
复习要点: 回归课本
个人总结仅供参考
复习要点:回归课本
简答题:
1. Apriori算法主要步骤:
(1) 扫描全部数据,产生候选1-项集的集合C1.
(2) 根据最小支持度,由候选1-项集的集合C1产生频繁1-项集的集合L1
(3) 对k>1重复执行步骤4,5,6.
(4) 由LK执行连接和剪枝操作,产生候选(k+1)-项集的集合Ck+1
(5) 根据最小支持度,由候选(k+1)-项集的集合Ck+1 ,产生频繁(k+1)-项集的集合Lk+1
(6) 若L≠Ø,则k=k+1,跳往步骤,否则,跳往步骤7
(7) 根据最小置信度,由频繁项集产生强关联规则,结束。
2.数据挖掘流程
数据采集:爬虫
数据预处理:数据清洗
数据建模:算法
数据可视化:以图形方式显出
模型评估:准确率,RMSE等
3.数据预处理
数据清洗:填充缺失值,光滑噪声数据
数据集成:多个数据源中的数据存放到一个一致的数据存储中
数据转换:数据转换成适合于挖掘的形式
数据规约:数据立方体聚集,堆规约,数据压缩,数值规约,数据离散化与概念分层
4.信息熵
0稳定1最混乱
信息熵越大样本的混杂程序越大。
公式:
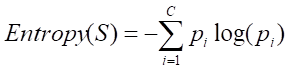
5.K-Means 聚类算法
基本思想:
1.指定需要划分的簇的个数K值
2.随机选择K个初始数据对象点作为初始的聚类中心
3.计算其余的各个数据对象到这K个初始聚类中心的距离,把对象划归为距离它最近的那个中心所处的簇类中。
4.调整新类并重新计算出新类的中心
5.如果两次计算出的聚类中心未曾发生任何变化,结束。否则重复步骤3,4
工作步骤:
输入:初始数据集DATA和簇的数目K
输出:K个簇,满足平方误差准测的函数收敛
(1) 任意选择K个数据对象作为初始聚类中心。
(2) Repeat
(3) 根据簇中的对象的平均值,将每个对象赋给最类似的簇
(4) 更新簇的平均值,即计算每个对象簇中的对象的平均值。
(5) 计算聚类准则函数E。
(6) Until准则函数E值不在变化。
计算题
1.朴素贝叶斯
记住公式,简简单单计算一下就好了。
2.BP神经网络
优慕课第八周第7个视频
3.Apriori算法
课本P38例题看懂即可
4.代码分析
代码分析题
复习要点:回归课本
个人总结如有错误记得评论区补充奥~
版权归原作者 天天向前张同学 所有, 如有侵权,请联系我们删除。