
【代码】
霹雳吧啦WZ☆
Github地址、 CSDN、bili主页、阿喆学习小记
【读后感】
对于网络中一些参数的设置及其设置原因解说的比较详细清晰;再自定义数据读取中,对如何读取每一个具体的文件也解说的很清晰。
需要注意的是,博主在论文原始Decoder的上采样输出channel中做了修改,以及用bilinear代替转置卷积插值(因为实验效果相差不大)。【和迪哥视频里一样提及了原论文使用的卷积层每次操作都会改变特征层的hw,而目前主流的方式是保持输入的hw不变,并且用简单的双线性插值上采样替换转置卷积。】
【听课笔记】
用Pytorch搭建U-Net网络,并基于DRIVE数据集进行训练
分割:unet、数据集和训练权重也都给了网盘link
(我下面贴的代码不一定是完整的,主要目的是为了帮助理解而不是实现)
项目参考仓库:
文件结构:
├── src: 搭建U-Net模型代码
├── train_utils: 训练、验证以及多GPU训练相关模块
├── my_dataset.py: 自定义dataset用于读取DRIVE数据集(视网膜血管分割)
├── train.py: 以单GPU为例进行训练
├── train_multi_GPU.py: 针对使用多GPU的用户使用
├── predict.py: 简易的预测脚本,使用训练好的权重进行预测测试
└── compute_mean_std.py: 统计数据集各通道的均值和标准差
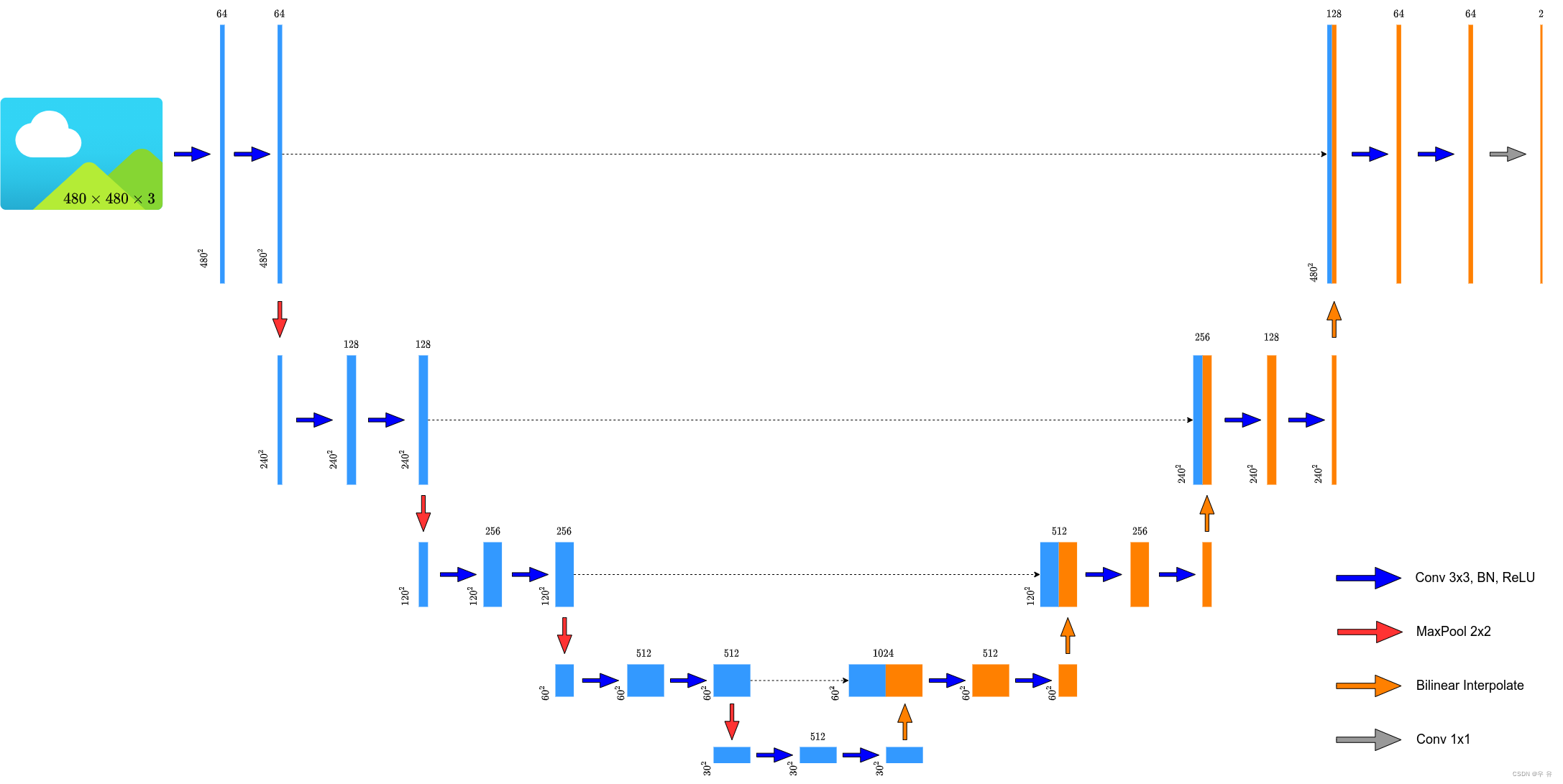 原论文使用的卷积层每次操作都会改变特征层的hw,目前主流的方式是保持输入的hw不变,并且用简单的双线性插值上采样替换转置卷积。
原论文使用的卷积层每次操作都会改变特征层的hw,目前主流的方式是保持输入的hw不变,并且用简单的双线性插值上采样替换转置卷积。
1、DRIVE数据集目录,如果不在当前目录时,设置data_path
mask是二值分割/蒙版、manual人工分割,2是精标准
【网络的搭建】
2、train中直接创建模型和参数,并没有载入其他医学影像的预训练模型
train&eval:添加了diceloss和dice.update更新指标
训练完毕之后会在当前目录下生成一个result...txt文件(epoch的log)
3、predict中首先调用训练完的权重weight_patyh=“位置”,img_path指向测试集文件img,roi_mask_path指向对应的mask路径(视频中都只选择了第一张)。运行完毕之后也会在当前目录下生成一个test_result.png的图片,可以和人工进行简单视觉对比。
4、在src里unet.py:
**(1)首先定义Doubleconv(nn.sequential)**,因为网络结构中conv成对使用,三个channel参数,就是输入inpu_c、第一个conv之后mid_c、第二个conv之后的out_c。因为现在的做法都是不改变特征层大小,所以padding=1。因为后面要用BN所以将bias设置成false.[conv、bn、relu]
class DoubleConv(nn.Sequential):
