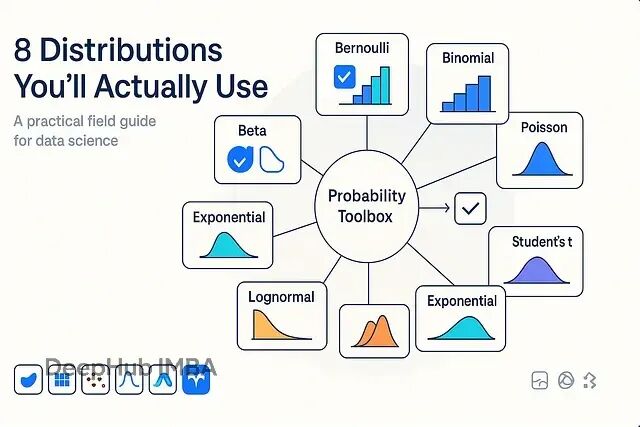
为你的数据选择合适的分布:8个实用的概率分布应用场景和选择指南
本文包含了实际会用到的概率分布速查手册,包含使用场景、代码实现和常见陷阱
【AI知识点】置信区间(Confidence Interval)
置信区间(Confidence Interval, CI) 是统计学中用于估计总体参数的范围。它给出了一个区间,并且这个区间包含总体参数的概率等于某个指定的置信水平(通常是 90%、95% 或 99%)。与点估计不同,置信区间通过区间估计给出了参数的可能范围,从而提供了更可靠的信息。
【AI知识点】二项分布(Binomial Distribution)
二项分布(Binomial Distribution) 是概率论和统计学中描述独立重复的伯努利试验中成功次数的离散概率分布。它是基于多次独立的伯努利试验的扩展,用于描述在 n 次试验中发生成功的次数。

