
目录

一、赛事背景
国内车企为提升产品竞争力、更好走向海外市场,提出了海外市场智能交互的需求。但世界各国在“数据安全”上有着严格法律约束,要做好海外智能化交互,本土企业面临的最大挑战是数据缺少。本赛题要求选手通过NLP相关人工智能算法来实现汽车领域多语种迁移学习。
二、赛事任务
本次迁移学习任务中,讯飞智能汽车BU将提供较多的车内人机交互中文语料,以及少量的中英、中日、中阿平行语料作为训练集,参赛选手通过提供的数据构建模型,进行意图分类及关键信息抽取任务,最终使用英语、日语、阿拉伯语进行测试评判。
1.初赛
训练集:中文语料30000条,中英平行语料1000条,中日平行语料1000条
测试集A:英文语料500条,日文语料500条
测试集B:英文语料500条,日文语料500条
2.复赛
训练集:中文语料同初赛,中阿拉伯平行语料1000条
测试集A:阿拉伯文语料500条
测试集B:阿拉伯文语料500条
三、评审规则
1.数据说明
本次比赛为参赛选手提供三类车内交互功能语料,其中包括命令控制类、导航类、音乐类。较多的中文语料和较少的多语种平行语料均带有意图分类和关键信息,选手需充分利用所提供数据,在英、日、阿拉伯语料的意图分类和关键信息抽取任务上取得较好效果。数据所含标签种类及取值类型如下表所示。
变量数值格式解释intentstring整句意图标签devicestring操作设备名称标签modestring操作设备模式标签offsetstring操作设备调节量标签endlocstring目的地标签landmarkstring周边搜索参照标签singerstring歌手songstring歌曲
2.评估指标
本模型依据提交的结果文件,采用accuracy进行评价。
(1)意图分类accuracy = 意图正确数目 / 总数据量
(2)关键信息抽取accuracy = 关键信息完全正确数目 / 总数据量
注:每条数据的关键信息多抽或者少抽均算错误,最终得分取意图分类和关键信息抽取的平均值;预测过程中不得进行语种转换,必须使用测试集提供的语种直接进行意图分类和关键信息抽取任务。
四、准备阶段
1、报名比赛
import pandas as pd
import numpy as np
train_cn = pd.read_excel('汽车领域多语种迁移学习挑战赛初赛公开数据_A榜/汽车领域多语种迁移学习挑战赛初赛训练集/中文_trian.xlsx')
train_ja = pd.read_excel('汽车领域多语种迁移学习挑战赛初赛公开数据_A榜/汽车领域多语种迁移学习挑战赛初赛训练集/日语_train.xlsx')
train_en = pd.read_excel('汽车领域多语种迁移学习挑战赛初赛公开数据_A榜/汽车领域多语种迁移学习挑战赛初赛训练集/英文_train.xlsx')
test_ja = pd.read_excel('汽车领域多语种迁移学习挑战赛初赛公开数据_A榜/testA.xlsx', sheet_name='日语_testA')
test_en = pd.read_excel('汽车领域多语种迁移学习挑战赛初赛公开数据_A榜/testA.xlsx', sheet_name='英文_testA')
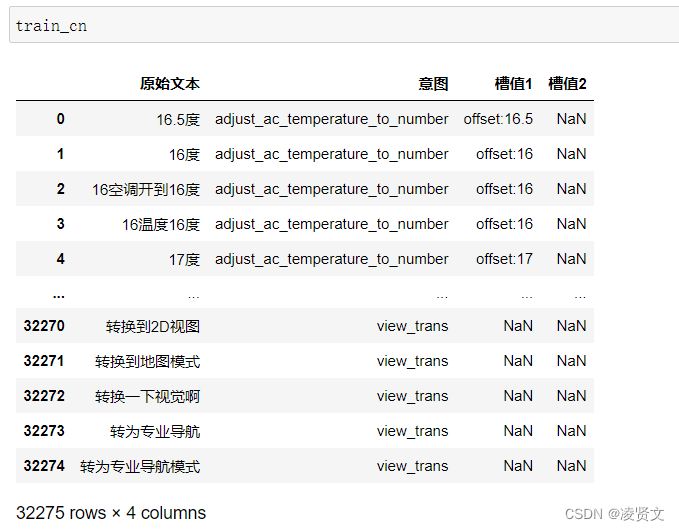
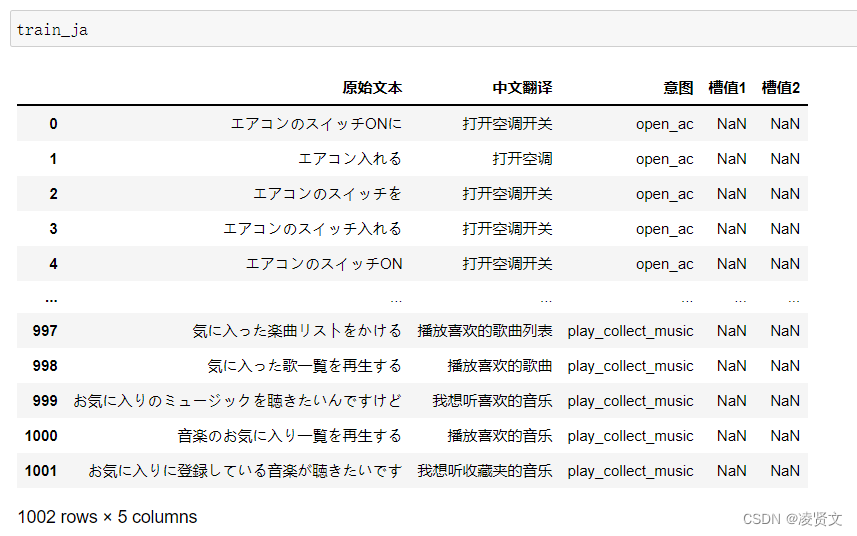
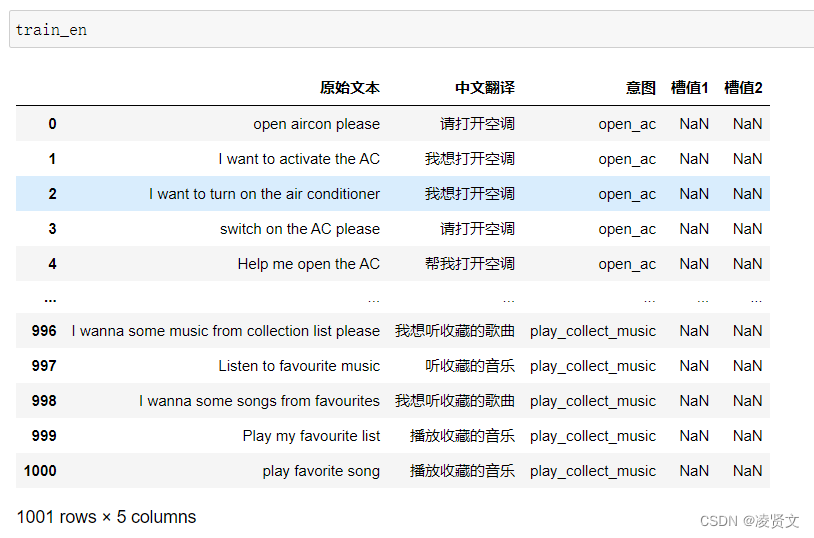
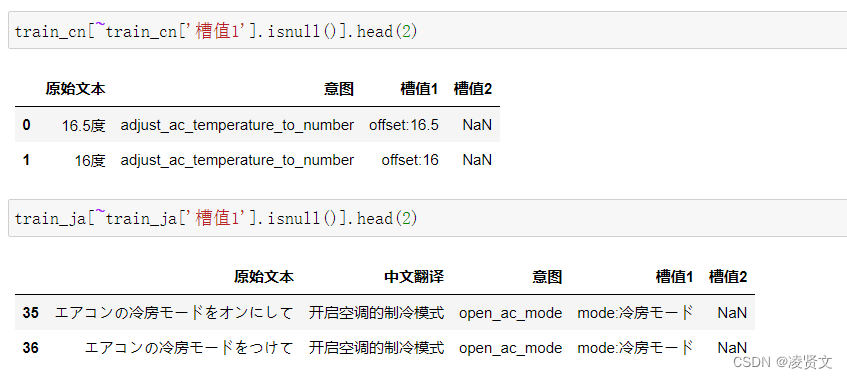

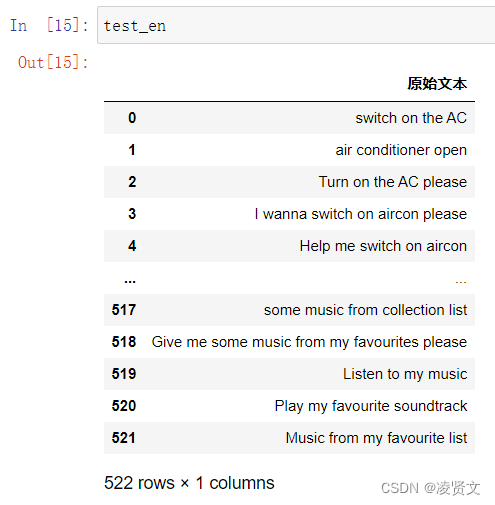
2、查看训练集和测试集字段类型

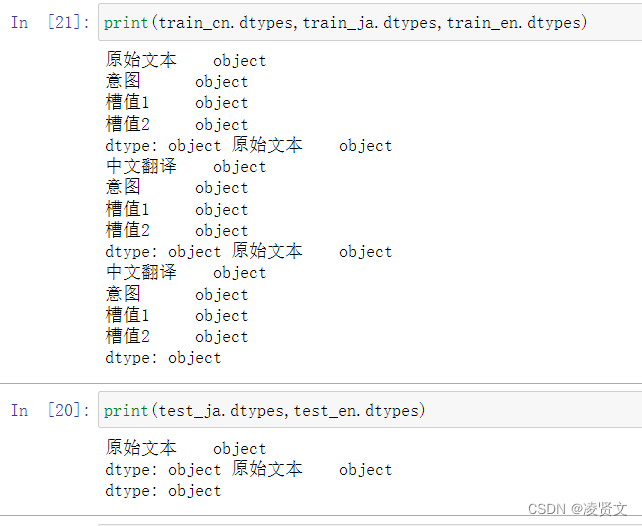
这里用info也可以。注意加(),【info和info()不一样】。
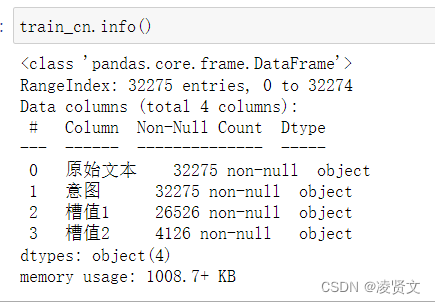
五、文本分析与文本分词
1、使用jieba对中文进行分词