def __init__(self, in_channels, out_channels, mid_channels=None):
if mid_channels is None:
mid_channels = out_channels
super(DoubleConv, self).__init__(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
**(2)定义Down(nn.sequential)**操作:下采样+2个卷积层。调用父类的初始化函数,依次传入MaxPool和DoubleConv,池化的kernel=2,stride=2
class Down(nn.Sequential):
def __init__(self, in_channels, out_channels):
super(Down, self).__init__(
nn.MaxPool2d(2, stride=2),
DoubleConv(in_channels, out_channels)
)
**(3)定义Up(nn.Module)**操作:上采样+concat拼接+2个卷积层。传入的参数是in_c、out_c和bilinear是否采用双线性插值。如果是采用线性插值:这里的input_c是在cat之后的/送入2卷积的channel,接着定义self.up和.conv, mid_c=in_c/2;else采用转置卷积上采样(原论文中的绿色部分)[注意一下一个是绿色部分,另一个是代码方法两层卷积后512->256送入,是为了拼接方便直接可以用]

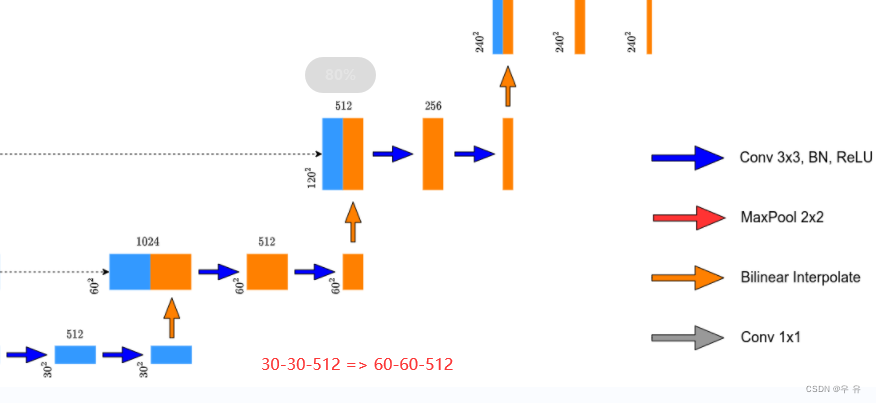
里面的forward参数x1是要上采样的特征层(橙),参数x2是要拼接的特征层(蓝),[N,C,H,W]
思路是给x1上采样然后与x2进行cat然后经过conv就结束了,但是论文作者对X1多做了一个padding是为了防止不是16的倍数而向下取整的情况(x2对x1在hw上的差值,然后基于这个差值对x1的hw进行padding,进而保证二者hw一致)。【如果本身的输入输出都是16的整数倍,这个padding等操作就可以不要了】
class Up(nn.Module):
def __init__(self, in_channels, out_channels, bilinear=True):
super(Up, self).__init__()
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1: torch.Tensor, x2: torch.Tensor) -> torch.Tensor:
x1 = self.up(x1)
# [N, C, H, W]
diff_y = x2.size()[2] - x1.size()[2]
diff_x = x2.size()[3] - x1.size()[3]
# padding_left, padding_right, padding_top, padding_bottom
x1 = F.pad(x1, [diff_x // 2, diff_x - diff_x // 2,