随机性、熵与随机数生成器:解析伪随机数生成器(PRNG)和真随机数生成器(TRNG)
本文将探讨随机性、熵的概念以及不同类型随机数生成器(random number generator, RNG)的原理,重点介绍伪随机数生成器(PRNG)和真随机数生成器(TRNG)。

信息论、机器学习的核心概念:熵、KL散度、JS散度和Renyi散度的深度解析及应用
本文深入探讨了信息论、机器学习和统计学中的几个核心概念:熵、KL散度、Jensen-Shannon散度和Renyi散度。这些概念不仅是理论研究的基石,也是现代数据分析和机器学习应用的重要工具。
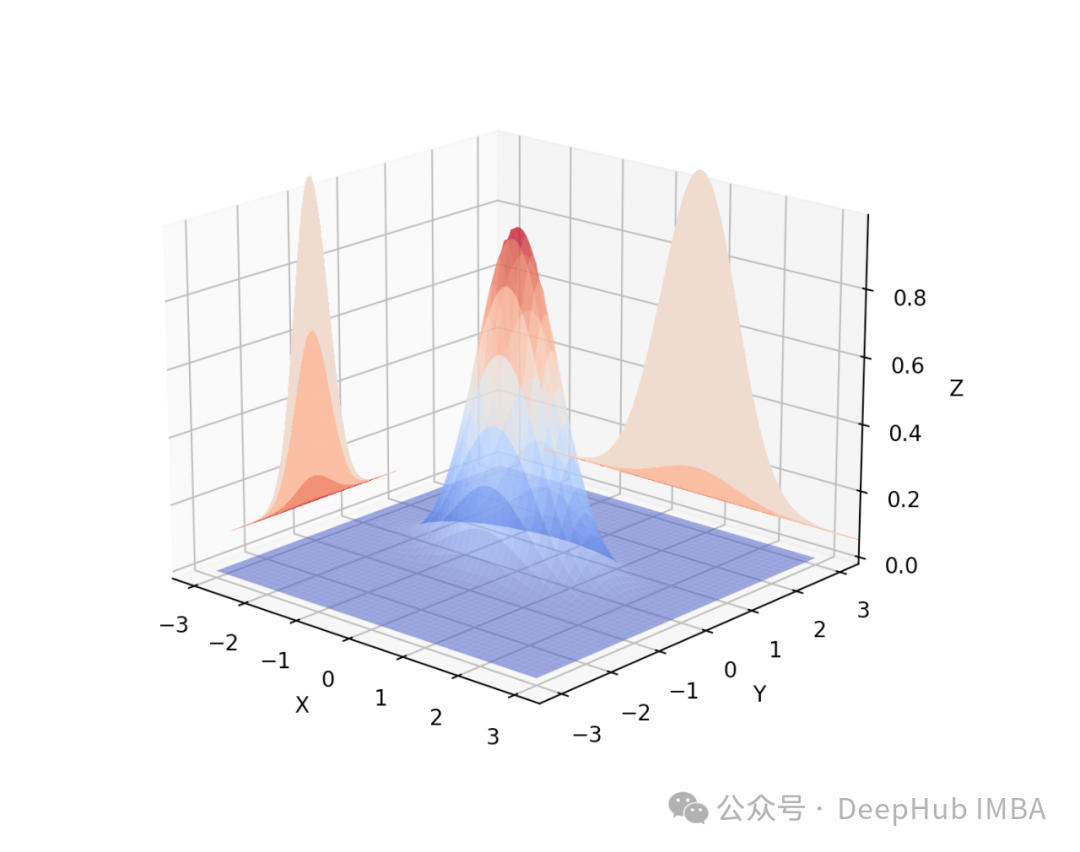
深入理解双变量(二元)正态投影:理论基础、直观解释与应用实例
