
一、Confusion matrix 混淆矩阵
是一种可视化工具,特别用于监督学习。通过这个矩阵,可以很清晰地看出机器是否将两个不同的类混淆了。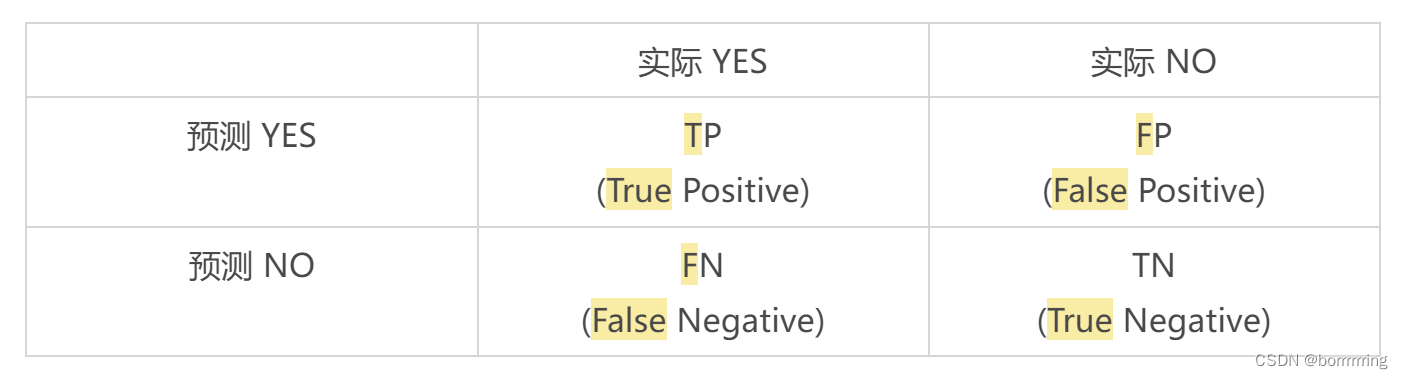
上图的表格其实就是
confusion matrix
- True/False: 预测结果是否正确
- Positive/Negative:预测的方向是正方向还是负方向
- 真阳性(True Positive, TP): 预测为正样本,实际为正样本,预测正确
- 真阴性(True Negative, TN):预测为负样本,实际为负样本,预测正确
- 假阳性(False Positive, FP):预测为正样本,实际为负样本,预测错误(预测为正样本是错的)
- 假阴性(False Negative, FN):预测为负样本,实际为正样本,预测错误(预测为负样本是错的)
**
举例说明:
**
假设识别
猫
类别,其中加了狗的图片,即认为狗图片为负样本,猫图片为正样本。
- 猫的图片被预测为猫,为TP;
- 狗的图片被预测为狗,为TN;
- 狗的图片被预测为猫,为FP;
- 猫的图片被预测为狗,为FN;
二、由混淆矩阵衍生出的指标
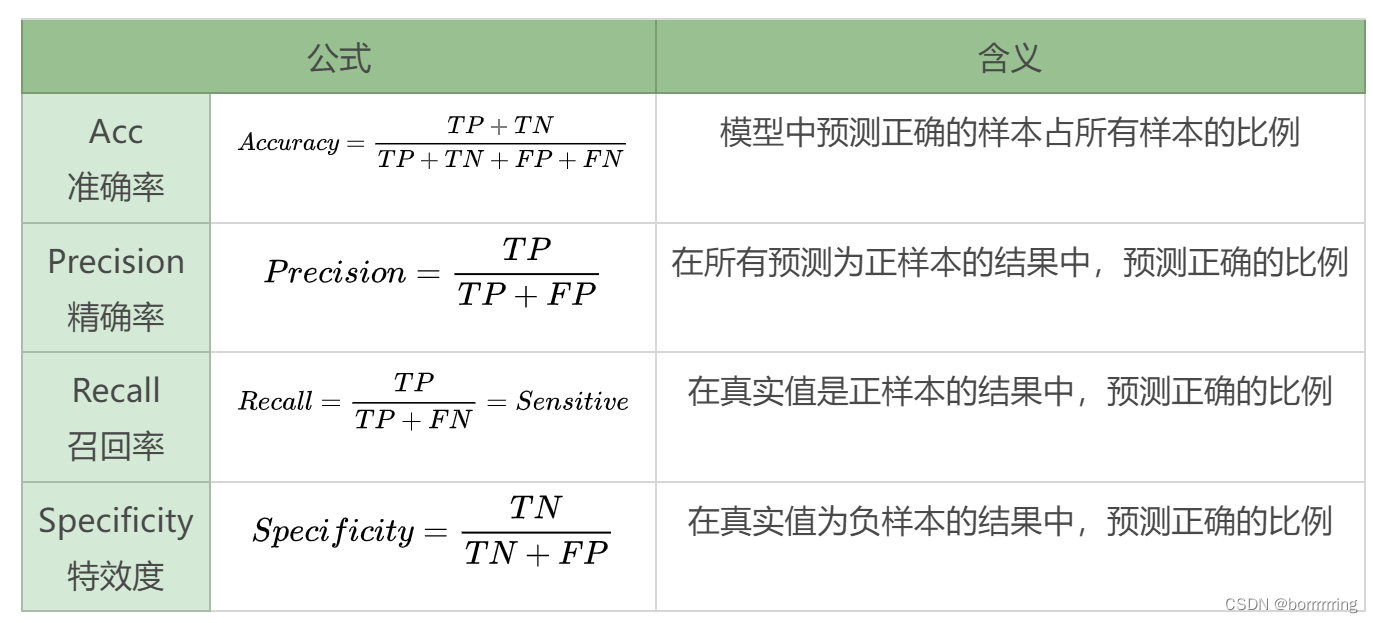
1、Accuracy 准确率
被分对的样本/总样本数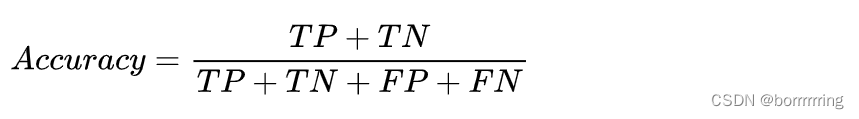
一般来说,正确率越高,分类器越好。
但只用这个指标不够全面,因为若
负样本的数量远>正样本数量
,虽然正确率仍可以很高,但完全错分类正样本仍能达到较高的Acc。
2、 Error rate 错误率
与accuray相对,描述被分类器错分的比例。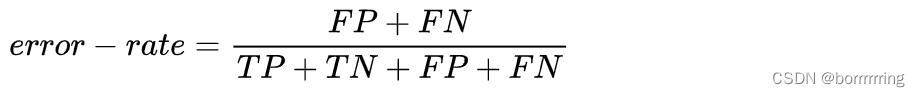
3、 Sensitive 灵敏度
表示所有正例中被分对的比例,和改良分类器对正例的识别能力。在所有真实值是positive的结果中,模型预测对的比重。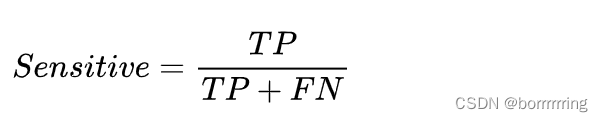
4、Specificity 特效度
所有负例中被分对的比例,衡量分类器对负例的识别能力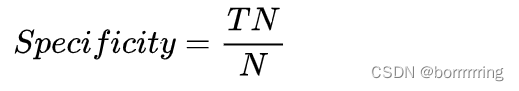
5、Precision 精度
度量精确性,表示被分为正例的示例中实际为正例的比例。