diff_y // 2, diff_y - diff_y // 2])
x = torch.cat([x2, x1], dim=1)
x = self.conv(x)
return x
**(4)定义OutCconv(nn.sequential)**,对应的是最后一个1x1conv,通过它可以得到输出,没有BN和relu,直接给In_c、分类类别数、kernel_size就行
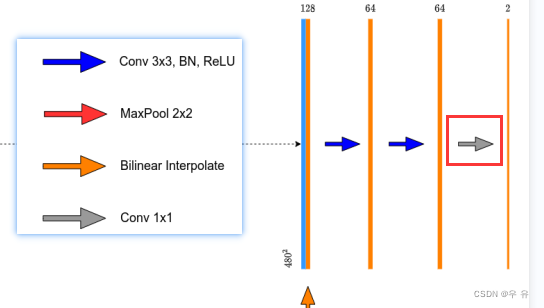
class OutConv(nn.Sequential):
def __init__(self, in_channels, num_classes):
super(OutConv, self).__init__(
nn.Conv2d(in_channels, num_classes, kernel_size=1)
)
(5)UNet网络整体搭建过程class UNet(nn.Module):①初始化传入In_c是图片的通道个数,彩色图片3灰度图1,所以在train里实例化unet网络的 时候,create_model里传入的参数in_c是3;②作者实验发现bilinear和转置卷积的实验结果是差不多的,所以使用bilinear会更高效一点;③base_c是网络第一个conv的卷积核的个数(input之后),定义=64,当然也可以进行修改,比如博主实例化UNet的时候是改成了32,发现效果也没有什么太大的变化,但是计算速度等会有较大的提升。但是还有一个原因是因为Drive数据集比较小,所以没有必要使用太宽的网络,所以自己的网络base_c还是要根据自己处理的图像任务的特性来进行调整和实验**。然后就是进行一些简单的self赋值。
// train.py 实例化UNet
def create_model(num_classes):
model = UNet(in_channels=3, num_classes=num_classes, base_c=32)
return model
定义网络结构Encoder:in_conv是第一层最开始的两个卷积,直接调用前面定义的DoubleConv,传入参数in_c和base_c, 接着就是down1_4,前三个是通道数翻倍,down4作者没有让c翻倍[与原论文不一样],目的是为了和浅层cat的时候通道数变化易于计算。
factor = 2 if bilinear else 1
bilinear不会改变channel数目,所以上采样之后得到的channel不变。所以如果采用原论文转置卷积方式那就是factor=1;如果采用作者bilinear那么factor=2,就是要/2,这样得到的channel可以直接和浅层进行cat拼接。
【弹幕:别听这人的话 (⑉・-・⑉) 请说出你的实验故事好吗】
Decoder:up1~4,up4输出就是base_c,就是说无论你输入什么,我最后的输出要和我整个网络最开始的input_c保持一致(当然这个也是可以设置的)。然后无论是原论文还是博主的代码,对于每个up,输入的channel是cat之后的channel(也就是进入每层中第一个conv的inpu_c是cat后的),最后就是一个输出的1x1conv.
