声音信号的A律13折线(格雷码)编码仿真
本课题是点对点无噪通信场景下信源编译、码的应用,对给定声音信号采用A律13折线编码,并对处理过程涉及的不同信号形式进行绘图。
小白也能听懂的ai音声制作入门教程了!!!
ddsp-3.0是一款ai合成音频的开源项目,与之前的sovits,rvc,diff-svc不同,DDSP在训练推理速度和配置要求上都可以说是全面优于前面几个项目,并且训练效果有sovits4.0的80~90%,效果还是很不错的,只需要一张2G以上显存的N卡,花上一两个小时就可以训练完成,大大降低了
语音识别与Python编程实践
语音识别是一门复杂的交叉技术学科,通常涉及声学,信号处理,模式识别,语言学,心理学,以及计算机等多个学科领域。语音识别技术的发展可追寻到20世纪50年代,贝尔实验室首次实现Audrey英文数字识别系统(可识别0——9单个数字英文识别),并且准确识别率达到90%以上。普林斯顿大学和麻省理工学院在同一时
Wav2Vec & HuBert 自监督语音识别模型
自监督预训练语言模型,wav2vec, wav2vec2.0,HUBert
NV040C语音芯片:让自助ATM机使用更加安全快捷
通过在ATM机中加入NV040C的语音芯片,银行能够为用户提供更为便捷、温馨的操作体验。同时,芯片的多种语言支持还确保了不同地区的用户都能够得到准确的服务指导。这些举措无疑将提高用户的满意度,增强银行的竞争力。
【语音识别入门】特征提取(Python完整代码)
给定一段音频,请提取12维MFCC特征和23维FBank,阅读代码预加重、分帧、加窗部分,完善作业代码中FBank特征提取和MFCC特征提取部分,并给出最终的FBank特征和MFCC特征,存储在纯文本中,用默认的配置参数,无需进行修改。抽样时频率不够高,抽样出来的点既代表了信号中的低频信号的样本值,
AI智能语音识别模块(二)——基于Arduino的语音控制MP3播放器
在前面一篇文章里我们对AI智能语音识别模块进行了介绍,并对离线语音模组下载固件的过程进行了一个简单描述,不知道大家还记不记得,这篇文章也是鸽了好久,,本文将用这个语音控制模块结合前面介绍的DFPlayer Mini MP3模块来做一个有趣的应用,在上一期文章中,我们只是简单的做了一个只用语音控制模块
如何使用 Rask AI 进行视频本地化
Rask AI 提供多种功能,你可以根据需要选择。总体而言,Rask AI 是一个强大的视频本地化工具,可以帮助你将视频翻译成多种语言。该服务易于使用,并提供多种功能,可以满足你的不同需求。Rask AI 是一个强大的视频本地化工具,可以帮助你将视频翻译成多种语言。该服务易于使用,并提供多种功能,可
前端语音识别(webkitSpeechRecognition)
浏览器实现语音转文字
听懂未来:AI语音识别技术的进步与实战