在模型预测为正样本的所有结果中,有多少真正为正样本的比例。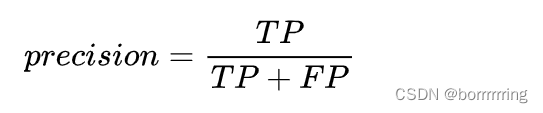
6、Recall 召回率
度量覆盖面,由多少个正例被分为正例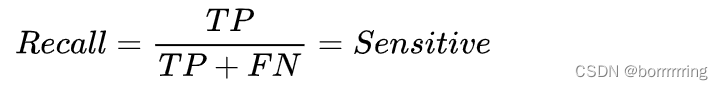
三、指标对比分析
1、precision 和 recall
上文提到,
Accuracy
并不能完全反映检测结果,所以需要
Precision
和
Recall
。
(下面的空格横线只是为了让等号对齐,没有任何意义)
- 提高
Precision= 提高二分类器预测正样本门槛 _____________= 使二分类预测的正样本尽可能是真实正样本 - 提高
Recall= 降低二分类器预测正样本门槛 _____________=使得二分类器尽可能将真实的正例挑选出来
(1)在意TP
由公式可以看到,
Precision
和
Recall
的分子都是
True Positive
:
Precision看的是,在预测正向的情况下,实际的【精准度】是多少;Recall看的是,在实际为正向的状况下,预测模型【能召回多少】实际正向的答案。
Precision
和
Recall
的结果看重哪一个,主要取决于具体的项目情况。例如:
- 指纹识别门锁,我们更在意预测正向(开门)的答对了多少,不是很在意实际正向(主人)的答对了多少。也就是说,在意
Precision,不在意Recall。 - 广告投放中,我们在意实际正向(潜在客户)的答对了多少,而不是很在意预测正向(广告投放)的答对了多少。
(2)不在意TF
这个结果没有什么意思,在指纹识别门锁中,是陌生人按指纹不开门。通常情况下,实际上为正样本的结果比负样本要少,预测为正样本的一定会比预测为负样本少,所以
True Negative
的数量最多,也没有什么讨论意义。
2、F1 Score 综合评价指标
若一个任务中,
Precision
和
Recall
同等重要,想要用一个指标统一,则有了
F1 Score
,也称为
F1 Measure
。它是精确率和召回率的调和平均数,最大为1(最好),最小为0(最差)。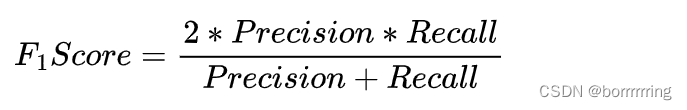
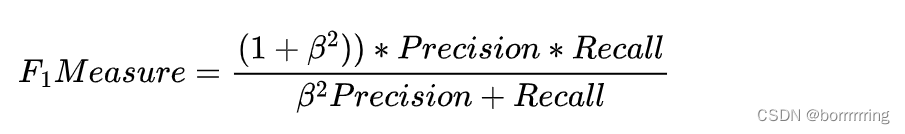
当beta=1时,F1-Measure = F1 Score
把两个值综合变为一个值,就方便做模型对比了。
(1)为什么采用调和平均的方法?