self.in_conv = DoubleConv(in_channels, base_c)
self.down1 = Down(base_c, base_c * 2)
self.down2 = Down(base_c * 2, base_c * 4)
self.down3 = Down(base_c * 4, base_c * 8)
factor = 2 if bilinear else 1
self.down4 = Down(base_c * 8, base_c * 16 // factor)
self.up1 = Up(base_c * 16, base_c * 8 // factor, bilinear)
self.up2 = Up(base_c * 8, base_c * 4 // factor, bilinear)
self.up3 = Up(base_c * 4, base_c * 2 // factor, bilinear)
self.up4 = Up(base_c * 2, base_c, bilinear)
self.out_conv = OutConv(base_c, num_classes)

定义完所有的层结构之后,来定义前向传播过程,最后以字典的形式返回输出
def forward(self, x: torch.Tensor) -> Dict[str, torch.Tensor]:
x1 = self.in_conv(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.out_conv(x)
return {"out": logits}
【自定义数据集读取】
my_dataset.py:init、getitem、len方法
DRIVE数据集由training和test俩文件夹,其中
training:
├──images: 原图
├── mask: 255白色=ROI感兴趣区域,0黑色 不感兴趣区域
├── 1st_manual: 人工标注的分割血管ground truth, 255白色=血管,0黑色背景
1、init三参数:root(指向数据集的根目录),train是否载入训练数据集(bool类,1-train0-test程序定义), transforms数据预处理方式
def __init__(self, root: str, train: bool, transforms=None):
super(DriveDataset, self).__init__()
self.flag = "training" if train else "test"
data_root = os.path.join(root, "DRIVE", self.flag)
assert os.path.exists(data_root), f"path '{data_root}' does not exists."
self.transforms = transforms
img:先得到每张图片的名称,然后进行拼接得到每张图片的路径
img_names = [i for i in os.listdir(os.path.join(data_root, "images")) if i.endswith(".tif")]
self.img_list = [os.path.join(data_root, "images", i) for i in img_names]
manul:发现它和img的“_”前面序号是一样的,就是_后面不同。所以可以根据_进行分割,取前面的序号[0],然后+后面内容进行拼接。然后就是和img操作一样,对data_root+“1st_manual”+每个文件名称进行拼接,这样就可以得到每一个manual文件的路径(注意格式“文件夹”)。 然后可以加一个checkfiles判断文件是否存在,如果不存在就报错。
self.manual = [os.path.join(data_root, "1st_manual", i.split("_")[0] + "_manual1.gif")
for i in img_names]
# check files
for i in self.manual:
if os.path.exists(i) is False:
raise FileNotFoundError(f"file {i} does not exists.")
roi_mask:同上述方法一直,去构建每一个mask文件的路径,还是序号一致但_后不同,split分割取值. 然后判断一下,如果传入的train是true的话,那么{self.flag}对应的字段就是training否则就是test,然后再加上文件名称后面的剩余内容,这样就可以获取到roi_mask里每一个文件的名称。同上,用os.path.join讲它们全部拼在一起,就可以得到每一个roi_mask的路径,同样需要判断文件是否存在。
self.roi_mask = [os.path.join(data_root, "mask", i.split("_")[0] + f"_{self.flag}_mask.gif")
for i in img_names]
# check files
for i in self.roi_mask:
if os.path.exists(i) is False:
raise FileNotFoundError(f"file {i} does not exists.")
