
数据挖掘 —— 无监督学习(聚类)
1. K-means
K-Means为基于切割的聚类算法
1.1 生成指定形状的随机数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
# *************** 生成指定形状的随机数据 *****************
from sklearn.datasets import make_circles,make_moons,make_blobs
n_samples =1000
# 生成环装数据
circles =make_circles(n_samples = n_samples,factor =0.5,noise =0.05)"""
n_samples: 为样本点个数
factor:为大圆与小圆的间距
"""
# 生成月牙形数据
moons =make_moons(n_samples = n_samples,noise =0.05)
# 生成簇状数据
blobs =make_blobs(n_samples = n_samples,random_state =100,center_box =(-10,10),cluster_std =1,centers =3)"""
random_state: 随机数种子,多少代保持随机数不变
center_box: 中心确定后的数据边界 默认(-10,10)
cluster_std:数据分布的标准差,决定各类数据的紧凑程度,默认为1.0
centers:产生数据点中心的个数 默认为3"""
# 产生随机数
random_data = np.random.rand(n_samples,2),np.array([0for i inrange(n_samples)])
datasets =[circles,moons,blobs,random_data]
fig = plt.figure(figsize=(20,8))
1.2 进行聚类
colors ="rgbykcm"for index,data inenumerate(datasets):X= data[0]
Y_old = data[1]
km_cluster =KMeans(n_clusters =2)
km_cluster.fit(X)
Y_new = km_cluster.labels_
fig.add_subplot(2,len(datasets),index+1)[plt.scatter(X[i,0],X[i,1],color = colors[Y_old[i]])for i inrange(len(X[:,0]))]
fig.add_subplot(2,len(datasets),index+5)[plt.scatter(X[i,0],X[i,1],color = colors[Y_new[i]])for i inrange(len(X[:,0]))]
1.3 结果
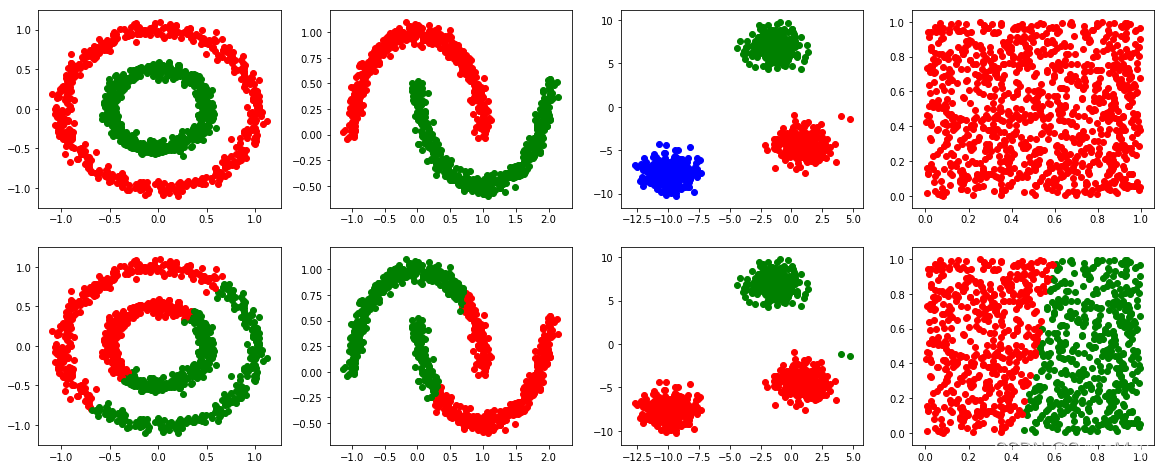
2. 系统聚类
2.1 代码
AgglomerativeClustering(n_clusters,affinity,linkage)
- affinity:
- “euclidean”,欧几里得距离
- “l1”, “l2”,
- “manhattan”, 曼哈顿距离
- “cosine”, 余弦距离
- “precomputed”预输入 需要输出距离矩阵
- linkage:{“ward”, “complete”, “average”, “single”}, default=”ward”
from sklearn.datasets import make_circles,make_blobs,make_moons
from sklearn.cluster import AgglomerativeClustering
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# 准备数据
n_samples =int(1e3)
circles =make_circles(n_samples = n_samples,noise =0.05,factor =0.5,random_state =10)
moons =make_moons(n_samples = n_samples,noise =0.05,random_state =10)
blobs =make_blobs(n_samples=n_samples,centers =4,cluster_std =0.1,center_box =(-1,1),random_state =10)
np.random.seed(10)
random_data =(np.random.rand(n_samples,2),np.zeros((n_samples)).astype(np.int))