调和平均常用于计算平均速率,在固定距离下,所花时间就是平均速率,这和数据成倒数关系,而
F1 Measure
也同样是这样的数据特性,在固定
TP
的情况下,有不同的分母,所以这里使用调和平均较为适当。
四、检测结果出来的图怎么看?
1、P曲线
P_curve.png:准确率
precision
与置信度
confidence
的关系图。
【置信度
confidence
:用来判断边界框内的物体是正样本还是负样本,大于置信度阈值的判定为正样本,小于置信度阈值的判定为负样本即背景。】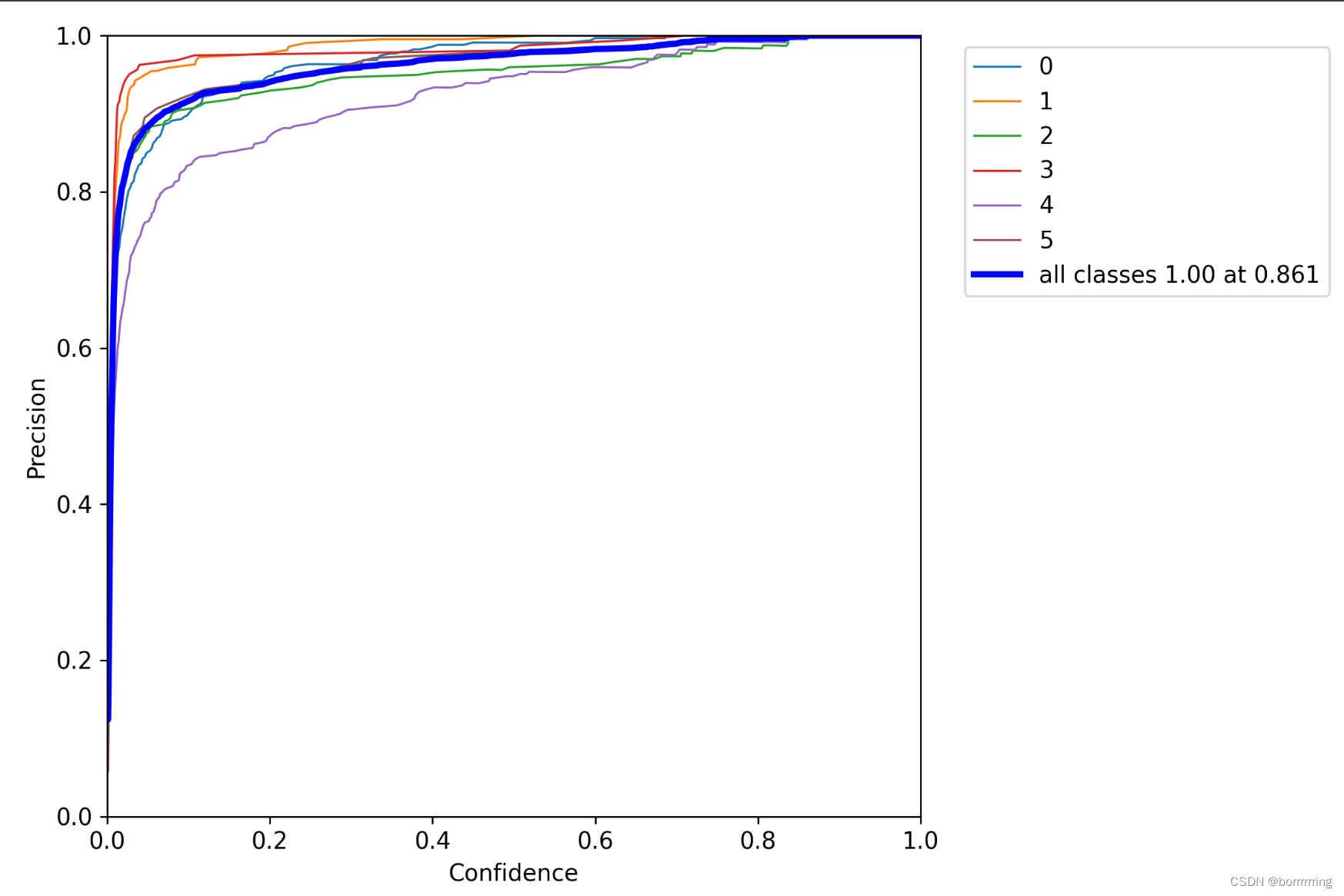
画图的代码在yolov5代码的
utils
文件夹下的
metrics.py
文件中,代码如下:
def plot_mc_curve(px, py, save_dir='mc_curve.png', names=(), xlabel='Confidence', ylabel='Metric'):
