
Bert+LSTM+CRF命名实体识别
从0开始解析源代码。
- 理解原代码的逻辑,具体了解为什么使用预训练的bert,bert有什么作用,网络的搭建是怎么样的,训练过程是怎么训练的,输出是什么
- 调试运行源代码
NER目标
NER是named entity recognized的简写,对人名、地名、机构名、日期时间、专有名词等进行识别。
结果输出标注方法
采用细粒度标注,就是对于每一个词都给一个标签,其中连续的词可能是一个标签,与原始数据集的结构不同,需要对数据进行处理,转化成对应的细粒度标注形式。
数据集形式修改
形式:
{"text":"浙商银行企业信贷部叶老桂博士则从另一个角度对五道门槛进行了解读。叶老桂认为,对目前国内商业银行而言,","label":{"name":{"叶老桂":[[9,11],[32,34]]},"company":{"浙商银行":[[0,3]]}}}
修改后数据集对应格式:
sentence:['温','格','的','球','队','终','于','又','踢','了','一','场','经','典','的','比','赛',',','2','比','1','战','胜','曼','联','之','后','枪','手','仍','然','留','在','了','夺','冠','集','团','之','内',',']
label:['B-name','I-name','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','B-organization','I-organization','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O']
数据预处理
对于一个句子不进行分词,原因是NER为序列标注任务,需要确定边界,分词后就可能产生错误的分词结果影响效果(B-x,I-x这种连续性,分词后会影响元意思表达)。
defpreprocess(self, mode):"""
params:
words:将json文件每一行中的文本分离出来,存储为words列表
labels:标记文本对应的标签,存储为labels
examples:
words示例:['生', '生', '不', '息', 'C', 'S', 'O', 'L']
labels示例:['O', 'O', 'O', 'O', 'B-game', 'I-game', 'I-game', 'I-game']
"""
np.savez_compressed(output_dir, words=word_list, labels=label_list)
保存的文件也还是一句是一句的,所以后续处理中只有CLS,不需要终止符。
数据集分集与分batch
defdev_split(dataset_dir):"""split dev set"""
data = np.load(dataset_dir, allow_pickle=True)#加载npz文件
words = data["words"]
labels = data["labels"]
x_train, x_dev, y_train, y_dev = train_test_split(words, labels, test_size=config.dev_split_size, random_state=0)return x_train, x_dev, y_train, y_dev
调用train_test_split实现分train和dev的数据集。
将数据转化形式,用idx表示,构造NERDataset类表示使用数据集
def__init__(self, words, labels, config, word_pad_idx=0, label_pad_idx=-1):
self.tokenizer = BertTokenizer.from_pretrained(config.bert_model, do_lower_case=True)#调用预训练模型
self.label2id = config.label2id#字典
self.id2label ={_id: _label for _label, _id inlist(config.label2id.items())}##字典
self.dataset = self.preprocess(words, labels)#数据集预处理
self.word_pad_idx = word_pad_idx
self.label_pad_idx = label_pad_idx
self.device = config.device
defpreprocess(self, origin_sentences, origin_labels):"""
Maps tokens and tags to their indices and stores them in the dict data.
