
文章目录
讲在前面
大概在今年10月初期,AI作画的热潮突然被掀起,这股潮流瞬间激起了人们对于AI的思考和恐惧,一方面来说,随着AI绘画的不断完善,似乎我们每个人都能创作出满足一定要求的画作;而从另一方面来说,虽然现在的AI绘画可能还没有那么成熟,但是已经足够让人类感受到足够大的挑战,究竟还有什么职业能够抵抗得了AI的冲击,让我们从应用到原理,具体来了解一下,AI绘画是如何掀起这波热浪的。
一、Novel AI
1. 网站介绍

- Novel AI:一个使用AI技术进行一系列人类所谓“想象力”创造的网站,从绘画到作文,从画出一幅满足要求的画,再到讲好一个引人入胜的故事,这里引用一句原网站的话
Driven by AI , painlessly construct unique stories , thrilling tales, seductive romances , or just fool around . Anything goes ! , 什么意思呢? 在人工智能的驱动下,不痛不痒地构建独特的故事,惊心动魄的故事,诱人的浪漫,或者只是胡闹。一切皆有可能!

其实人类对于AI恐惧的关键不在于AI能够进行绘画和写作,令人心惊的是, Tweak the AI’s output the way you like it,AI可以做到你想要的,无论how you like,当然,说了这么多,最重要的还是亲自上手,这里要感谢某站up主的呕心沥血,只需下载运行脚本,直接使用完整版AI绘画程序,原视频地址奉上,希望大家能够多多支持,秋枼akiiii。
2. AI作画
- 第一步:下载并安装,这里提供一个网盘地址:百度网盘,提取码tls5

- 第二步:解压zip文件
- 第三步:在文件中找到点击生成启动脚本的文件,打开即可自动安装对应依赖
- 第四步:在文件中找到启动脚本,打开即可自动运行

- 第五步:在脚本运行完成后,会出现对应的本地端口,复制在浏览器打开即可
到这里,就能在浏览器中看到一个拥有良好界面的网站,自行选择文本生成或图生图等方式即可,这里用文本生成做一个简单演示,在正面和负面标签输入一些自己想要的单词或短语即可:
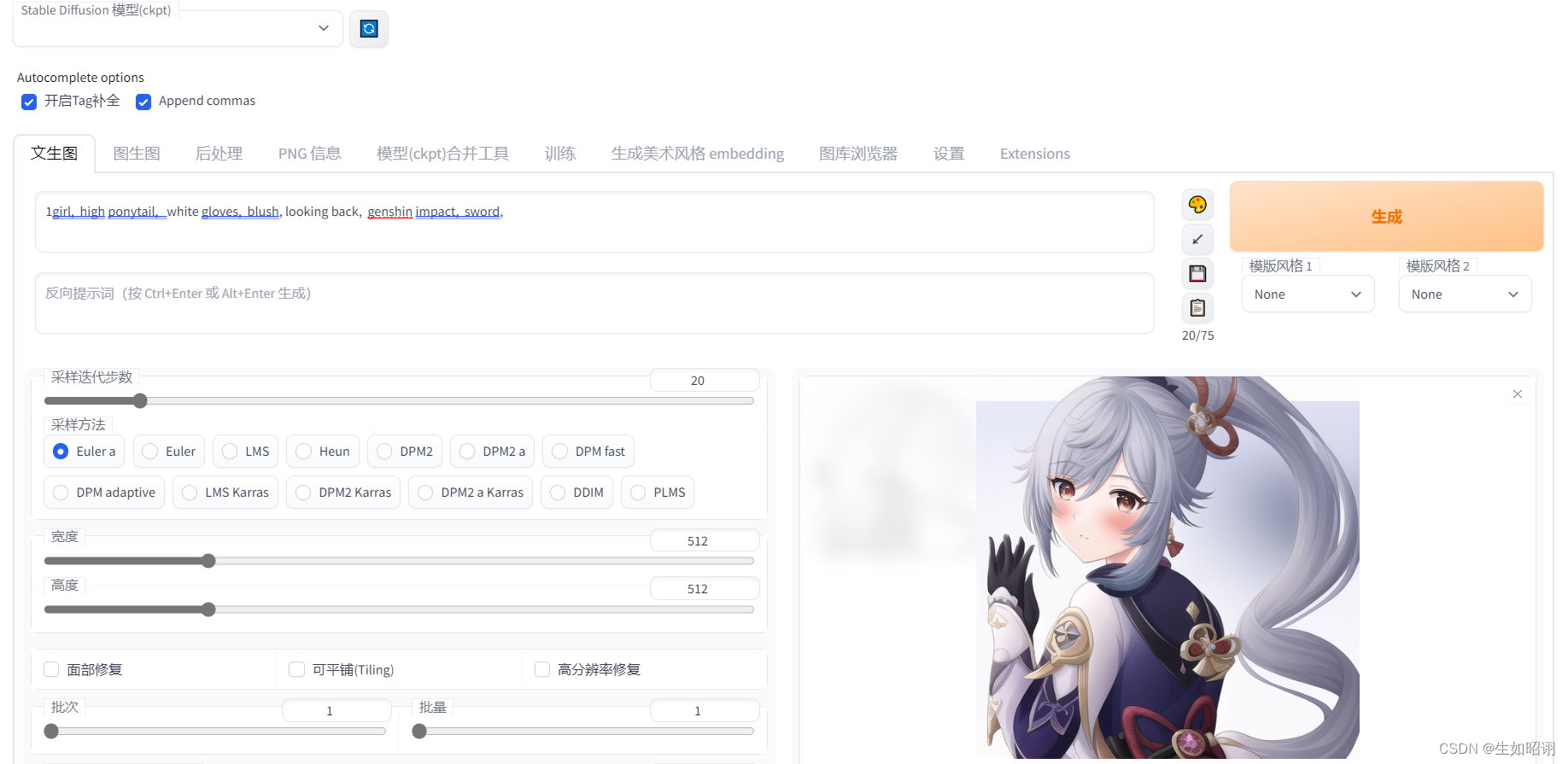
在这里分享一下自己使用该功能完成的作品:

二、AI绘画的内在原理
1. Diffusion Model的基本过程
- 什么是Diffusion Model:深度学习中的一种生成模型,与GAN、VAE、Flow-based等类似;

不同生成模型之间的对比:Diffusion model和其他模型最大的区别是它的latent code(z)和原图是同尺寸大小的。一句话概括diffusion model,即存在一系列高斯噪声,将输入图片变为纯高斯噪声。而我们的模型则负责将噪声处理后的图片复原回图片
Diffusion Model的过程:
\qquad- 前向过程:

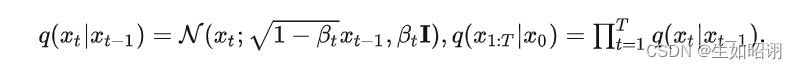
即往图片上加噪声的过程,给定真实图片后, diffusion前向过程通过多次累计对其添加高斯噪声;这里需要给定一系列的高斯分布方差的超参数,前向过程由于每个时刻t只与t-1时刻有关,所以也可以看做马尔科夫过程:这个过程中,随着t的增大, 越来越接近纯噪声
\qquad
2. 逆向过程:


即Diffusion的去噪推断过程,如果我们能够逐步得到逆转后的分布,就可以从完全的标准高斯分布还原出原图分布,我们使用深度学习模型(参数为θ,目前主流是U-Net+attention的结构)去预测这样的一个逆向的分布,通过贝叶斯公式等得到高斯噪声的参数,最终通过模型特性实现逆向;
\qquad
3. 最终通过对真实数据分布下,最大化模型预测分布的对数似然过程(上述基于DDPM)
- 具体的训练及演化过程这里不细致分析,详情可见由浅入深了解Diffusion Model
2. 扩散模型的兴起
- 相比于GAN的优势:
- GAN模型训练过程有个难点,就是众多损失函数的鞍点(saddle-point)的最优权重如何确定,在实际训练过程中需通过多次反馈,直至模型收敛,但是可怕的是在实际操作中发现,损失函数往往不能可靠地收敛到鞍点,导致模型稳定性较差;与GAN不同,DALL·E使用Diffusion Model,不用在鞍点问题上纠结,只需要去最小化一个标准的凸交叉熵损失(convex cross-entropy loss),这样就大大简化了模型训练过程中,数据处理的难度
- GAN模型在训练过程中,除了需要“生成器”,将采样的高斯噪声映射到数据分布;还需要额外训练判别器,Diffusion Model只需要训练“生成器”,训练目标函数简单,而且不需要训练别的网络(判别器、后验分布等)
- 领域跨越:目前的训练技术让Diffusion Model直接跨越了GAN领域调模型的阶段,而是直接可以用来做下游任务
Diffusion Model的成功在于训练的模型只需要“模仿”一个简单的前向过程对应的逆向过程,而不需要像其它模型那样“黑盒”地搜索模型,并且,这个逆向过程的每一小步都非常简单,只需要用一个简单的高斯分布来拟合
- 扩散模型的拓展:原始扩散模型拥有三个缺点,采样速度慢,最大化似然差、数据泛化能力弱,它的采样速度慢,通常需要数千个评估步骤才能抽取一个样本;它的最大似然估计无法和基于似然的模型相比;它泛化到各种数据类型的能力较差。如今很多研究已经从实际应用的角度解决上述限制做出了许多努力,或从理论角度对模型能力进行了分析。

- 参考文献:
[1] Sohl-Dickstein J, Weiss E, Maheswaranathan N, et al. Deep unsupervised learning using nonequilibrium thermodynamics[C]//International Conference on Machine Learning. PMLR, 2015: 2256-2265.
[2] Ho J, Jain A, Abbeel P. Denoising diffusion probabilistic models[J]. Advances in Neural Information Processing Systems, 2020, 33: 6840-6851.
[3] Song Y, Sohl-Dickstein J, Kingma D P, et al. Score-based generative modeling through stochastic differential equations[J]. arXiv preprint arXiv:2011.13456, 2020.
[4] Yang L, Zhang Z, Song Y, et al. Diffusion models: A comprehensive survey of methods and applications[J]. arXiv preprint arXiv:2209.00796, 2022.
版权归原作者 生如昭诩 所有, 如有侵权,请联系我们删除。