# Metric-confidence curve
fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)if0< len(names)<21: # display per-class legend if < 21 classesfor i, y in enumerate(py):
ax.plot(px, y, linewidth=1, label=f'{names[i]}')# plot(confidence, metric)
else:
ax.plot(px, py.T, linewidth=1, color='grey')# plot(confidence, metric)
y = py.mean(0)
ax.plot(px, y, linewidth=3, color='blue', label=f'all classes {y.max():.2f} at {px[y.argmax()]:.3f}')
ax.set_xlabel(xlabel)
ax.set_ylabel(ylabel)
ax.set_xlim(0, 1)
ax.set_ylim(0, 1)
plt.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
fig.savefig(Path(save_dir), dpi=250)
从代码中可以看到,下面这句话对应图例中最后一句。
ax.plot(px, y, linewidth=3, color='blue', label=f'all classes {y.max():.2f} at {px[y.argmax()]:.3f}')
y.max
是指图上所有类别的
precious
的最大值,这里是1。下面的PR曲线可以看到是0.991。
argmax
函数百度一下定义:
这个函数大约是为了体现这个模型的最终展示效果。因为可以看到,6个类别的曲线,有的精度比较好,有的不太好,通过整合成一条曲线来展示一个综合性能。(这点是猜测,如有其他见解欢迎讨论)
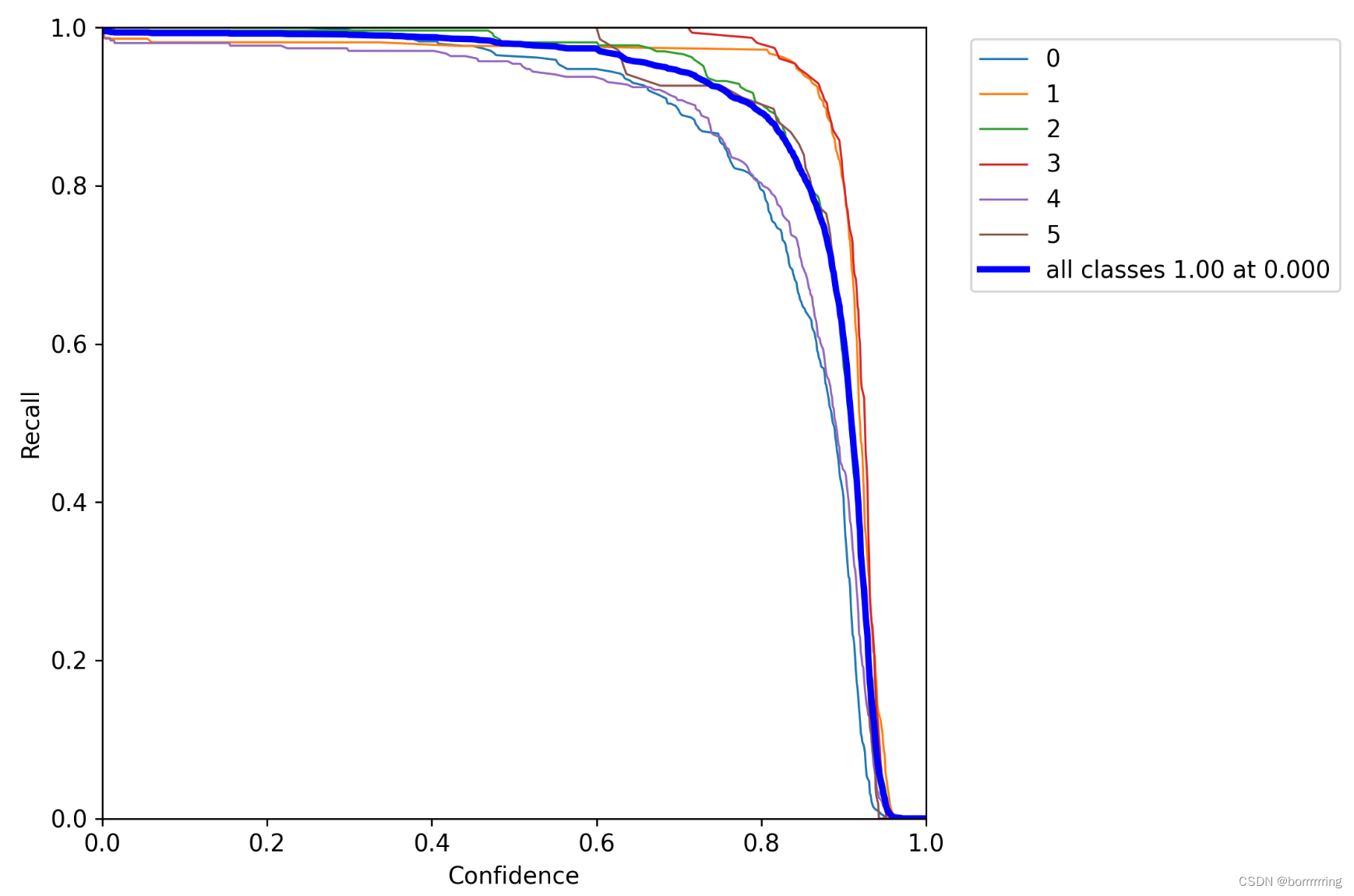