二元投影有助于确定在给定另一个变量的特定值时的一个随机变量的期望值。例如,在线性回归中,投影有助于估计因变量如何随自变量变化而变化。
数据并非都是正态分布:三种常见的统计分布及其应用
本文我们研究三种常见分布以及我们如何使用它们:正态分布、泊松分布和卡方分布。
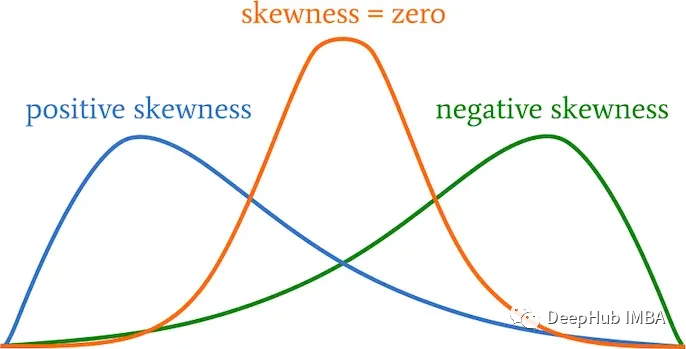
数据偏度介绍和处理方法
偏度(skewness)是用来衡量概率分布或数据集中不对称程度的统计量。
STATA cox生存模型C-index的比较
// STATA的STATA的STATA的//C指数间差异的假设检验//我自己看的文章,常见的就是一个指标和TNM分期的性能作比较//安装ssc instal somersd//定义模型结果和时间变量stset time, failure(dead==1)//进行cox回归 调整其他变量stcox
环境混合物总体效应:加权分位数和回归(WQS)
