg, code))else:
data = json.loads(message)["data"]["result"]["ws"]
result =""for i in data:for w in i["cw"]:
result += w["w"]if result =='。' or result =='.。' or result ==' .。' or result ==' 。':
pass
else:#t.insert(END, result) # 把上边的标点插入到result的最后print("翻译结果: %s。"%(result))
except Exception as e:print("receive msg,but parse exception:", e)
# 收到websocket错误的处理
def on_error(ws, error):print("### error:", error)run()
# 收到websocket关闭的处理
def on_close(ws):
pass
# 收到websocket连接建立的处理
def on_open(ws):
def run(*args):
status = STATUS_FIRST_FRAME # 音频的状态信息,标识音频是第一帧,还是中间帧、最后一帧
CHUNK =520 # 定义数据流块
FORMAT = pyaudio.paInt16 # 16bit编码格式
CHANNELS =1 # 单声道
RATE =16000 # 16000采样频率
# 实例化pyaudio对象
p = pyaudio.PyAudio() # 录音
# 创建音频流
# 使用这个对象去打开声卡,设置采样深度、通道数、采样率、输入和采样点缓存数量
stream = p.open(format=FORMAT, # 音频流wav格式
channels=CHANNELS, # 单声道
rate=RATE, # 采样率16000
input=True,
frames_per_buffer=CHUNK)print("- - - - - - - Start Recording ...- - - - - - - ")
# 添加开始表示 ——start recording——
global text
tip ="——start recording——"for i in range(0,int(RATE / CHUNK *60)):
# # 读出声卡缓冲区的音频数据
buf = stream.read(CHUNK)if not buf:
status = STATUS_LAST_FRAME
if status == STATUS_FIRST_FRAME:
d ={"common": wsParam.CommonArgs,"business": wsParam.BusinessArgs,"data":{"status":0,"format":"audio/L16;rate=16000","audio":str(base64.b64encode(buf),'utf-8'),"encoding":"raw"}}
d = json.dumps(d)
ws.send(d)
status = STATUS_CONTINUE_FRAME
# 中间帧处理
elif status == STATUS_CONTINUE_FRAME:
d ={"data":{"status":1,"format":"audio/L16;rate=16000","audio":str(base64.b64encode(buf),'utf-8'),"encoding":"raw"}}
ws.send(json.dumps(d))
# 最后一帧处理
elif status == STATUS_LAST_FRAME:
d ={"data":{"status":2,"format":"audio/L16;rate=16000","audio":str(base64.b64encode(buf),'utf-8'),"encoding":"raw"}}
ws.send(json.dumps(d))
time.sleep(1)break
thread.start_new_thread(run,())
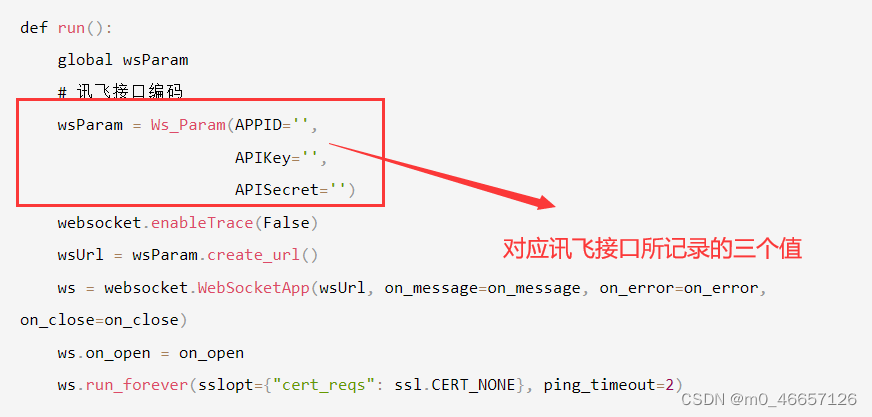
def run():
global wsParam
# 讯飞接口编码
wsParam =Ws_Param(APPID='',
APIKey='',
APISecret='')
websocket.enableTrace(False)
wsUrl = wsParam.create_url()
ws = websocket.WebSocketApp(wsUrl, on_message=on_message, on_error=on_error, on_close=on_close)
ws.on_open = on_open
ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE}, ping_timeout=2)
def runc():run()
class Job(threading.Thread):
def __init__(self,*args,**kwargs):super(Job, self).__init__(*args,**kwargs)
self.__flag = threading.Event() # 用于暂停线程的标识
self.__flag.set() # 设置为True
self.__running = threading.Event() # 用于停止线程的标识
self.__running.set() # 将running设置为True