2、R曲线
3、P-R曲线
precious
与
recall
之间的关系,PR曲线下围城的面积称作AP,所有类别AP的平均值即为mAP。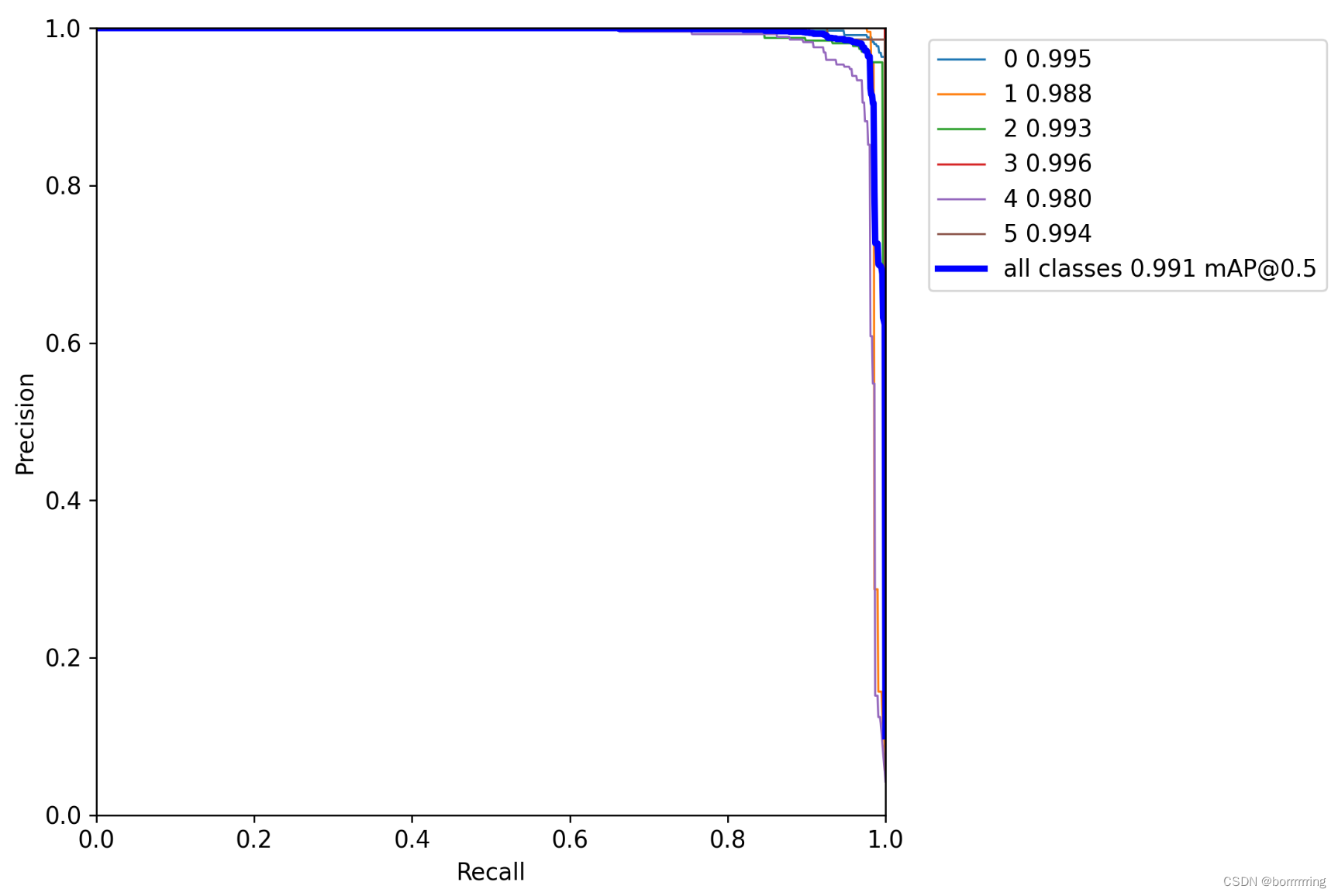
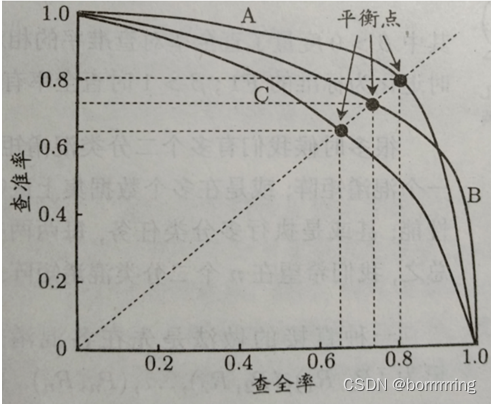
如果一个学习器的PR曲线A完全包住另一个学习器B的PR曲线,则可断言A的性能优于B。但是A和B发生交叉,那性能该如何判断呢?我们可以根据曲线下方的面积大小来进行比较,但更常用的是平衡点F1。平衡点(BEP)是
P=R
(准确率 = 召回率)时的取值,即斜率为1,F1值越大,我们可以认为该学习器的性能较好。
4、result.png
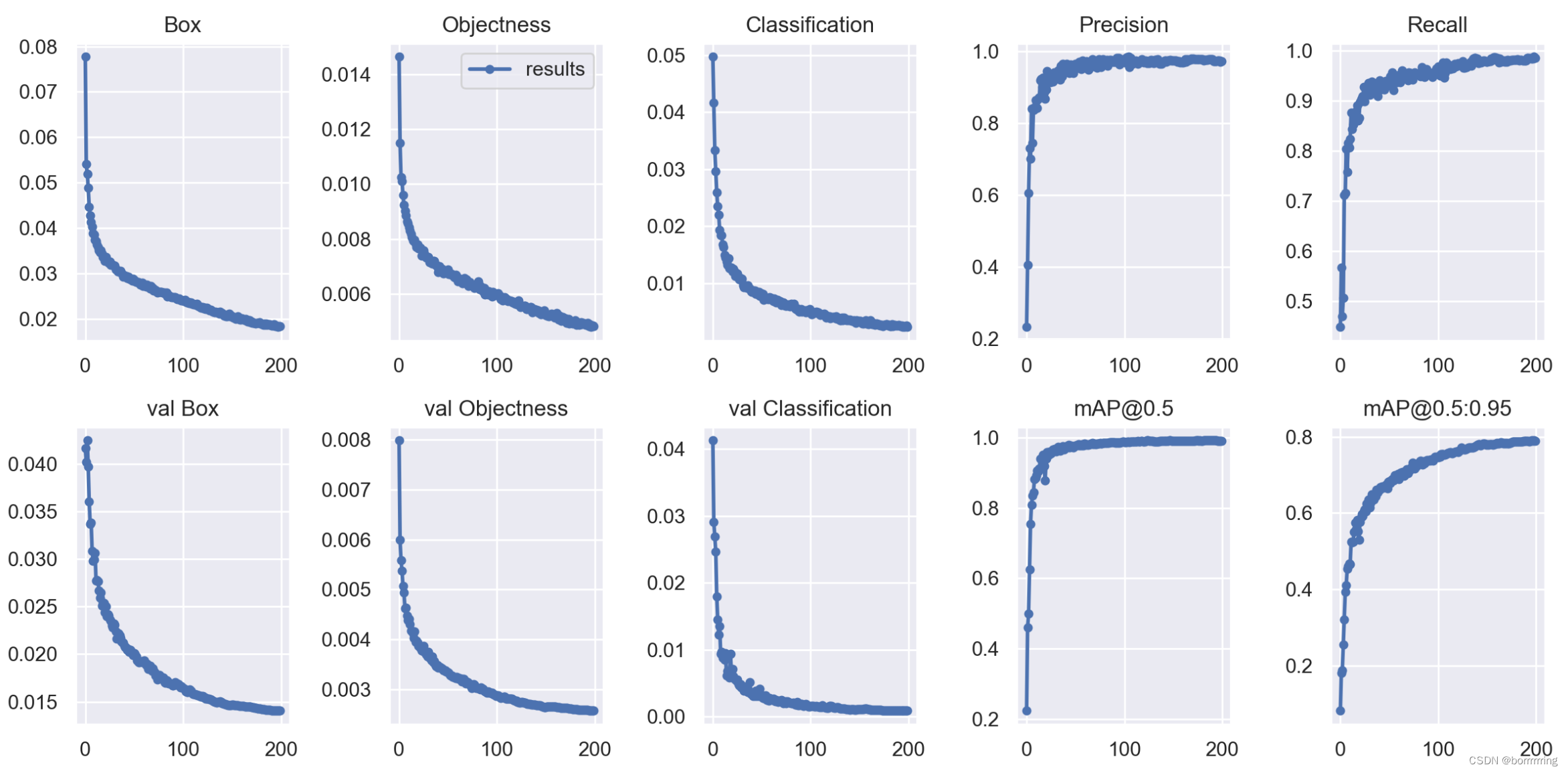 Box:YOLO V5使用
Box:YOLO V5使用
GIOU Loss
作为
bounding box
的损失,Box推测为GIoU损失函数均值,越小方框越准;