import jieba
def cutword(txt):
return jieba.lcut(txt)
train_cn['phase'] = train_cn['原始文本'].apply(cutword)
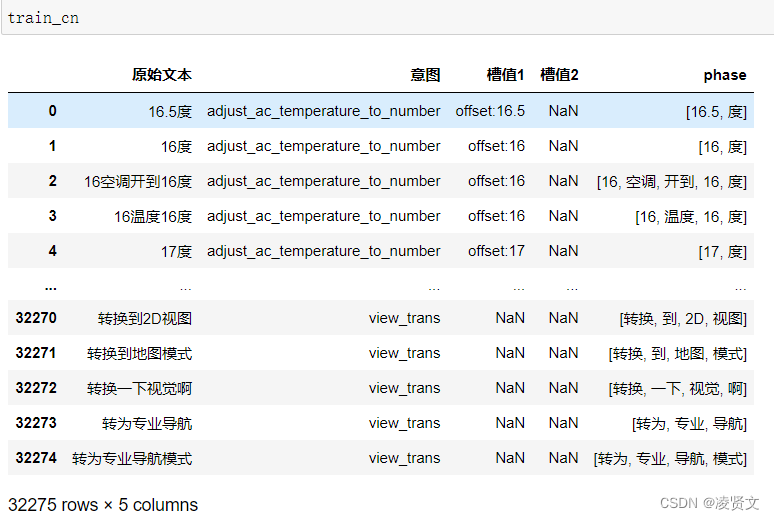
2、使用negisa对日语进行分词
!pip install nagisa
安装对应的negisa库。

import nagisa
def cutword_ja(txt):
words = nagisa.tagging(txt)
return words.words
train_ja['phase'] = train_ja['原始文本'].apply(cutword_ja)
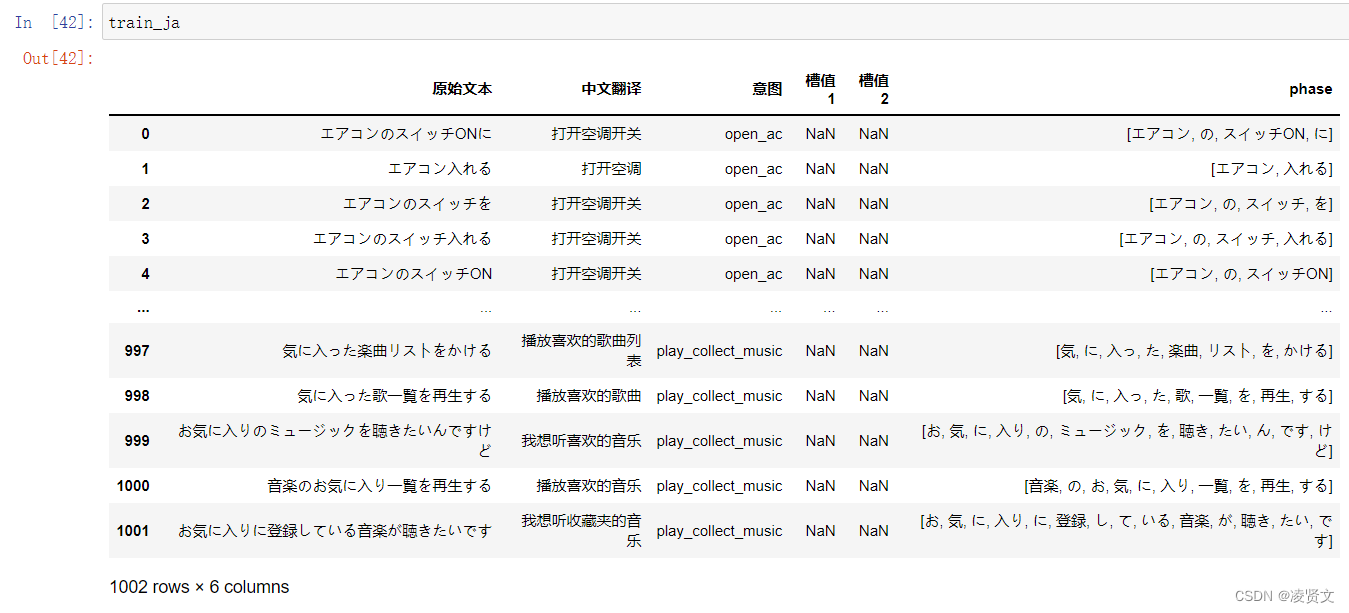
六、TFIDF与文本分类
1、使用TFIDF,提取语料的TFIDF特征
TF-IDF是Term Frequency - Inverse Document Frequency的缩写,即“词频——逆文本频率”。它由两部分组成,TF和IDF,也就是这两部分的乘积。
TF指的就是常用的词频。IDF,即“逆文本频率”。
TF-IDF的主要思想:如果一个词或短语在某一篇文章中出现的概率很高,并且在其它文章中很少出现,则认为该词或短语具有很好的类别区分能力,适合用来分类。
TF-IDF的作用:用以评估一个词语对于一个文件或者一个语料库中的其中一份文件的重要程度。
TF-IDF=TF*IDF #衡量一个词语的重要程度
把提取特征和逻辑回归一起构建成一个pipeline,一起进行训练。
2、用LR结合TFIDF进行训练(所有的语言语料),并对测试集的意图进行分类
# 训练TFIDF和逻辑回归
pipline = make_pipeline(
TfidfVectorizer(),
LogisticRegression()
)
pipline.fit(
train_ja['words'].tolist() + train_en['words'].tolist(),
train_ja['意图'].tolist() + train_en['意图'].tolist()
)
# 模型预测
test_ja['意图'] = pipline.predict(test_ja['words'])
test_en['意图'] = pipline.predict(test_en['words'])
test_en['槽值1'] = np.nan
test_en['槽值2'] = np.nan
test_ja['槽值1'] = np.nan
test_ja['槽值2'] = np.nan
# 写入提交文件
writer = pd.ExcelWriter('submit.xlsx')
test_en.drop(['words'], axis=1).to_excel(writer, sheet_name='英文_testA', index=None)
test_ja.drop(['words'], axis=1).to_excel(writer, sheet_name='日语_testA', index=None)
writer.save()
writer.close()
3、实验结果

不太行,有点低啊。
七、正则表达式
1、用正则表达式提取文本中的连续数值
使用正则表达式来提取字符串中的槽值,但是这个在不同语言是不一样的,而且对于不同的意图,还要单独处理,相对来说,是不推荐使用的,但是学习是ok的。
在python中,有专门的re包可以负责干这个事,它常常配合request、bs4等模块,完成一些爬虫工作。
import re
train_cn['num'] = train_cn['原始文本'].map(lambda x: re.findall("\d+", x))
train_ja['num'] = train_cn['原始文本'].map(lambda x: re.findall("[一|二|三|四|五|六|七|八|九|十]+",x))