datasets =[circles,moons,blobs,random_data]
fig = plt.figure(figsize =(20,8),dpi =72)
colors ="rgbk"for index,data inenumerate(datasets):X= data[0]Y= data[1]
agg_cluster =AgglomerativeClustering(n_clusters =2,affinity ="euclidean",linkage ="average")
Y_predict = agg_cluster.fit(X).labels_
fig.add_subplot(2,len(datasets),index +1)[plt.scatter(X[i,0],X[i,1],color = colors[Y[i]])for i inrange(len(X[:,0]))]
fig.add_subplot(2,len(datasets),index +5)[plt.scatter(X[i,0],X[i,1],color = colors[Y_predict[i]])for i inrange(len(X[:,0]))]
2.2 结果
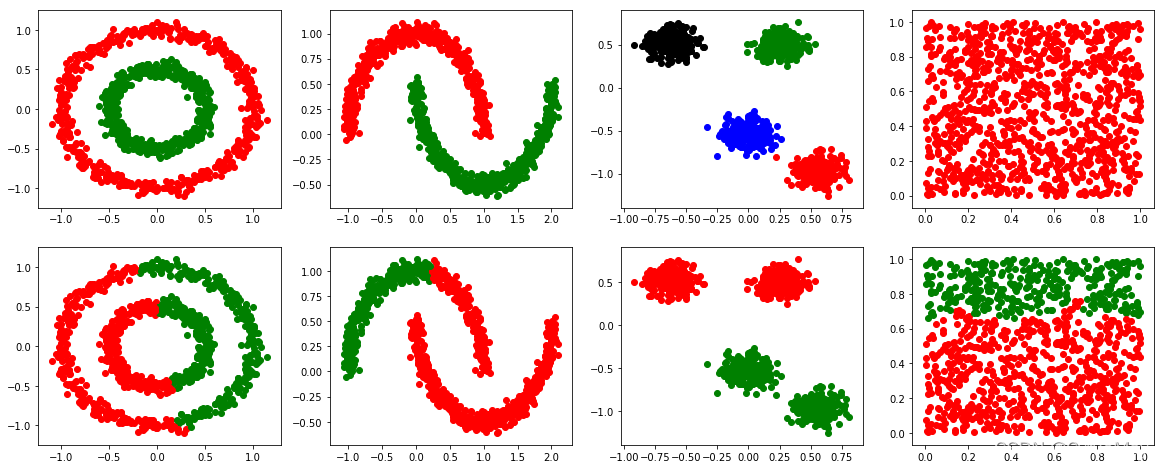
3 DBSCAN
3.1 参数选择
- 半径:k距离帮助设置半径,也就是要找到突变点, 即选中一个点,计算它和所有其他点的距离, 从小到大排序,发现距离突变点。 需要做大量实验观察。
- MinPts:先设置偏小一些,然后进行多次尝试
3.2 代码
# 导入聚类数据
n_samples =1000
from sklearn.datasets import make_circles,make_moons,make_blobs
from sklearn.cluster importDBSCANimport pandas as pd
import numpy as np
import matplotlib.pyplot as plt
circles =make_circles(n_samples = n_samples,noise =0.05,factor =0.5,random_state =10)
moons =make_moons(n_samples = n_samples,noise =0.05,random_state =10)
blobs =make_blobs(n_samples = n_samples,centers =3,cluster_std =0.1,center_box =(-1,1),random_state =10)
np.random.seed(10)
random_data =(np.random.rand(n_samples,2),np.zeros((n_samples)).astype(np.int))
datasets =[circles,moons,blobs,random_data]
fig = plt.figure(figsize =(20,8),dpi =72)
colors ="rgbky"for index,data inenumerate(datasets):X= data[0]
Y_old = data[1]
dbscan_model =DBSCAN(eps =0.1,min_samples =20)
dbscan_model.fit(X)
Y_new = dbscan_model.labels_
fig.add_subplot(2,len(datasets),index+1)[plt.scatter(X[i,0],X[i,1],color = colors[Y_old[i]])for i inrange(len(X[:,0]))]
plt.title("original algorithm")
fig.add_subplot(2,len(datasets),index +5)[plt.scatter(X[i,0],X[i,1],color = colors[Y_new[i]])for i inrange(len(X[:,0]))]
plt.title("DBSCA algorithm")
3.3 结果
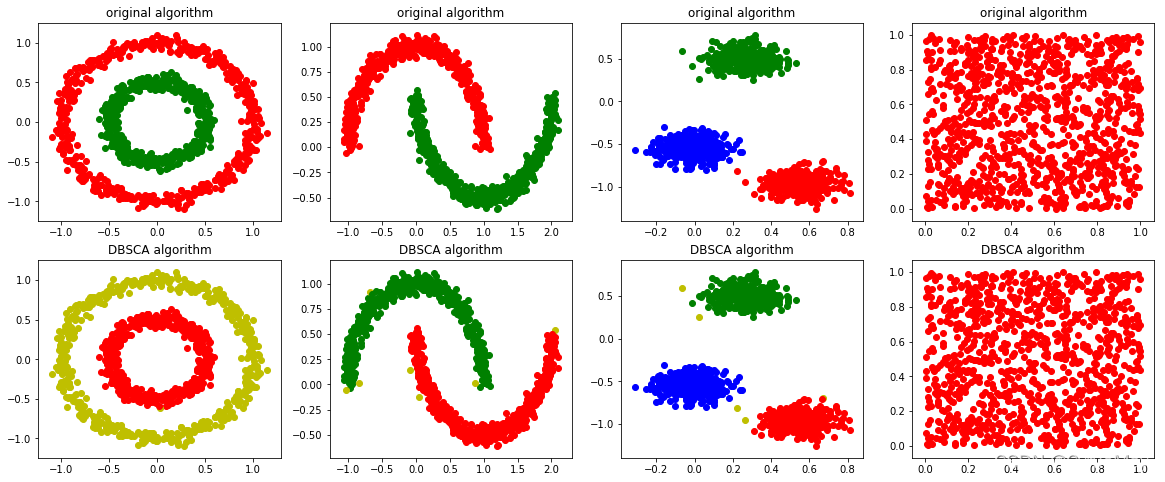
by CyrusMay 2022 04 05
本文转载自: https://blog.csdn.net/Cyrus_May/article/details/123971463
版权归原作者 CyrusMay 所有, 如有侵权,请联系我们删除。
版权归原作者 CyrusMay 所有, 如有侵权,请联系我们删除。