基于图的 Affinity Propagation 聚类计算公式详解和代码示例
Affinity Propagation Clustering(简称AP算法)是2007提出的,当时发表在Science上《single-exemplar-based》。特别适合高维、多类数据快速聚类,相比传统的聚类算法,该算法算是比较新的,从聚类性能和效率方面都有大幅度的提升。
手把手带你玩转Spark机器学习-使用Spark构建聚类模型
本文以Covid-19新冠肺炎的公开数据为例,为大家演示如何在Spark上进行空缺值处理、异常检测、去除重复项等预处理操作。同时为了直观了解过去一段时间内新冠肺炎病例演变情况,我们还引入geopandas来画一个比较酷炫的全球新冠肺炎地理热图,并通过coding将png图像转换成一个动态图片gif,
KMean算法精讲
KMeas算法是一种聚类算法,同时也是一种无监督的算法,即在训练模型时并不需要标签,其主要目的是通过循环迭代,将样本数据分成K类。
独孤九剑第七式-物以类聚 人以群分(K-means模型)
🐱文章适合于所有的相关人士进行学习🐱🐶各位看官看完了之后不要立刻转身呀🐶🐹期待三连关注小小博主加收藏🐹🐴小小博主回关快 会给你意想不到的惊喜呀🐴各位老板动动小手给小弟点赞收藏一下,多多支持是我更新得动力!!!文章目录🌀前言🌀K-means模型讲解⚡️K-means模型思想⚡️K-
机器学习—无监督学习(一)KMeans聚类
浅谈无监督学习—聚类:K-Means(1)
全面解析Kmeans聚类算法(Python)
Clustering (聚类) 是常见的unsupervised learning (无监督学习)方法,简单地说就是把相似的数据样本分到一组(簇),聚类的过程.我们并不清楚某一类是什么(通常无标签信息),需要实现的目标只是把相似的样本聚到一起,即只是利用样本数据本身的分布规律。在本文中,我将详细介绍
层次聚类算法的实现
目录1.作者介绍2.层次聚类算法介绍2.1 层次聚类算法原理2.2 层次聚类算法步骤2.3 层次聚类算法分类3.层次聚类算法实现(代码如下)3.1 相关包导入3.2 生成测试数据集3.3 层次聚类实现&画出树状图3.4 获取聚类结果3.5 对比不同方法聚类效果4.参考链接1.作者介绍杨金花,
(数据挖掘 —— 无监督学习(聚类)
数据挖掘 —— 无监督学习(聚类)1. K-means1.1 生成指定形状的随机数据1.2 进行聚类1.3 结果2. 系统聚类2.1 代码2.2 结果3 DBSCAN3.1 参数选择3.2 代码3.3 结果1. K-meansK-Means为基于切割的聚类算法1.1 生成指定形状的随机数据impo
聚类分析简述
聚类分析简述聚类分析概述层次聚类K-Means算法DBSCAN算法聚类分析概述聚类分析是一种无监督学习(无监督学习:机器学习中的一种学习方式,没有明确目的的训练方式,无法提前知道结果是什么;数据不需要标签标记),用于对未知类别的样本进行划分将它们按照一定的规则划分成若干个类簇,把相似(相关的)的样本
R语言KMeans聚类分析确定最优聚类簇数实战:间隙统计Gap Statistic(确定最优聚类簇数)
R语言KMeans聚类分析确定最优聚类簇数实战:间隙统计Gap Statistic(确定最优聚类簇数)目录R语言KMeans聚类分析确定最优聚类簇数实战:间隙统计Gap Statistic(确定最优聚类簇数)#仿真数据#间隙统计Gap Statistic(确定最优聚类簇数)#仿真数据n = 100g
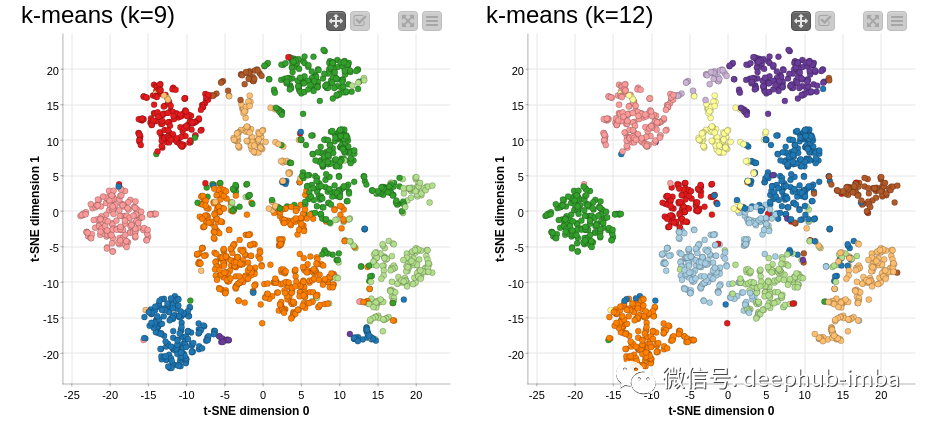
如何确定多少个簇?聚类算法中选择正确簇数量的三种方法
在本文中,首先介绍两个流行的指标来评估簇质量。然后介绍三种方法来找到最佳簇数量
K-means与DBSCAN聚类算法
K-means聚类算法与DBSCAN算法是聚类问题中的典型算法,本文通过流程图、Spss、以及伪代码等形式做一个分享,希望读者更好地了解这两种算法

RVN 一种新的聚类算法
RVN 的灵感来自一家家具公司的商业案例,由于每件家具都有不同的形状和大小,所以创建了可以考虑每个点大小的 RVN 算法
Python实验--手写KNN+PCA实现药品聚类和手写字识别
本实验以手写的KNN和PCA算法实现药品数据聚类和手写字识别
谱聚类算法
谱聚类算法小组作业
数据挖掘复习要点整理
复习要点:回归课本 个人总结仅供参考简答题:1. Apriori算法主要步骤:2.数据挖掘流程3.数据预处理4.信息熵5.K-Means 聚类算法基本思想:工作步骤:计算题1.朴素贝叶斯2.BP神经网络3.Apriori算法4.代码分析复习要点:回归课本 简答题:1. Apriori算法主要步骤:(