本文全面探索了语音识别技术,从其历史起源、关键技术发展到广泛的实际应用案例,揭示了这一领域的快速进步和深远影响。文章深入分析了语音识别在日常生活及各行业中的变革作用,展望了其未来发展趋势。
音频特征提取
它表示音频信号频谱的复杂程度或不确定性,可以用于识别音频中的不同声音,例如不同乐器的音色。谱熵特征通常与其他特征(如MFCC、零交叉率、能量、谱滚降点和谱通量)结合使用,以提高音频处理任务的性能。色度特征通常与其他特征(如MFCC、零交叉率、能量、谱滚降点、谱通量和谱熵)结合使用,以提高音频处理任务
数字人系列一:10分钟打造AI对话数字人(平台提供数字人和问答库)
Motionverse是一款面向开发者的业务中台,利用AI技术,提供多模态实时驱动虚拟数字人的解决方案。它通过SDK和管理后台,解决产品和终端的虚拟数字人驱动问题。在元宇宙世界中,Motionverse能满足大量虚拟数字人的动作表情需求,通过各种输入情况,智能实时生成所需的动作表情和口型。作为中台产
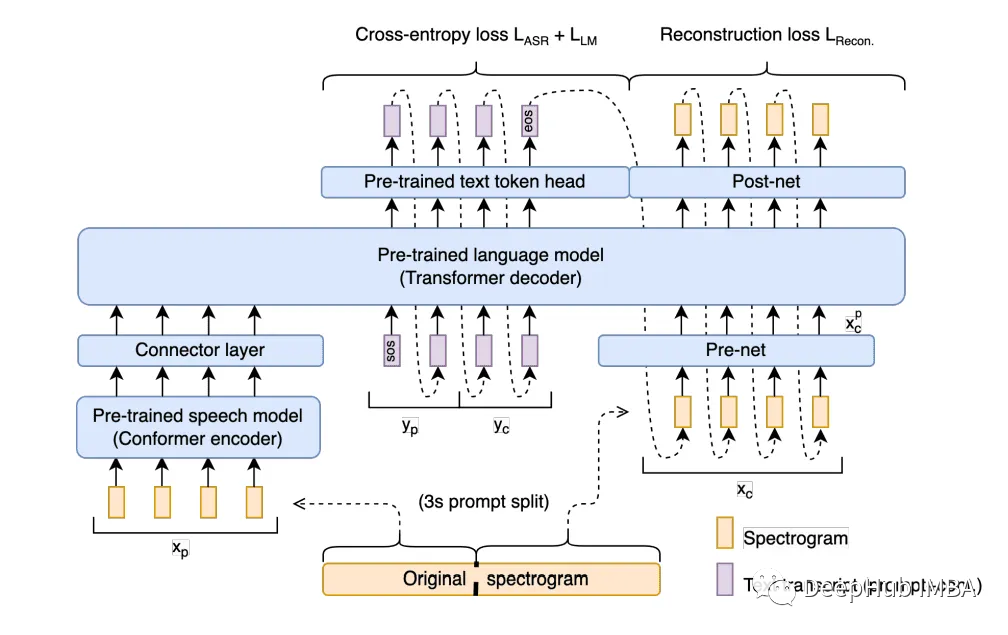
Spectron: 谷歌的新模型将语音识别与语言模型结合进行端到端的训练
Spectron是谷歌Research和Verily AI开发的新的模型。与传统的语言模型不同,Spectron直接处理频谱图作为输入和输出。该模型消除归纳偏差,增强表征保真度,提高音频生成质量。
CTC-Loss
CTC-Loss
基于达摩院modelscope语音模型, 实现20句话声音克隆合成
基于达摩院modelscope语音模型, 实现20句话声音克隆合成
AI 语音 - 人物音色训练
太多坑了,一不小心就会栽进去的,这东西没办法高谈阔论的,必须事必躬亲,不过一般完整走一遍流程基本就掌握了,我现在还没有那么想熟悉代码,gpu 碎片回收机制,代码优化还有很多可以做的,不过这次倒不急,及也急不来的。对于学习人工智能的小朋友们,虽说研究生阶段一般实验室会配备算力设备并且可以报销,但是自己
智能文字识别技术——AI赋能古彝文保护
合合信息前期在甲骨文、金文中所作的研究,让古彝文识别成为一件“水到渠成”的事情。此次合合信息与上海大学联合开启的“贵州古彝文图像识别及数字化校对项目”校企合作,将填补当前国内外研究的空白,也将成为合合信息智能文字识别技术赋能小语种保护及古文化传承的重要里程碑事件。未来,合合信息还将重点关注自然语言处
【人工智能】大模型之编码器基础知识
序列数据输入:编码器接收输入序列数据,并将其存储在内存中。自注意力机制:编码器使用自注意力机制来提取序列中的信息,以使模型能够更好地理解序列中的不同部分。编码器输出:编码器通过将输入序列和其对应的输出向量相减来实现对序列数据的预测。编码器是神经网络中的一个重要组件,它的主要作用是将输入序列数据编码成
让照片开口讲话,让视频人物对口型
一张图片,一个音频,让照片开口说话,让视频中的人物对口型。