加权分位数和(Weighted Quantile Sum, WQS)回归是一种在环境暴露中常见的高维数据集的多元回归的统计模型。该模型允许通过有监督的方式构建一个加权指数,以评估环境暴露的总体效应以及混合物中每一个成分对总体效应的贡献。首先若某一类环境混合物中共有i个component,将每个com
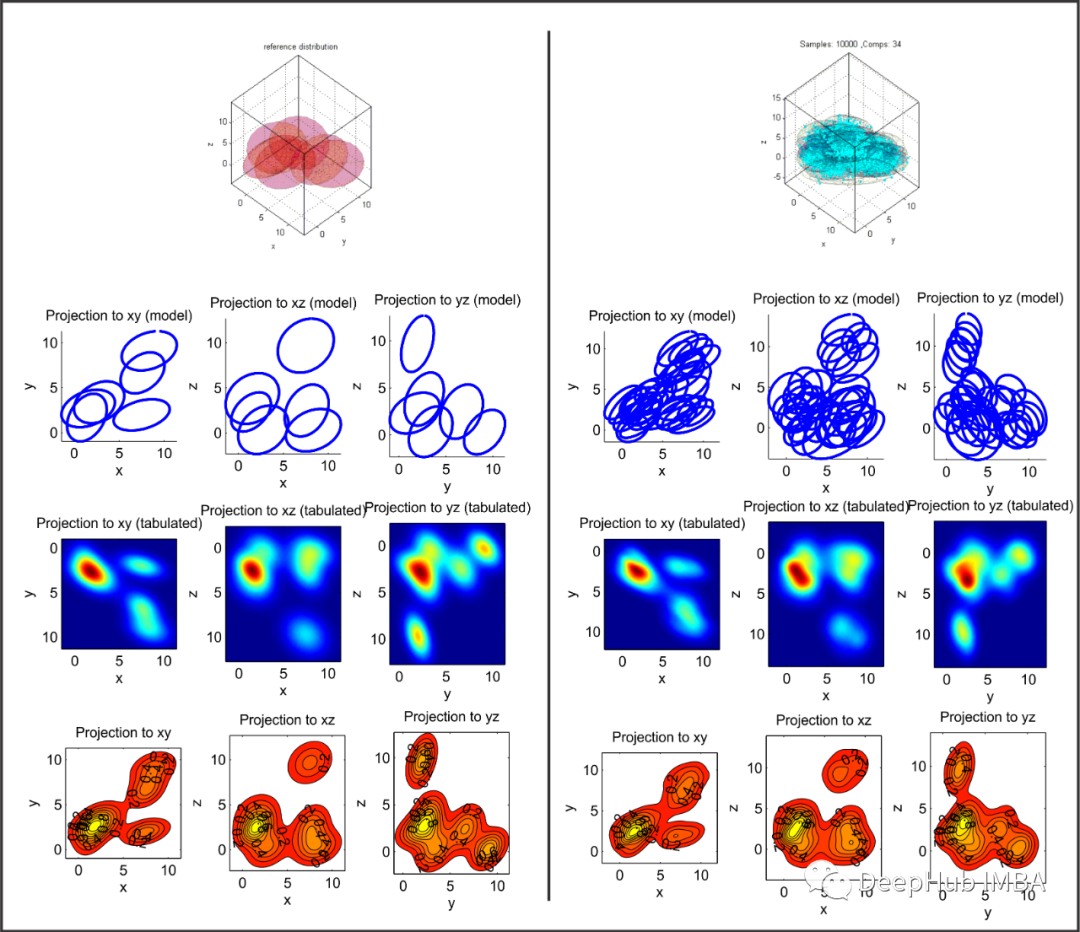
非参数检验方法,核密度估计简介
核密度估计(Kernel Density Estimation,简称KDE)是一种非参数统计方法,用于估计数据样本背后的概率密度函数
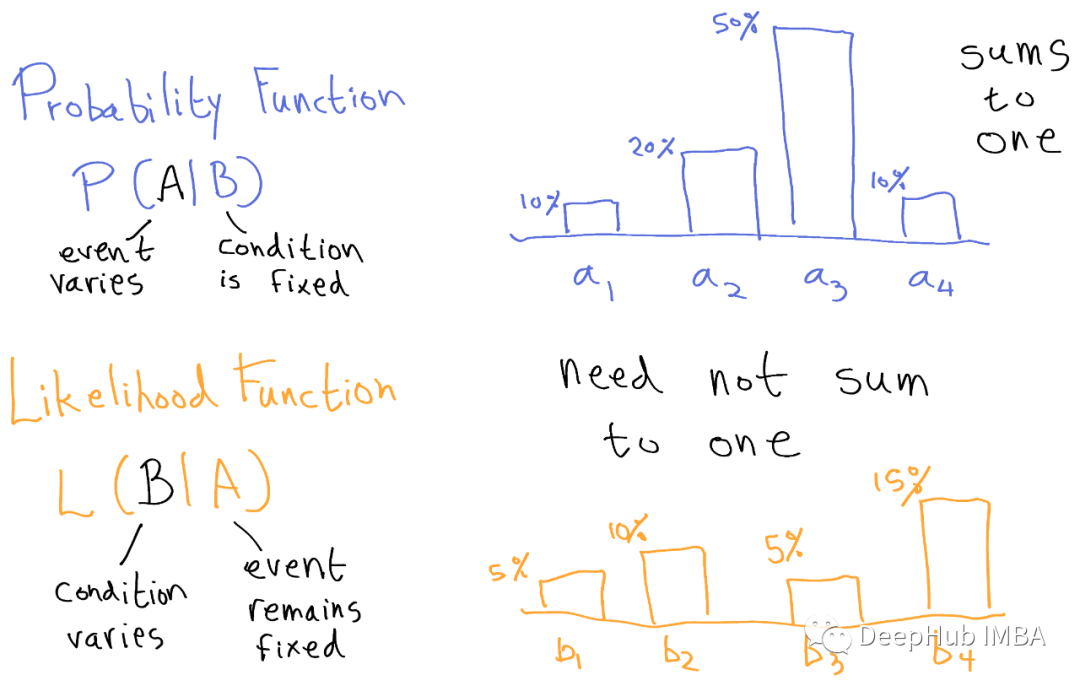
概率和似然
在日常生活中,我们经常使用这些术语。但是在统计学和机器学习上下文中使用时,有一个本质的区别。本文将用理论和例子来解释概率和似然之间的关键区别。

MSE = Bias² + Variance?什么是“好的”统计估计器