2、getitem方法:传入索引Idx,return的mask和前面Init的roi_mask不一样,这里的mask是gt
需要打开索引idx对应的img_list和manual文件。
首先就是将img图片转换成RGB(DRIVE数据集本来就是,但是如果自己跑的其他数据集不是RGB的话就不要忘记这一个步骤了)。
然后manual人工分割血管要转换成灰度图,之前voc数据集中讲过,前景/目标=从1开始,背景=0,因为血管manual只有目标前景255背景0,所以可以直接将前转换成Numpy格式之后除以255就可以了。
然后用image.open打开idx对应的roi_mask图片(一个圈,roi=255 else=0).这里做的一个操作是取反,就是用255-像素值,这样roi=0背景=255,这样做的目的是为了最后构建mask计算损失的时候将RGB=255的区域全部忽略掉。然后+,再np.clip设置上下限(0,255)。所以最后mask的前景目标区域=1,mask背景区域=0,不感兴趣区域=255,简单说就是:1-血管0-roi背景255忽略区域.
def __getitem__(self, idx):
img = Image.open(self.img_list[idx]).convert('RGB')
manual = Image.open(self.manual[idx]).convert('L')
manual = np.array(manual) / 255
roi_mask = Image.open(self.roi_mask[idx]).convert('L')
roi_mask = 255 - np.array(roi_mask)
mask = np.clip(manual + roi_mask, a_min=0, a_max=255)
然后再将mask转换成PIL图片格式,这样做的原因是transform中定义的一系列方法都是针对PIL格式进行处理的,所以不去修改transform的方法,而是直接将mask转换成PIL的格式。
# 这里转回PIL的原因是,transforms中是对PIL数据进行处理
mask = Image.fromarray(mask)
if self.transforms is not None:
img, mask = self.transforms(img, mask)
return img, mask
3、len方法:返回当前数据集数目
4、对于collate_fn的作用就是将img/targets打包成batch(在博主的fcn源码中有详细讲解)
【Dice损失计算】

越准越大
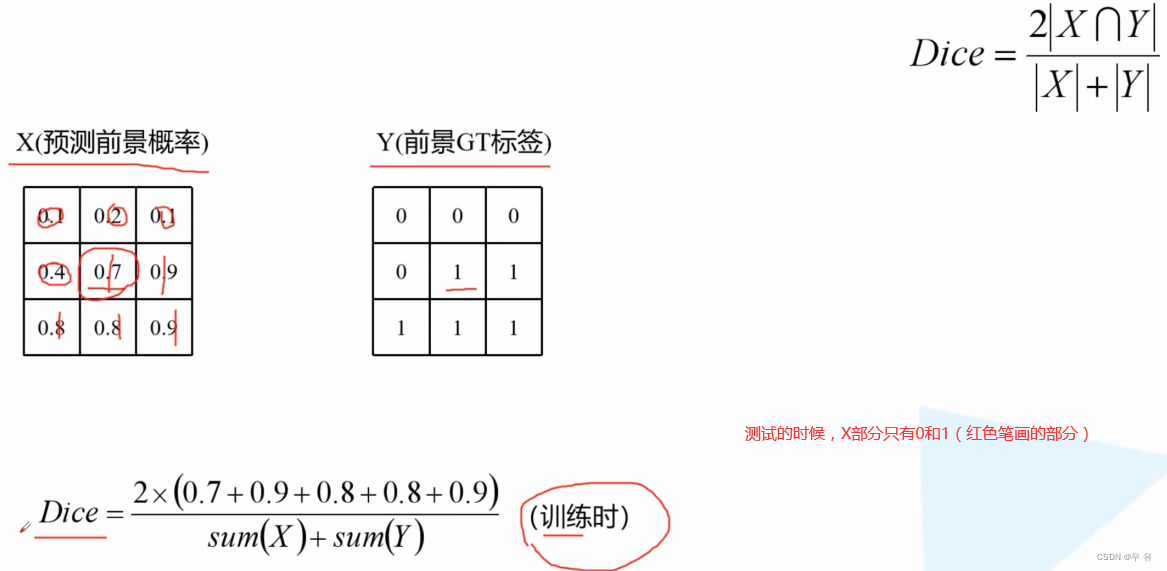
** train_and_eval**:
criterion
def criterion(inputs, target, loss_weight=None, num_classes: int = 2, dice: bool = True, ignore_index: int = -100):
losses = {}
for name, x in inputs.items():
# 忽略target中值为255的像素,255的像素是目标边缘或者padding填充
loss = nn.functional.cross_entropy(x, target, ignore_index=ignore_index, weight=loss_weight)
if dice is True:
dice_target = build_target(target, num_classes, ignore_index)
loss += dice_loss(x, dice_target, multiclass=True, ignore_index=ignore_index)
losses[name] = loss
if len(losses) == 1:
return losses['out']
return losses['out'] + 0.5 * losses['aux']