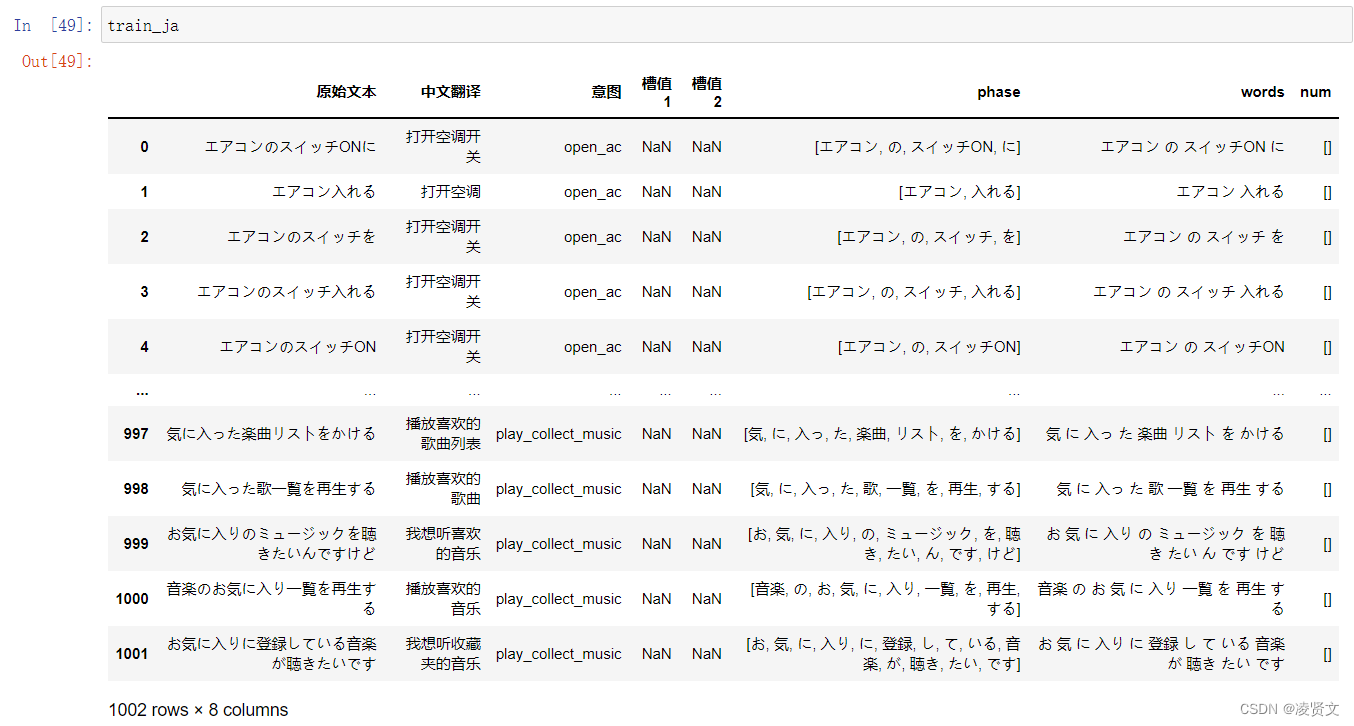
2、用正则表达式进行槽值匹配(基于历史的槽值字符串)
关于正则表达式还有待学习。
正则表达式 – 教程 | 菜鸟教程
正则表达式(Regular Expression)是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符")。
正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。
def getcaozhi_offset(txt):
num_l = get_num_last(txt)
if len(num_l) > 0:
return "offset:" + num_l[-1]
else:
return np.nan
train_cn['槽值_test'] = np.nan
for i in range(len(train_cn)):
#以意图作为条件,分别进行正则,来提取槽值
if train_cn.iloc[i, 1] == "adjust_ac_temperature_to_number":
train_cn['槽值_test'][i] = getcaozhi_offset(train_cn.iloc[i, 0])
print(train_cn)
以意图作为条件,分别进行正则,来提取槽值。
八、BERT模型入门
1、学习transformers库中pipline和加载模型的过程
使用预训练模型最简单的方法就是使用pipeline(),transformers提供了一些任务:
1、情感分析(Sentment analysis):分析文本是正面的还是负面的。
2、文本生成(in English):提供一个语句,模型将生成这条语句的下一句。3、命名实体识别(NER):在输入的语句中,对每个单词进行标记,来揭示该单词的含义(比如人物、地点等等)。
4、问题回答:输入一段文本以及一个问题,来从文本中抽取出这个问题的答案。
5、填补被遮蔽的文本:输入一段文本,其中一些单词被[MASK]标签取代,模型填补这些被遮蔽的文本。
6、摘要生成:产生一段长文本的摘要。
7、翻译:将一种语言的文本翻译成另一种语言。
8、特征抽取:得到一段文本的tensor表示。
这里使用Models - Hugging Face来学习NLP模型,这个库包含了大量的目前流行的预训练模型,我们只需几行代码,便可下载并应用,后面再根据实际数据做下游任务的微调。
Hugging face 提供的 transformers 库主要用于预训练模型的载入,需要载入三个基本对象:
from transformers import BertConfig
from transformers import BertModel
from transformers import BertTokenizer
(1)BertConfig
是该库中模型配置的 class:控制模型的名称、最终输出的样式、隐藏层宽度和深度、激活函数的类别等。将Config类导出时文件格式为 json 格式。格式如下:
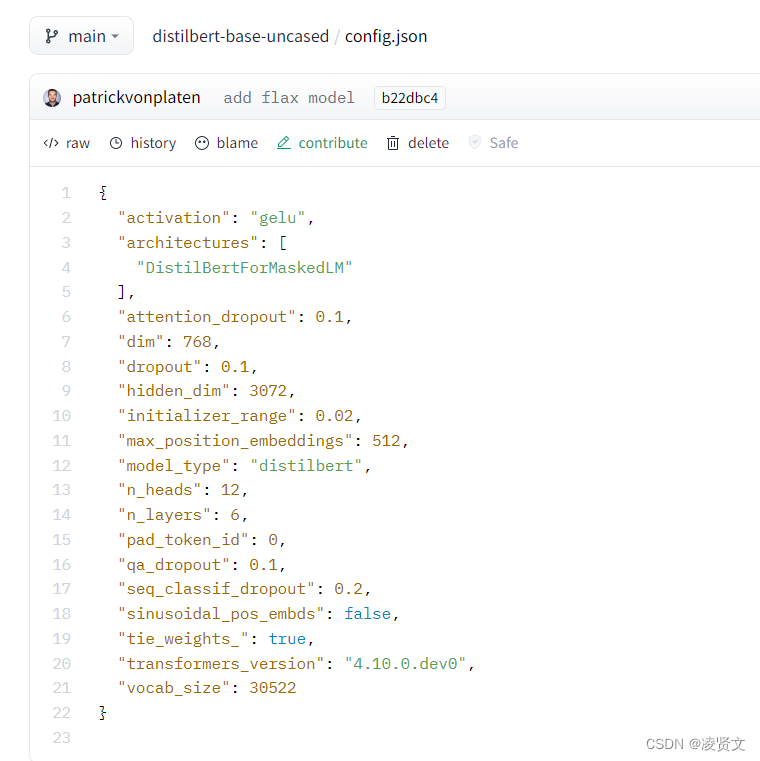
当然,也可以通过 config.json 来实例化 Config 类,这是一个互逆的过程。
(2)Model
也就是各种各样的模型:除了初始的 Bert、GPT 等基本模型,针对下游任务,还有其它的继承 BertPreTrainedModel 的派生类,对应不同的 Bert 任务,定义了 BertForQuestionAnswering、BertForNextSentencePrediction 以及 BertForSequenceClassification 等下游任务模型。模型导出时将生成 config.json 和 pytorch_model.bin 参数文件。前者就是 1 中的配置文件,这和我们的直觉相同,即 config 和 model 应该是紧密联系在一起的两个类。后者其实和 torch.save() 存储得到的文件是相同的,这是因为 Model 都直接或者间接继承了 Pytorch 的 Module 类。从这里可以看出,HuggingFace 在实现时很好地尊重了 Pytorch 的原生 API。