examples:
word:['[CLS]', '浙', '商', '银', '行', '企', '业', '信', '贷', '部']
sentence:([101, 3851, 1555, 7213, 6121, 821, 689, 928, 6587, 6956],
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9]))
label:[3, 13, 13, 13, 0, 0, 0, 0, 0]
"""
data =[]
sentences =[]
labels =[]# eg. i am cutting tokenize: cutting->[cut,'##ing']自动修改形式变成单数或者恢复原型for line in origin_sentences:# replace each token by its index# we can not use encode_plus because our sentences are aligned to labels in list type
words =[]
word_lens =[]for token in line:
words.append(self.tokenizer.tokenize(token))
word_lens.append(len(token))#如果含有英文会出现上面的情况,中文没有分词一般是1#>> [1]*9# 变成单个字的列表,开头加上[CLS]
words =['[CLS]']+[item for token in words for item in token]
token_start_idxs =1+ np.cumsum([0]+ word_lens[:-1])# np.array:[1,2,3] 自动广播机制 每个+1 a[1,2,3] a[:-1]->[1,2] 求出每个词在没加【cls】的句首字母idx# 这里计数tokens在words中的索引,第一个起始位置+1(加了cls)了,所以每一个+1
sentences.append((self.tokenizer.convert_tokens_to_ids(words), token_start_idxs))#单词转化成idx,直接调用函数即可for tag in origin_labels:
label_id =[self.label2id.get(t)for t in tag]#单个句子的tag idx
labels.append(label_id)for sentence, label inzip(sentences, labels):
data.append((sentence, label))#句子编码、token在words中的位置、对应的label(一个token可能占用多个word(cutting->cut+ing)return data
preprocess
处理token和word,记录每个token在word中的起始位置用于后续的对齐,对于每个单词进行tokennize(中文无变化,英文可能会有,但数据处理过程中将单词分成字母,所以无影响),然后在句首加上开始字符,因为生成第一个单词也需要概率因此句首不能省略,然后就是将字符转化成idx存储,tag也转化成idx;
类中的功能函数
def__getitem__(self, idx):#class使用索引"""sample data to get batch"""
word = self.dataset[idx][0]
label = self.dataset[idx][1]return[word, label]def__len__(self):#class 使用长度"""get dataset size"""returnlen(self.dataset)
可以索引访问与访问长度。
encode_plus可以直接编码,但这里不能使用:align限制
因为单词要和标签对应,直接tokennize后编码,不能确定与标签的对应关系;
tokennize()
对于英文一个token通过tokennize会得到多个word:cutting->cut+##ing;
np.cumsum(a)累计计数
[1,1,1]--->[1,2,3]
模型架构
首先要明确,是继承bert基类,然后自定义forward函数就建好网络了,基本结构试:
classModule(nn.Module):def__init__(self):super(Module, self).__init__()# ......defforward(self, x):# ......return x
data =.....#输入数据# 实例化一个对象
module = Module()# 前向传播
module(data)# 而不是使用下面的# module.forward(data)
关于forward的解释
nn.module中实现时就在call函数中定义了调用forward,然后传参就自动调用了。
定义__call__方法的类可以当作函数调用,具体参考Python的面向对象编程。也就是说,当把定义的网络模型model当作函数调用的时候就自动调用定义的网络模型的forward方法。nn.Module 的__call__方法部分源码如下所示:
def__call__(self,*input,**kwargs): result = self.forward(*input,**kwargs)
BERT模式:选择对应,在代码的不同部分都有切换(model.eval();model.train())
- train
- eval
- predict
nonezero()函数
a = mat([[1,1,0],[1,1,0],[1,0,3]])print(a.nonzero())#>>(array([0, 0, 1, 1, 2, 2], dtype=int64), array([0, 1, 0, 1, 0, 2], dtype=int64))
squeeze()函数介绍
去掉为1的维度,如
[[0,1,2],[1,2,3]]dim(1,2,3)-->squeeze(1)--->[[0,1,2].[1,2,3]]
CRF层训练
训练目标:lstm输出分数+转移分数+前面序列的累计转移分数也就是 emission Score和transition Score(ref),函数使用,初始设置只需要标签数目,后续forward需要batch;如果想要知道结果需要使用
decode
函数
>>>import torch
>>>from torchcrf import CRF
>>> num_tags =5# number of tags is 5>>> model = CRF(num_tags)
emissions = torch.randn(seq_length, batch_size, num_tags)#初始输入>>> model(emissions, tags, mask=mask)
tensor(-10.8390, grad_fn=<SumBackward0>)#得到这个句子的概率#没有tag预测>>> model.decode(emissions)[[3,1,3],[0,1,0]]
引用这个图:
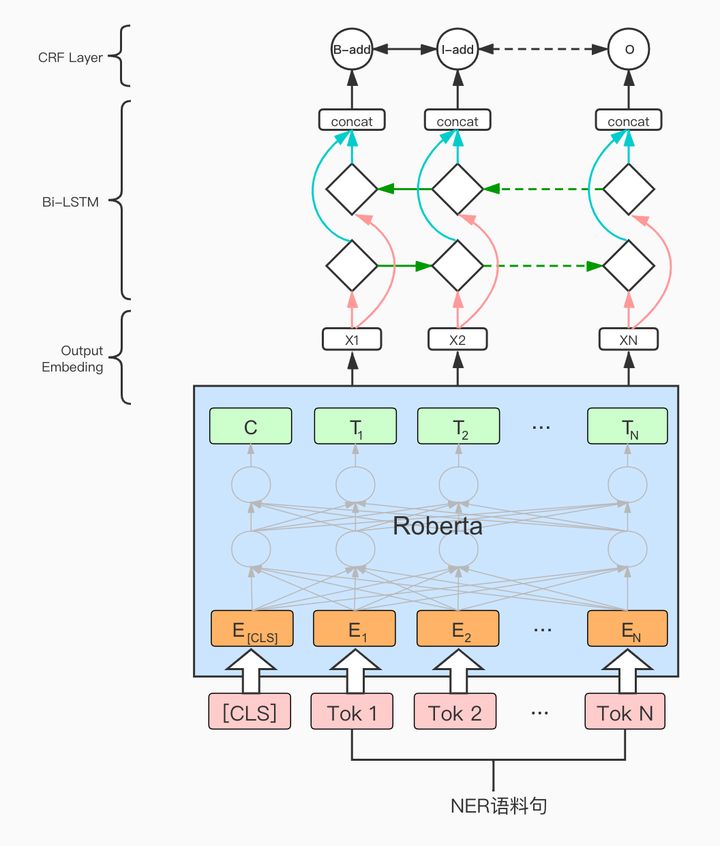
模型构造:
classBertNER(BertPreTrainedModel):def__init__(self, config):super(BertNER, self).__init__(config)
self.num_labels = config.num_labels
self.bert = BertModel(config)#第一层
self.dropout = nn.Dropout(config.hidden_dropout_prob)#非线性层
self.bilstm = nn.LSTM(#LSTM层
input_size=config.lstm_embedding_size,# 1024
hidden_size=config.hidden_size //2,# 1024 因为是双向LSTM,隐藏层大小为原来的一半
batch_first=True,
num_layers=2,
dropout=config.lstm_dropout_prob,# 0.5 非线性
bidirectional=True)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)#得到每个词对于所有tag的分数
self.crf = CRF(config.num_labels, batch_first=True)#CEF层
self.init_weights()#初始化权重,先全部随机初始化,然后调用bert的预训练模型中的权重覆盖
直接使用pytorch已经实现的函数,设置好bert层,后面通过droupout非线性层随机失活,然后使加上双向LSTM,注意双向的隐藏层是将两个方向的直接拼接,因此每个的长度设置为总的隐藏层输出长度的一半;然后接线性层,得到的是对于这些tag的每一个的分数,对于每一个位置,都给出是n钟tag的分数,这些分数作为crf层得到输入;然后进入crf层;
初始化权重:对于预训练模型,已经有的参数直接加载,没有的参数将随机初始化。
设置前向传播训练,:
defforward(self, input_data, token_type_ids=None, attention_mask=None, labels=None,
position_ids=None, inputs_embeds=None, head_mask=None):
input_ids, input_token_starts = input_data
outputs = self.bert(input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds)
sequence_output = outputs[0]# 去除[CLS]标签等位置,获得与label对齐的pre_label表示
origin_sequence_output =[layer[starts.nonzero().squeeze(1)]for layer, starts inzip(sequence_output, input_token_starts)]# 将sequence_output的pred_label维度padding到最大长度
padded_sequence_output = pad_sequence(origin_sequence_output, batch_first=True)# dropout pred_label的一部分feature