本文的目的并不是要证明这个公式,而是将他作为一个入口,让你了解统计学家如何以及为什么这样构建公式,以及我们如何判断是什么使某些估算器比其他估算器更好。
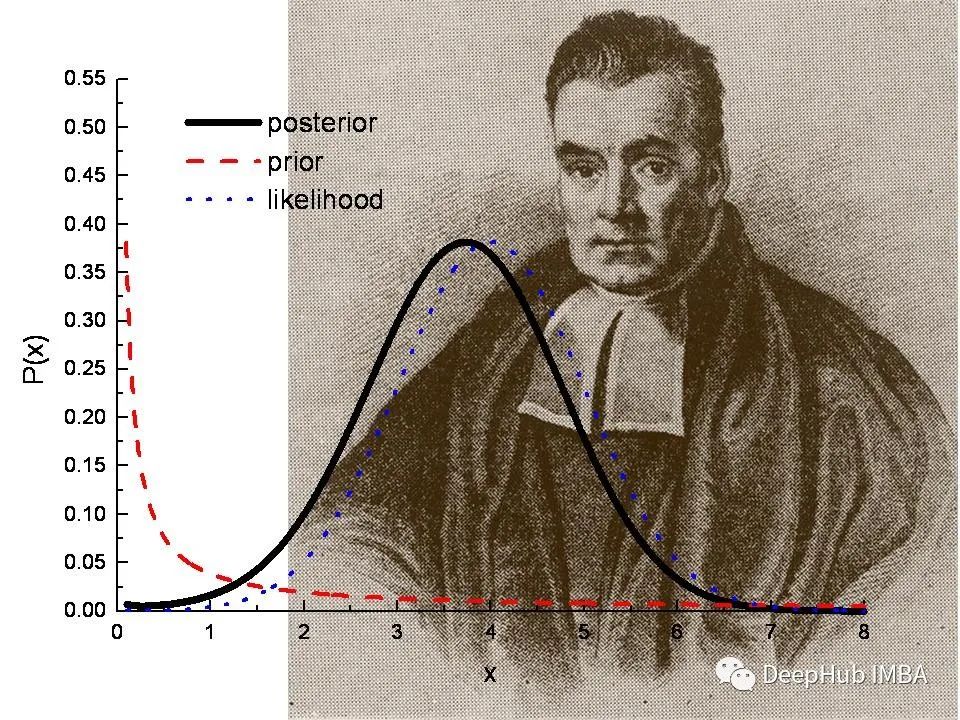
我们能从后验分布中学到什么?贝叶斯后验的频率解释
假设我们从未知分布 q 中观察到 N 个独立且同分布的 (iid) 样本 X = (x1, ... , xN)。统计学中的一个典型问题是“样本集 X 能告诉我们关于分布 q 的什么信息?”。

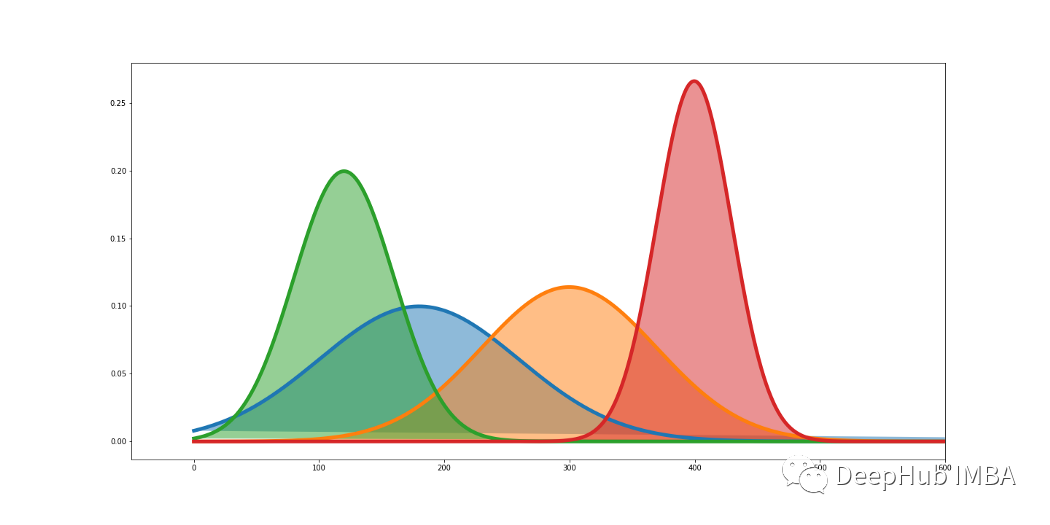
最大似然估计(MLE)入门教程
最大似然估计(Maximum Likelihood Estimation)是一种可以生成拟合数据的任何分布的参数的最可能估计的技术。它是一种解决建模和统计中常见问题的方法——将概率分布拟合到数据集。