3)Tokenizer
这是一个将纯文本转换为编码的过程。注意,Tokenizer 并不涉及将词转化为词向量的过程,仅仅是将纯文本分词,添加[MASK]标记、[SEP]、[CLS]标记,并转换为字典索引。
这一部分引用http://t.csdn.cn/xD9pA
1、BERT 模型
BidirectionalEncoder Representations from Transformer。从名字中可以看出,BERT 模型的目标是利用大规模无标注语料训练、获得文本的包含丰富语义信息的 Representation,即:文本的语义表示,然后将文本的语义表示在特定NLP任务中作微调,最终应用于该NLP任务。举个栗子,BERT模型训练文本语义表示的过程就好比我们在高中阶段学习语数英、物化生等各门基础学科,夯实基础知识;而模型在特定NLP任务中的参数微调就相当于我们在大学期间基于已有基础知识、针对所选专业作进一步强化,从而获得能够应用于实际场景的专业技能。
- 模型结构
BERT 模型是基于 Transformer 的Encoder,主要模型结构就是Transformer的堆叠。
当我们组建好Bert模型之后,只要把对应的token喂给BERT,每一层Transformer层吐出相应数量的hidden vector,一层层传递下去,直到最后输出。模型就这么简单,专治花里胡哨,这大概就是谷歌的暴力美学。

Attention(Self-Attention、Multi-head Self-Attention)、Transformer Encoder。
- 模型的输入/输出
在基于深度神经网络的NLP方法中,文本中的字/词通常都用一维向量来表示(一般称之为“词向量”);在此基础上,神经网络会将文本中各个字或词的一维词向量作为输入,经过一系列复杂的转换后,输出一个一维词向量作为文本的语义表示。特别地,我们通常希望语义相近的字/词在特征向量空间上的距离也比较接近,如此一来,由字/词向量转换而来的文本向量也能够包含更为准确的语义信息。
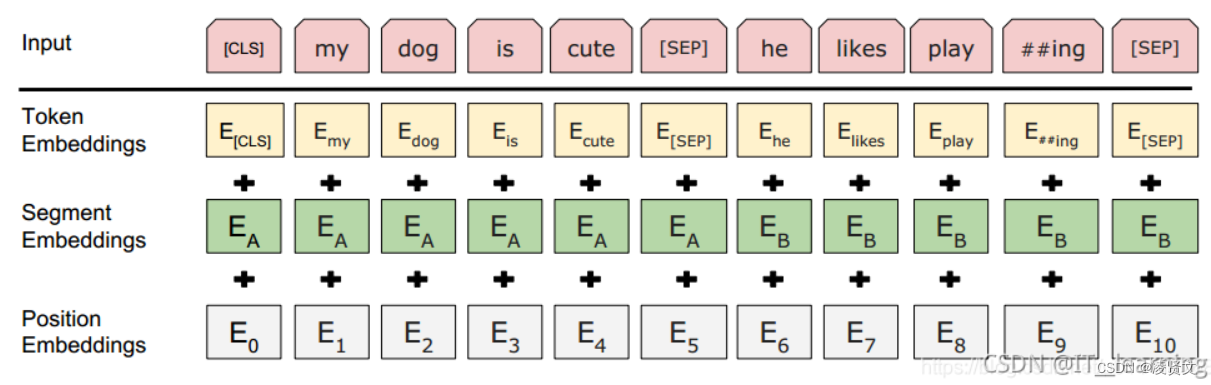
在BERT中,输入的向量是由三种不同的embedding求和而成,分别是:
1)wordpiece embedding:单词本身的向量表示。WordPiece是指将单词划分成一组有限的公共子词单元,能在单词的有效性和字符的灵活性之间取得一个折中的平衡。
2)position embedding:将单词的位置信息编码成特征向量。因为我们的网络结构没有RNN 或者LSTM,因此我们无法得到序列的位置信息,所以需要构建一个position embedding。构建position embedding有两种方法:BERT是初始化一个position embedding,然后通过训练将其学出来;而Transformer是通过制定规则来构建一个position embedding
3)segment embedding:用于区分两个句子的向量表示。这个在问答等非对称句子中是用区别的。BERT模型的输入就是wordpiece token embedding + segment embedding + position embedding
sequence_output, pooled_output, (hidden_states), (attentions)
bert 的输出是由四部分组成:
(1)last_hidden_state:shape是(batch_size, sequence_length, hidden_size),hidden_size=768,它是模型最后一层输出的隐藏状态。(通常用于命名实体识别)