def run(self):while self.__running.isSet():
self.__flag.wait() # 为True时立即返回, 为False时阻塞直到内部的标识位为True后返回
runc()
time.sleep(1)
def pause(self):
self.__flag.clear() # 设置为False, 让线程阻塞
def resume(self):
self.__flag.set() # 设置为True, 让线程停止阻塞
def stop(self):
self.__flag.set() # 将线程从暂停状态恢复, 如何已经暂停的话
self.__running.clear() # 设置为False
a =Job()
a.start()
2.代码需要修改的部分
3.包的导入
Ps:因为没有新的Project Interpreter,所以不记得有什么包需要重新引入,唯一有印象的只有pyaudio了,所以这里就只提供了pyaudio的引入方法,其他的好像直接导入就可以了。
1)首先:下载安装 pyaudio 的 whl 文件
下载网址:https://www.lfd.uci.edu/~gohlke/pythonlibs/
2)该界面上输入ctrl+f,搜索pyaudio
3)下载
重点:一定要根据自己的版本进行下载!!!,每个人不一定是一样的。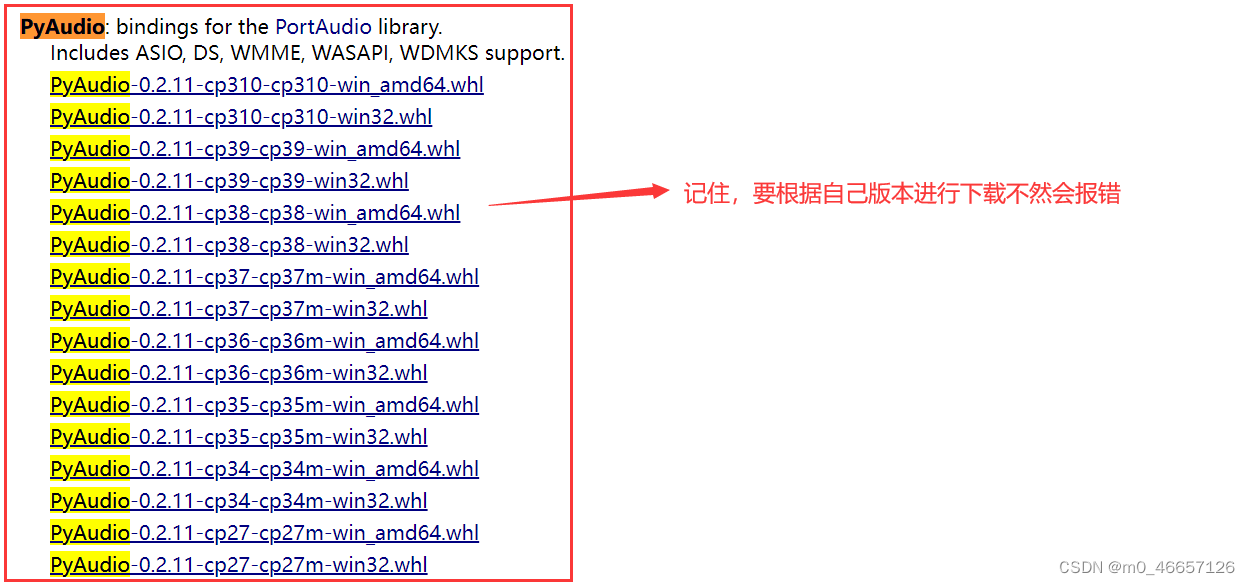
4)记录下载文件的安装路径,如果换位置,则记住新的位置
5)安装
键盘输入win+r,输入cmd打开终端模式
假设我的下载位置为D盘的杂项文件夹,那么可以先利用cd转到D盘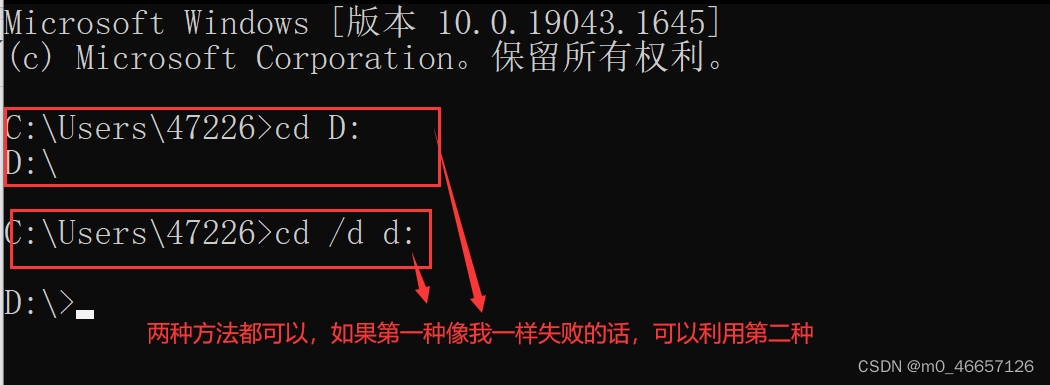
再转到杂项
进行安装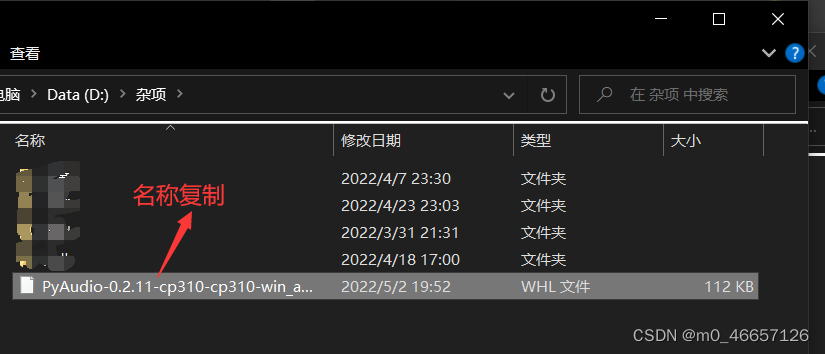
然后输入pip install 文件名称即可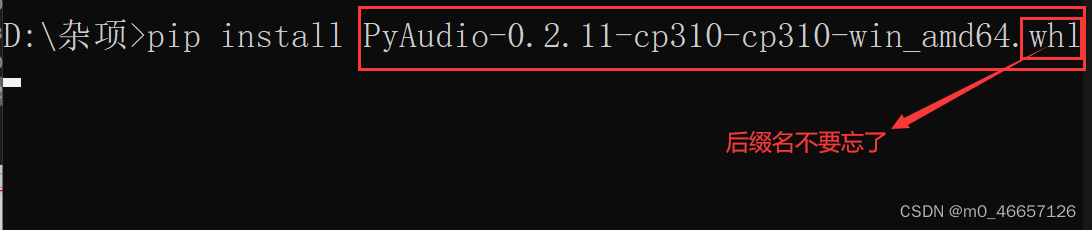
回车,安装结束
4.结果演示

5.代码所借鉴的原链接
https://github.com/lixi5338619/lxSpider/blob/main/案例代码/实时语音转写/yuyinTransfer.py
总结
此代码在源代码的基础上进行了改善,将语音识别的exe边框去除了,如果需要做一个界面的话,可以将字符串引入到所对应的页面位置,或窗体位置。本代码还有个局限性就是每隔60s会进行一次重连,大概1s后能重新进行识别,如果还有什么问题欢迎在评论区留言。
本文转载自: https://blog.csdn.net/m0_46657126/article/details/124531081
版权归原作者 沂水弦音 所有, 如有侵权,请联系我们删除。
版权归原作者 沂水弦音 所有, 如有侵权,请联系我们删除。