首先计算每一个像素的cross_entropy,如果dice参数为true那就计算diceloss:首先build_target,然后计算dice_loss,每一个类别分别计算dice系数然后取均值。
针对每一个类别都需要计算gt(前景、背景,所以每个类别都要构建gt),具体build_target见↓
然后将构建好的target和网络预测的x一起传入到dice_loss方法中去计算损失
在dice_coefficient_loss里:build_target定义
首先clone的target是上面的Y(GT标签),然后判断一下传入的ignore_index是否≥0(定义里默认是-100,我们传入的是255很显然>0)。首先通过torch.eq方法寻找target中所有=255的像素点位置,记作ignore_mask,然后将这些位置数值全部设置为0。
然后利用torch提供的one_hot方法将dice转换成onehot编码形式。这里num_classes=2,就是只有背景和前景俩类别,背景区域对应的One-hot编码是10,前景区域对应的one-hot编码是01(你属于啥就是1else=0),这样就达成将原始的groundtruth转换成针对每一个类别的gt=>得到Onehot编码之后的GT。然后再将原来255的区域填充回去,这样在计算每一个类别的dice_coefficient_loss的时候其实就是去计算非255区域即可(下图)。
需要注意的是,onehot编码维度从NHW=>NHWC,而torch中默认将channel放在索引为1的位置,所以需要使用permute方法将channel对应的维度放在索引为1的位置上去,然后返回target.
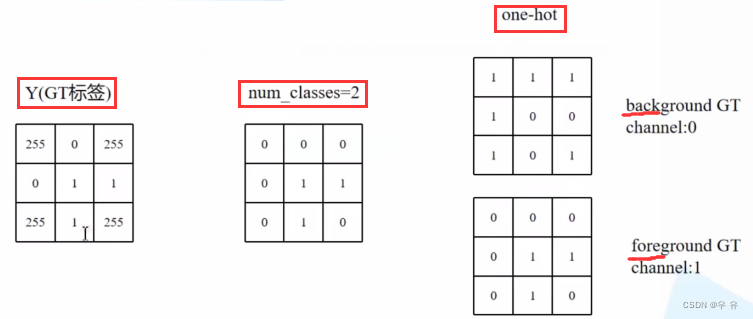
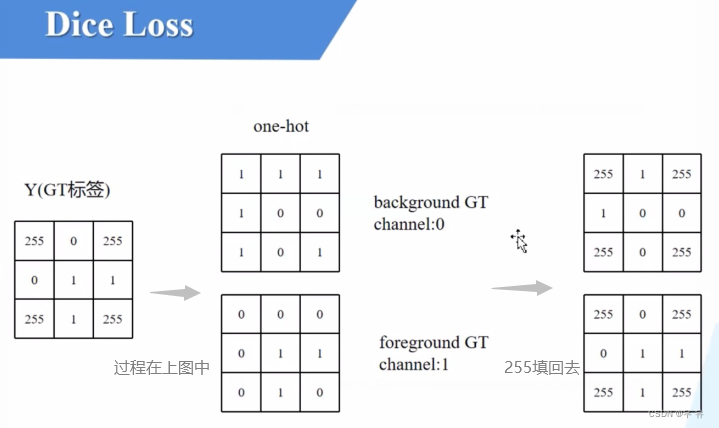
在dice_coefficient_loss里:dice_loss方法定义
首先对预测值x在dim=1即channel方向做一个softmax处理,就可以得到每个像素针对每一个类别的概率;
接着如果传入的multiclass参数为true的话,就采用multiclass_dice_coeff否则dice_coeff,博主这里是true,也就是分别去计算每一个类别的dice_loss得到fn;
然后通过上述x,fn,ignore_index去计算针对当前batch数据的dice_coeff,然后用1减去这个值就可以得到损失。
def dice_loss(x: torch.Tensor, target: torch.Tensor, multiclass: bool = False, ignore_index: int = -100): # Dice loss (objective to minimize) between 0 and 1 x = nn.functional.softmax(x, dim=1) fn = multiclass_dice_coeff if multiclass else dice_coeff return 1 - fn(x, target, ignore_index=ignore_index)multiclass_dice_loss方法定义
遍历每一个channel,就是每一个类别的预测值x以及target去计算dice_coeff,并相加,最后除以通道数x.shape[1]=channel=类别个数,得到所有通道的dice_coeff均值。
def multiclass_dice_coeff(x: torch.Tensor, target: torch.Tensor, ignore_index: int = -100, epsilon=1e-6): """Average of Dice coefficient for all classes""" dice = 0. for channel in range(x.shape[1]): dice += dice_coeff(x[:, channel, ...], target[:, channel, ...], ignore_index, epsilon) return dice / x.shape[1]dice_coeff如何计算