(2)pooler_output:shape是(batch_size, hidden_size),这是序列的第一个token(classification token)的最后一层的隐藏状态,它是由线性层和Tanh激活函数进一步处理的。(通常用于句子分类,至于是使用这个表示,还是使用整个输入序列的隐藏状态序列的平均化或池化,视情况而定)
(3)hidden_states:这是输出的一个可选项,如果输出,需要指定config.output_hidden_states=True,它也是一个元组,它的第一个元素是embedding,其余元素是各层的输出,每个元素的形状是(batch_size, sequence_length, hidden_size)
(4)attentions:这也是输出的一个可选项,如果输出,需要指定config.output_attentions=True,它也是一个元组,它的元素是每一层的注意力权重,用于计算self-attention heads的加权平均值。
2、从模型库导入 Bert 预训练模型
打开Hugging Face,找到Bert预训练模型。

from huggingface_hub import snapshot_download
snapshot_download(repo_id="hfl/chinese-roberta-wwm-ext") #id填你想要下载的模型名称,要和官网上的一致
使用代码下载模型,不然可能会报错。
2、学习transformers库的使用:包括定义数据集,定义模型和训练模型
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# AutoTokenizer:分词器
# Auto:自动识别的
model_name = "bert-base-chinese"
pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
from transformers import AutoTokenizer, AutoModelForMaskedLM, AutoConfig, BertModel, AutoModel
model = AutoModel.from_pretrained("hfl/chinese-roberta-wwm-ext")
inputs = tokenizer(["把闭锁自动升窗功能关闭。", "帮我查询附近国家电网充电站"], truncation=True, max_length=20, padding=True)
print(inputs)
# input_ids:这个字在vocab次序
# token_type_ids:字符是第一个句子的,还是第二个句子的
# attention_mask:字符是不是padding的
import torch
item = {key: torch.tensor(inputs[key]).view(1, -1) for key, val in inputs.items()}
output = model(input_ids = item['input_ids'], attention_mask = item['attention_mask'])
print(output)
print(output.last_hidden_state.shape, output.pooler_output.shape)
九、BERT文本分类
1、使用BERT完成意图识别
for tag in ['intent', 'device', 'mode', 'offset', 'endloc', 'landmark', 'singer', 'song']:
train_ja['槽值1'] = train_ja['槽值1'].str.replace(f'{tag}:', '')
train_ja['槽值2'] = train_ja['槽值2'].str.replace(f'{tag}:', '')
train_cn['槽值1'] = train_cn['槽值1'].str.replace(f'{tag}:', '')
train_cn['槽值2'] = train_cn['槽值2'].str.replace(f'{tag}:', '')
