
OpenAI 开源语音识别模型 Whisper 初体验
前言
Whisper 是一个自动语音识别(ASR,Automatic Speech Recognition)系统,OpenAI 通过从网络上收集了 68 万小时的多语言(98 种语言)和多任务(multitask)监督数据对 Whisper 进行了训练。OpenAI 认为使用这样一个庞大而多样的数据集,可以提高对口音、背景噪音和技术术语的识别能力。除了可以用于语音识别,Whisper 还能实现多种语言的转录,以及将这些语言翻译成英语。
一、Whisper 9种运行模型以及所需配置
目前 Whisper 有 9 种模型(分为纯英文和多语言),其中四种只有英文版本,开发者可以根据需求在速度和准确性之间进行权衡,以下是现有模型的大小,及其内存要求和相对速度:
大小参数纯英文模型多语言模型所需显存相对速度tiny39 Mtiny.entiny1 GB32xbase74 Mbase.enbase1 GB16xsmall244 Msmall.ensmall2 GB6xmedium769 Mmedium.enmedium5 GB2xlarge1550 MN/Alarge~10 GB1x
二、使用conda 和 ffmpeg的实现步骤
1.准备环境
- windos 安装conda > 安装可以参考https://www.jianshu.com/p/c183c1d7e1d1
- windos安装ffmpeg > 安装ffmpeg可以使用Scoop 包管理工具去下载,具体安装方法借鉴https://zhuanlan.zhihu.com/p/561204256 这篇文章。> 安装好Scoop后执行 scoop install ffmpeg
2. 执行命令
conda create -n whisper python=3.9
conda activate whisper
pip install git+https://github.com/openai/whisper.git
whisper audio.mp3 --model medium --language Chinese
3. 执行结果
三、使用python的实现步骤
1.准备环境
- windos 安装Python 3.9.9 或以上版本
- windos安装ffmpeg > 安装ffmpeg可以使用Scoop 包管理工具去下载,具体安装方法借鉴https://zhuanlan.zhihu.com/p/561204256 这篇文章。> 安装好Scoop后执行 scoop install ffmpeg
- python 安装setuptools-rust > pip install setuptools-rust
- 下载Whisper 代码 > https://gitee.com/mirrors/openai-whisper.git 将其clone到本地> 执行命令:python setup.py install
2. 写代码
代码如下:
import whisper
import arrow
# 定义模型、音频地址、录音开始时间defexcute(model_name,file_path,start_time):
model = whisper.load_model(model_name)
result = model.transcribe(file_path)for segment in result["segments"]:
now = arrow.get(start_time)
start = now.shift(seconds=segment["start"]).format("YYYY-MM-DD HH:mm:ss")
end = now.shift(seconds=segment["end"]).format("YYYY-MM-DD HH:mm:ss")print("【"+start+"->"+end+"】:"+segment["text"])if __name__ =='__main__':
excute("base","55555.mp3","2022-10-24 16:23:00")
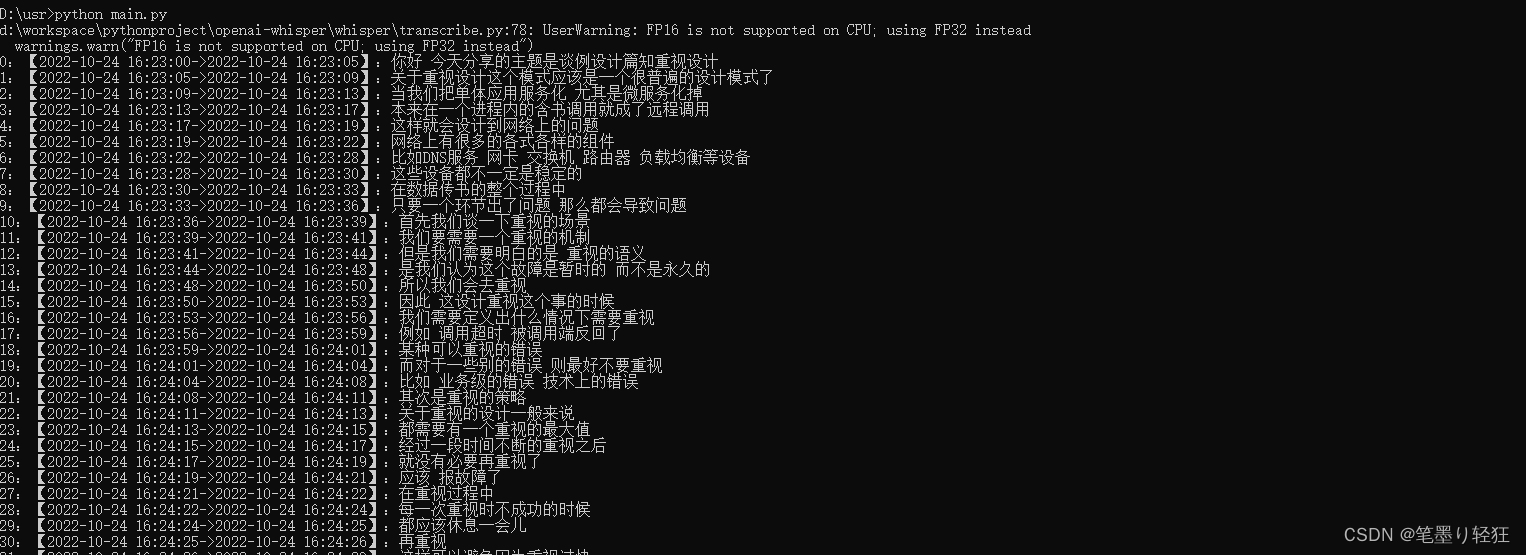
3. 执行结果
本文转载自: https://blog.csdn.net/weixin_44011409/article/details/127507692
版权归原作者 笔墨り轻狂 所有, 如有侵权,请联系我们删除。
版权归原作者 笔墨り轻狂 所有, 如有侵权,请联系我们删除。