padded_sequence_output = self.dropout(padded_sequence_output)
lstm_output, _ = self.bilstm(padded_sequence_output)# 得到判别值
logits = self.classifier(lstm_output)
outputs =(logits,)if labels isnotNone:#如果标签存在就计算loss,否则就是输出线性层对应的结果,这样便于通过后续crf的decode函数解码得到预测结果。
loss_mask = labels.gt(-1)
loss = self.crf(logits, labels, loss_mask)*(-1)
outputs =(loss,)+ outputs
# contain: (loss), scoresreturn outputs
如果标签存在就计算loss,否则就是输出线性层对应的结果,这样便于通过后续crf的decode函数解码得到预测结果。在
train.py/evaluate()
里面用到了:
batch_output = model((batch_data, batch_token_starts),
token_type_ids=None, attention_mask=batch_masks)[0]#没有标签只会得到线性层的输出# (batch_size, max_len - padding_label_len)
batch_output = model.crf.decode(batch_output, mask=label_masks)#得到预测的标签
各个层的作用为:
bert
提供词的嵌入表示,通过大规模训练,得到的结果泛化性更强,因此使用预训练模型,然参数有个比较好的初始化值。
lstm
从这里开始是正式的模型内容,这里是双向lstm,能够学习句子的上下文内容,从而给出每个字的标注。
crf
由于原始句法约束,lstm没有学习到原始的句法约束,因此使用条件随机场crf层来限制句法要求,从而加强结果。loss为发射分数和转移分数统一的分数,越小越好
验证
使用f1 score,兼顾了分类模型的精确率和召回率,最大为1,最小为0,越大越好。
模型训练
训练时采用patience_counter策略,如果连续patience_counter次f1值没有提升,而且已经达到了最小训练次数,训练停止,代码实现为:
deftrain(train_loader, dev_loader, model, optimizer, scheduler, model_dir):"""train the model and test model performance"""# reload weights from restore_dir if specifiedif model_dir isnotNoneand config.load_before:
model = BertNER.from_pretrained(model_dir)
model.to(config.device)
logging.info("--------Load model from {}--------".format(model_dir))
best_val_f1 =0.0#最小值
patience_counter =0#超过这个次数 f1值连续没有提升而且已经过了最小训练次数就终止# start trainingfor epoch inrange(1, config.epoch_num +1):
train_epoch(train_loader, model, optimizer, scheduler, epoch)
val_metrics = evaluate(dev_loader, model, mode='dev')#验证
val_f1 = val_metrics['f1']#得到f1值
logging.info("Epoch: {}, dev loss: {}, f1 score: {}".format(epoch, val_metrics['loss'], val_f1))
improve_f1 = val_f1 - best_val_f1#控制精度连续提升if improve_f1 >1e-5:
best_val_f1 = val_f1
model.save_pretrained(model_dir)
logging.info("--------Save best model!--------")if improve_f1 < config.patience:
patience_counter +=1else:
patience_counter =0else:
patience_counter +=1# Early stopping and logging best f1if(patience_counter >= config.patience_num and epoch > config.min_epoch_num)or epoch == config.epoch_num:
logging.info("Best val f1: {}".format(best_val_f1))break
logging.info("Training Finished!")