train_en['槽值1'] = train_en['槽值1'].str.replace(f'{tag}:', '')
train_en['槽值2'] = train_en['槽值2'].str.replace(f'{tag}:', '')
train_df = pd.concat([
train_ja[['原始文本', '意图', '槽值1', '槽值2']],
train_cn[['原始文本', '意图', '槽值1', '槽值2']],
#train_cn[['原始文本', '意图', '槽值1', '槽值2']].sample(10000),
train_en[['原始文本', '意图', '槽值1', '槽值2']],
],axis = 0)
train_df = train_df.sample(frac=1.0)
train_df['意图_encode'], lbl_ecode = pd.factorize(train_df['意图'])
from torch.utils.data import Dataset, DataLoader, TensorDataset
import torch
from torch import nn
from torch.nn import CrossEntropyLoss
from torch.optim import AdamW
# 数据集读取
class Load_Dataset(Dataset):
def __init__(self, encodings, intent):
self.encodings = encodings
self.intent = intent
# 读取单个样本
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['label'] = torch.tensor(int(self.intent[idx]))
return item
def __len__(self):
return len(self.intent)
class Model(nn.Module):
def __init__(self, num_labels):
super(Model,self).__init__()
self.model = model = AutoModel.from_pretrained("bert-base-multilingual-cased")
self.dropout = nn.Dropout(0.1)
self.classifier = nn.Linear(768, num_labels)
def forward(self, input_ids=None, attention_mask=None,labels=None):
outputs = self.model(input_ids=input_ids, attention_mask=attention_mask)
sequence_output = self.dropout(outputs[0]) #outputs[0]=last hidden state
logits = self.classifier(sequence_output[:,0,:].view(-1,768))
return logits
def train():
model.train()
total_train_loss = 0
iter_num = 0
total_iter = len(train_loader)
for batch in train_loader:
# 正向传播
optim.zero_grad()
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
label = batch['label'].to(device)
pred = model(
input_ids,
attention_mask
)
loss = loss_fn(pred, label)