Objectness:推测为目标检测loss均值,越小目标检测越准;
Classification:推测为分类loss均值,越小分类越准;
Precision:精确率(所有分类正确中的正样本比例);
Recall:召回率(有多少正样本被找到)
val Box: 验证集
bounding box
损失
val Objectness:验证集目标检测
loss
均值
val classification:验证集分类
loss
均值
mAP@0.5:阈值大于0.5的平均
mAP
。【其中,mAP指PR曲线下的面积AP的平均值,@后面的数表示判定
IoU
为正负样本的阈值】
mAP@0.5:0.95:表示在不同
IoU
阈值(从0.5到0.95,步长0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均
mAP
。【@0.5:0.95表示阈值取0.5:0.05:0.95后取均值】
一般训练结果主要观察精确率和召回率波动情况(波动不是很大则训练效果较好),然后观察[email protected] & [email protected]:0.95 评价训练结果。
5、 F1_curve.png
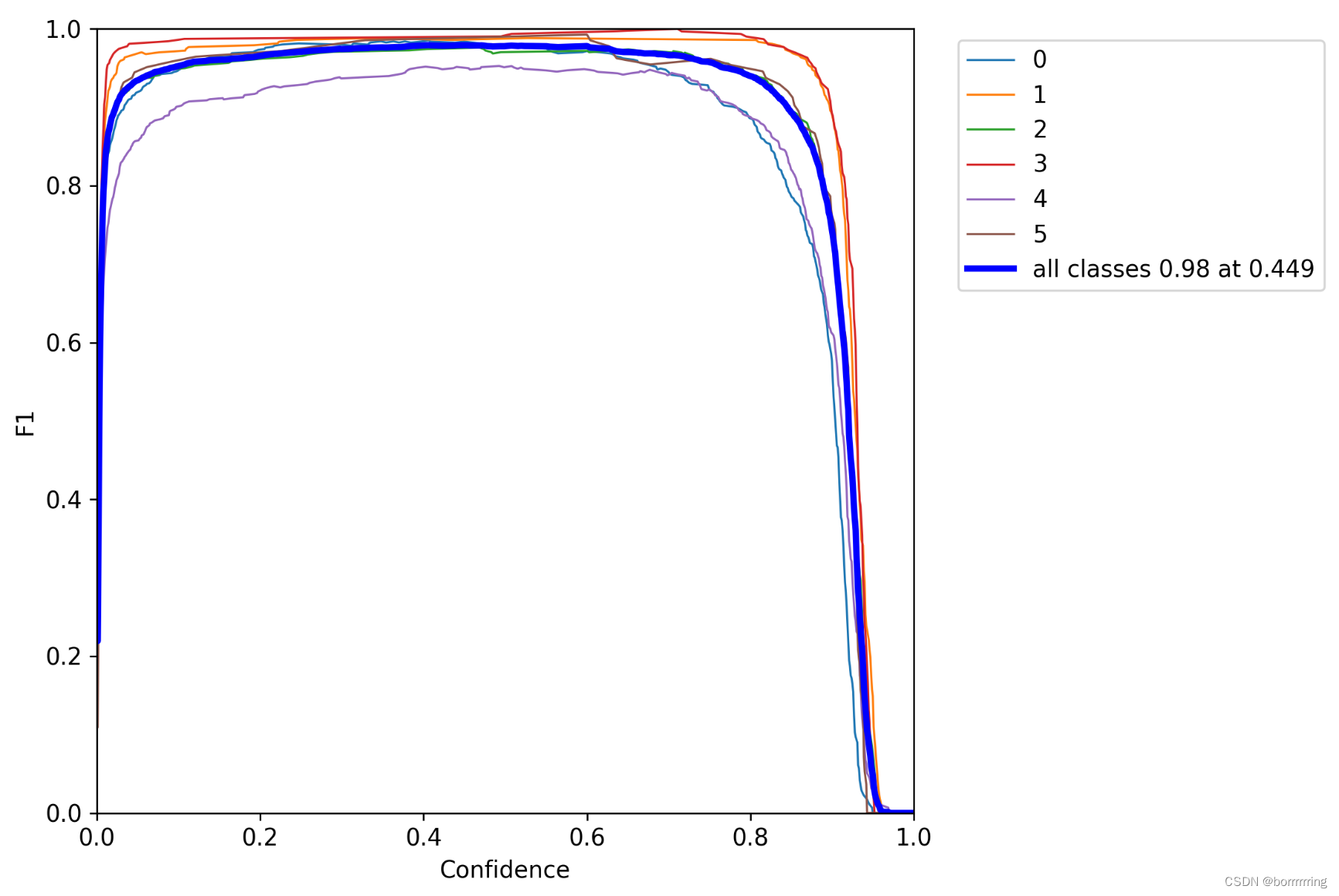
F1-score
与置信度间的关系。
F1-score
是分类问题的一个衡量指标,是精确率
precision
和召回率
recall
的调和平均数,最大为1,最小为0。【1是最好,0是最差】
6、Labels.jpg
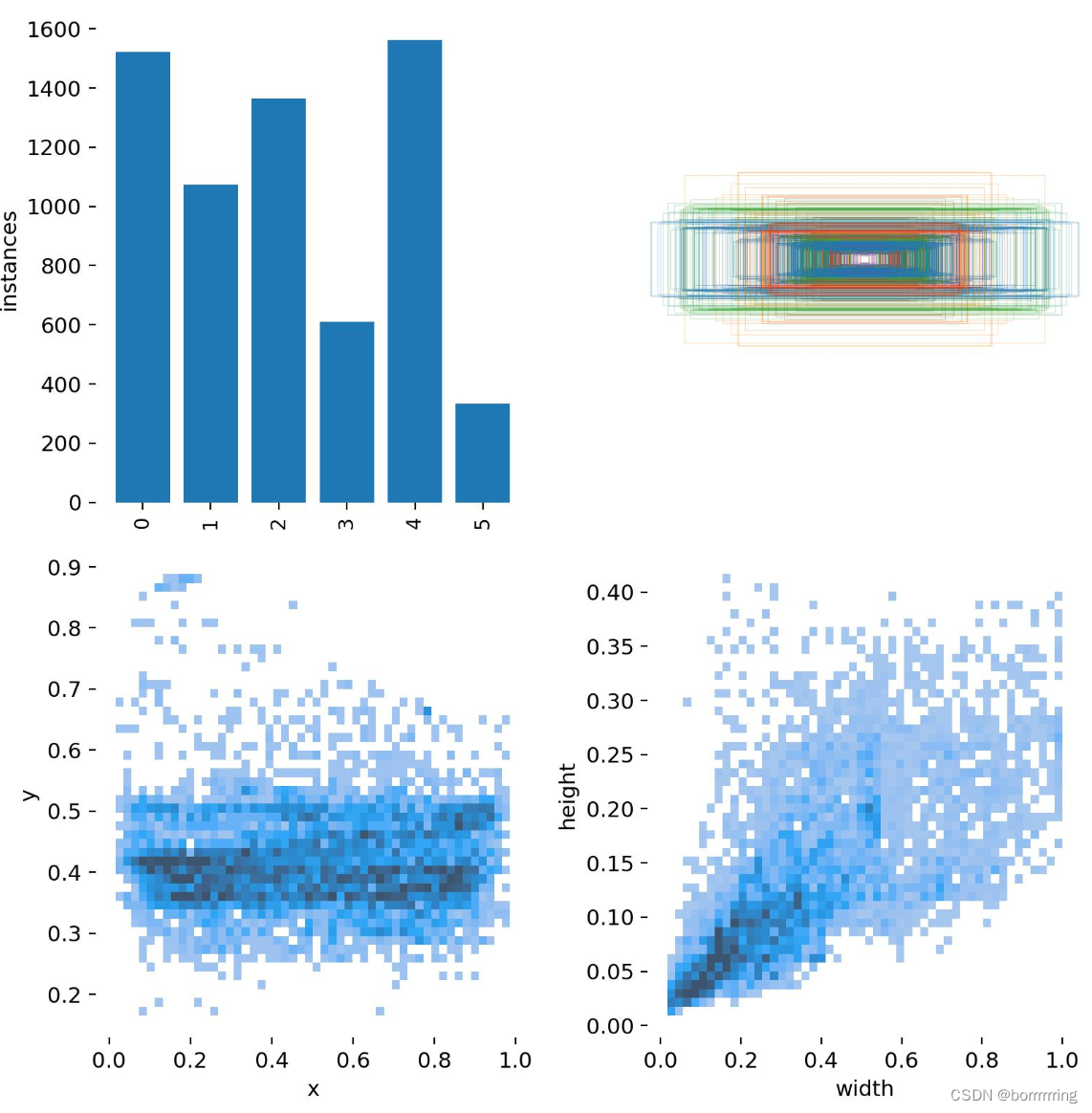
第一个图:
classes
每个类别的数据量
第二个图 :
labels
标签
第三个图 :center xy
第四个图 :
labels
的长和宽
参考博文
秒懂Confusion Matrix之混淆矩阵详解
yolov5 训练结果解析
关于yolov5的一些说明(txt文件、训练结果分析等)
版权归原作者 borrrrrring 所有, 如有侵权,请联系我们删除。