参数更新,学习率衰减
采用学习率分离,adamW优化采纳数,动态调整学习率的策略。
设置控制系数不衰减的项,然后
optimizer_grouped_parameters
要将全部的参数都写进去,注意写法的不同:crf层的参数学习率更高,而且写法不同是直接的parameters,见下文写法:
if config.full_fine_tuning:# model.named_parameters(): [bert, bilstm, classifier, crf]# 模型是哪个层中的参数
bert_optimizer =list(model.bert.named_parameters())
lstm_optimizer =list(model.bilstm.named_parameters())
classifier_optimizer =list(model.classifier.named_parameters())
no_decay =['bias','LayerNorm.bias','LayerNorm.weight']#控制系数不衰减的项
optimizer_grouped_parameters =[#其他参数在优化过程权重衰减{'params':[p for n, p in bert_optimizer ifnotany(nd in n for nd in no_decay)],#bert中衰减项参数'weight_decay': config.weight_decay},{'params':[p for n, p in bert_optimizer ifany(nd in n for nd in no_decay)],'weight_decay':0.0},#不衰减的也要写出来{'params':[p for n, p in lstm_optimizer ifnotany(nd in n for nd in no_decay)],#lstm层的系数'lr': config.learning_rate *5,'weight_decay': config.weight_decay},{'params':[p for n, p in lstm_optimizer ifany(nd in n for nd in no_decay)],'lr': config.learning_rate *5,'weight_decay':0.0},{'params':[p for n, p in classifier_optimizer ifnotany(nd in n for nd in no_decay)],#线性层参数'lr': config.learning_rate *5,'weight_decay': config.weight_decay},{'params':[p for n, p in classifier_optimizer ifany(nd in n for nd in no_decay)],'lr': config.learning_rate *5,'weight_decay':0.0},{'params': model.crf.parameters(),'lr': config.learning_rate *5}#crf层的参数学习率更高,而且写法不同是直接的parameters]# only fine-tune the head classifier 如果不微调也就是bert层全部使用原本的权重,不会根据数据集微调# 问题:预训练模型的参数只包含bert的?那么这里的lstm层为什么不训练;预训练模型,对照表,给定单词(有一个初始顺序)给出编码然后进入后续模型else:
param_optimizer =list(model.classifier.named_parameters())
optimizer_grouped_parameters =[{'params':[p for n, p in param_optimizer]}]
optimizer = AdamW(optimizer_grouped_parameters, lr=config.learning_rate, correct_bias=False)
train_steps_per_epoch = train_size // config.batch_size
scheduler = get_cosine_schedule_with_warmup(optimizer,
num_warmup_steps=(config.epoch_num //10)* train_steps_per_epoch,
num_training_steps=config.epoch_num * train_steps_per_epoch)# Train the model
logging.info("--------Start Training!--------")
train(train_loader, dev_loader, model, optimizer, scheduler, config.model_dir)
源代码这里不微调逻辑存有问题,原github已提交issue,暂时没有回应(没用到)
结果分析
f1score最终为0.79;
在书籍、公司、游戏、政府、人名上f1 score都大于0.8,效果较好;
原数据:
模型BiLSTM+CRFRoberta+SoftmaxRoberta+CRFRoberta+BiLSTM+CRFaddress47.3757.5064.1163.15book65.7175.3280.9481.45company71.0676.7180.1080.62game76.2882.9083.7485.57government71.2979.0283.1481.31movie67.5383.2383.1185.61name71.4988.1287.4488.22organization73.2974.3080.3280.53position72.3377.3978.9578.82scene51.1662.5671.3672.86****overall67.4775.9079.3479.64
这里使用的是bert预训练模型,可以看到从预训练模型上说,和
roberta
在各个数据上稍微差一些,但最后的差值和原本实验结果相近。
实验test时的bad—case分析

枪手这里系统错判为组织;
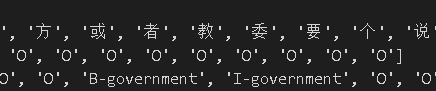
教委错判为政府;

彩票监管部门认为是政府,实际是组织;

中材中心认为是公司,实际是组织;
 枪手错判;
枪手错判;
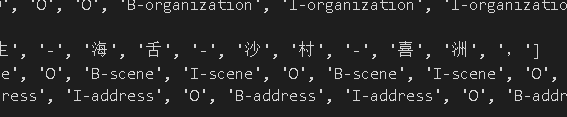 一些景点和地名分不清;
一些景点和地名分不清;
 以及这种
以及这种
可以看出由于有了条件随机场的限制,没有明显的B-peron后面跟I-name这种错误,出现的错误大都是内容上的,即使是人也不一定分清,可见这个模型的强大。
参考
是对文章里面不涉及的部分的进一步解析,适合小白开箱使用。
源码为:传送门
版权归原作者 Remember00000 所有, 如有侵权,请联系我们删除。