# 反向梯度信息
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
# 参数更新
optim.step()
iter_num += 1
if(iter_num % 100 == 0):
print("iter_num: %d, loss: %.4f, %.2f%% %.4f" % (
iter_num, loss.item(), iter_num/total_iter*100,
(pred.argmax(1) == label).float().data.cpu().numpy().mean(),
))
def validation():
model.eval()
label_acc = 0
for batch in val_dataloader:
with torch.no_grad():
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
label = batch['label'].to(device)
pred = model(
input_ids,
attention_mask
)
label_acc += (pred.argmax(1) == label).float().sum().item()
label_acc = label_acc / len(val_dataloader.dataset)
print("-------------------------------")
print("Accuracy: %.4f" % (label_acc))
print("-------------------------------")
tokenizer = AutoTokenizer.from_pretrained("bert-base-multilingual-cased")
config = AutoConfig.from_pretrained("bert-base-multilingual-cased")
train_encoding = tokenizer(train_df['原始文本'].tolist()[:-500], truncation=True, padding=True, max_length=40)
val_encoding = tokenizer(train_df['原始文本'].tolist()[-500:], truncation=True, padding=True, max_length=40)
train_dataset = Load_Dataset(train_encoding, train_df['意图_encode'].tolist()[:-500])
val_dataset = Load_Dataset(val_encoding, train_df['意图_encode'].tolist()[-500:])
# 单个读取到批量读取
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=16, shuffle=False)
model = Model(18)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# device = 'cpu'
model = model.to(device)
loss_fn = CrossEntropyLoss() # ingore index = -1
optim = AdamW(model.parameters(), lr=5e-5)
for epoch in range(2):
train()
validation()
def prediction():
model.eval()
test_label = []
for batch in test_dataloader:
with torch.no_grad():
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