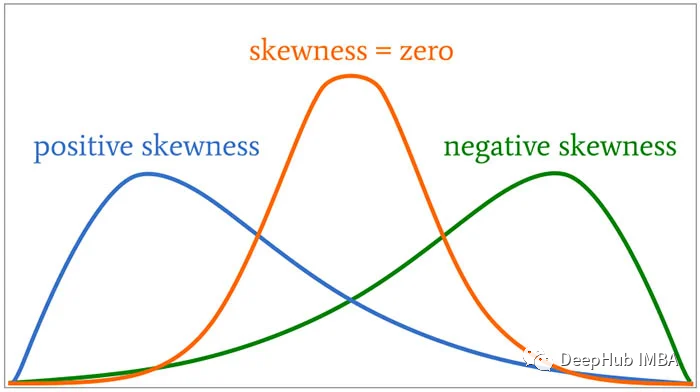
学习偏态分布的相关知识和原理的4篇论文推荐
偏态分布(skewness distribution)指频数分布的高峰位于一侧,尾部向另一侧延伸的分布。
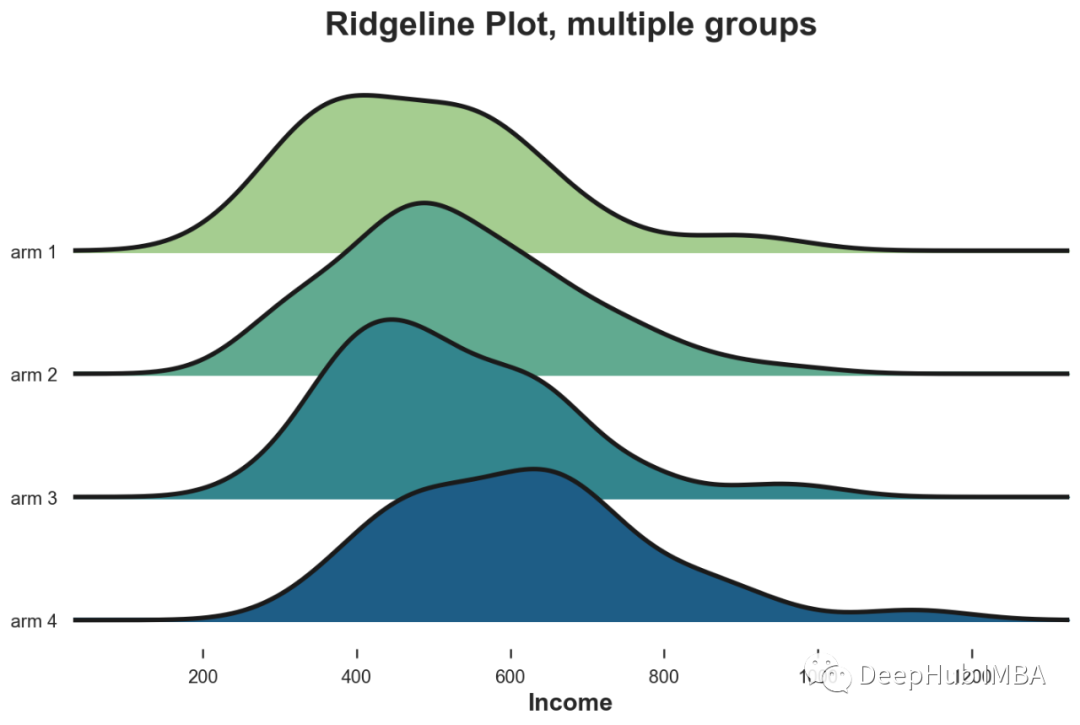
如何比较两个或多个分布:从可视化到统计检验的方法总结
比较一个变量在不同组中的分布是数据科学中的一个常见问题,在这篇文章中,我们将看到比较两个(或更多)分布的不同方法,并评估它们差异的量级和重要性。

统计学小抄:常用术语和基本概念小结
统计学是涉及数据的收集,组织,分析,解释和呈现的学科。
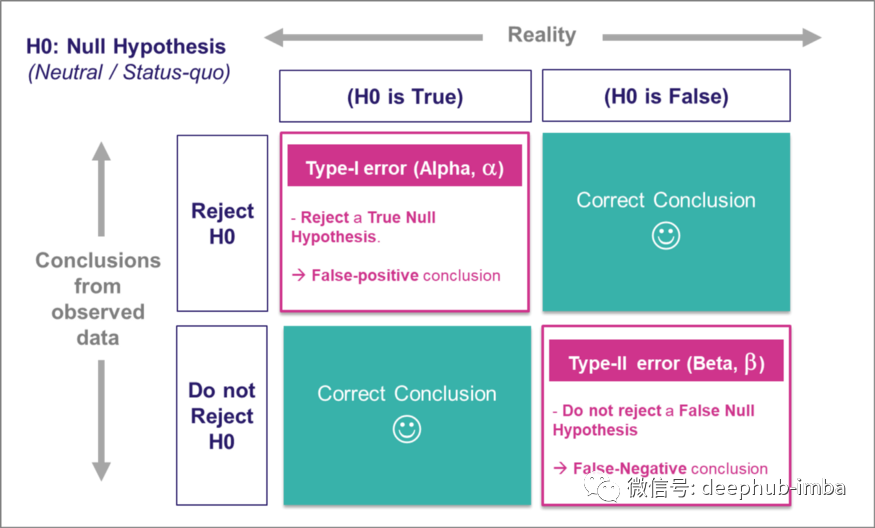
假设检验中的第一类错误和第二类错误
这是支撑统计学中假设检验的最重要概念
- 1
- 2