pred = model(input_ids, attention_mask)
test_label += list(pred.argmax(1).data.cpu().numpy())
return test_label
test_encoding = tokenizer(test_en['原始文本'].tolist(), truncation=True, padding=True, max_length=40)
test_dataset = Load_Dataset(test_encoding, [0] * len(test_en))
test_dataloader = DataLoader(test_dataset, batch_size=16, shuffle=False)
test_en_intent = prediction()
test_encoding = tokenizer(test_ja['原始文本'].tolist(), truncation=True, padding=True, max_length=40)
test_dataset = Load_Dataset(test_encoding, [0] * len(test_ja))
test_dataloader = DataLoader(test_dataset, batch_size=16, shuffle=False)
test_ja_intent = prediction()
test_ja['意图'] = [lbl_ecode[x] for x in test_ja_intent]
test_en['意图'] = [lbl_ecode[x] for x in test_en_intent]
test_en['槽值1'] = np.nan
test_en['槽值2'] = np.nan
test_ja['槽值1'] = np.nan
test_ja['槽值2'] = np.nan
writer = pd.ExcelWriter('submit.xlsx')
test_en[['意图', '槽值1', '槽值2']].to_excel(writer, sheet_name='英文_testA', index=None)
test_ja[['意图', '槽值1', '槽值2']].to_excel(writer, sheet_name='日语_testA', index=None)
writer.save()
writer.close()
2、实验结果
iter_num: 100, loss: 0.8919, 13.91% 0.6250
iter_num: 200, loss: 0.3708, 27.82% 0.8750
iter_num: 300, loss: 0.3024, 41.72% 0.9375
iter_num: 400, loss: 0.2056, 55.63% 0.8750
iter_num: 500, loss: 0.0389, 69.54% 1.0000
iter_num: 600, loss: 1.5263, 83.45% 0.6875
iter_num: 700, loss: 0.2882, 97.36% 0.9375
Accuracy: 0.9380
iter_num: 100, loss: 0.0069, 13.91% 1.0000
iter_num: 200, loss: 0.2506, 27.82% 0.9375
iter_num: 300, loss: 1.1997, 41.72% 0.7500
iter_num: 400, loss: 0.0121, 55.63% 1.0000
iter_num: 500, loss: 0.0082, 69.54% 1.0000
iter_num: 600, loss: 0.0483, 83.45% 1.0000
iter_num: 700, loss: 0.3702, 97.36% 0.8750
Accuracy: 0.9700
版权归原作者 Lingxw_w 所有, 如有侵权,请联系我们删除。