x是针对某一个类别的预测概率矩阵,target是针对某一个类别的gt,一样,ignore_index就是需要忽略的数值区域。
for i in range(batch_size):通过x_i取出当前batch中第i张图片对应某一类别的预测概率矩阵
然后x[i].reshape(-1)就是向量的形式,对target[i]也是同样操作,取出图片对应target并reshape成向量,所以得到两个向量x_i和t_i
def dice_coeff(x: torch.Tensor, target: torch.Tensor, ignore_index: int = -100, epsilon=1e-6): # Average of Dice coefficient for all batches, or for a single mask # 计算一个batch中所有图片某个类别的dice_coefficient d = 0. batch_size = x.shape[0] for i in range(batch_size): x_i = x[i].reshape(-1) t_i = target[i].reshape(-1) if ignore_index >= 0: # 找出mask中不为ignore_index的区域 roi_mask = torch.ne(t_i, ignore_index) x_i = x_i[roi_mask] t_i = t_i[roi_mask] inter = torch.dot(x_i, t_i) sets_sum = torch.sum(x_i) + torch.sum(t_i) if sets_sum == 0: sets_sum = 2 * inter d += (2 * inter + epsilon) / (sets_sum + epsilon) return d / batch_size然后if ignore_index >=0,在里面找出不为255即我们真的感兴趣区域,得到roi_mask,提取出其中的x_i和它对应的target的t_i,将这俩向量进行dot内积操作(相乘求和),得到inter. 分母就是相加,就是下面这个过程。
(一个判断就是if分母=0,意味着XY都=0,那就是预测值和target标签都是=0,说明我们的预测是正确的,所以就将sets_sum设置成2*inter)
然后用公式计算就可以了,epsilon是一个很小的数值,是为了避免出现分母极小的情况。
【对于不理解的部分,可以设置断点调试,像下面迪哥视频里forward断点调试一样】
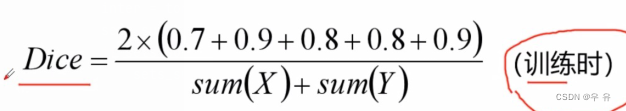
evaluate验证过程
创建了DiceCoefficient类,会计算验证过程中的dice_coeff:dice.update(output, target)
distributed_utils这里的DiceCoefficient类的update方法中,argmax找到每一个像素所有类别中概率最大的类别的预测数值,也转换成Onehot编码的形式,同样也需要进行permute将channel移动到dim=1索引1的位置上,作为pre. 其实也就是如下图所示,前面所讲的X这里验证预测的不是概率而是0/1数值组成的。
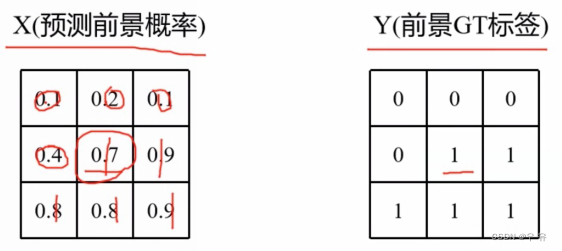
然后这里的计算时忽略背景的,channel是从1开始取的(channel-0对应的是背景),
multiclass_dice_coeff(pred[:, 1:], dice_target[:, 1:], ignore_index=self.ignore_index)
然后调用value属性的时候直接用累计的dice_coff除以累计的样本个数count就可以得到其均值。
【讲解就到这里结束了,但是渔法可以在其他文件中同样去钓】
UNet网络结构讲解(视频)
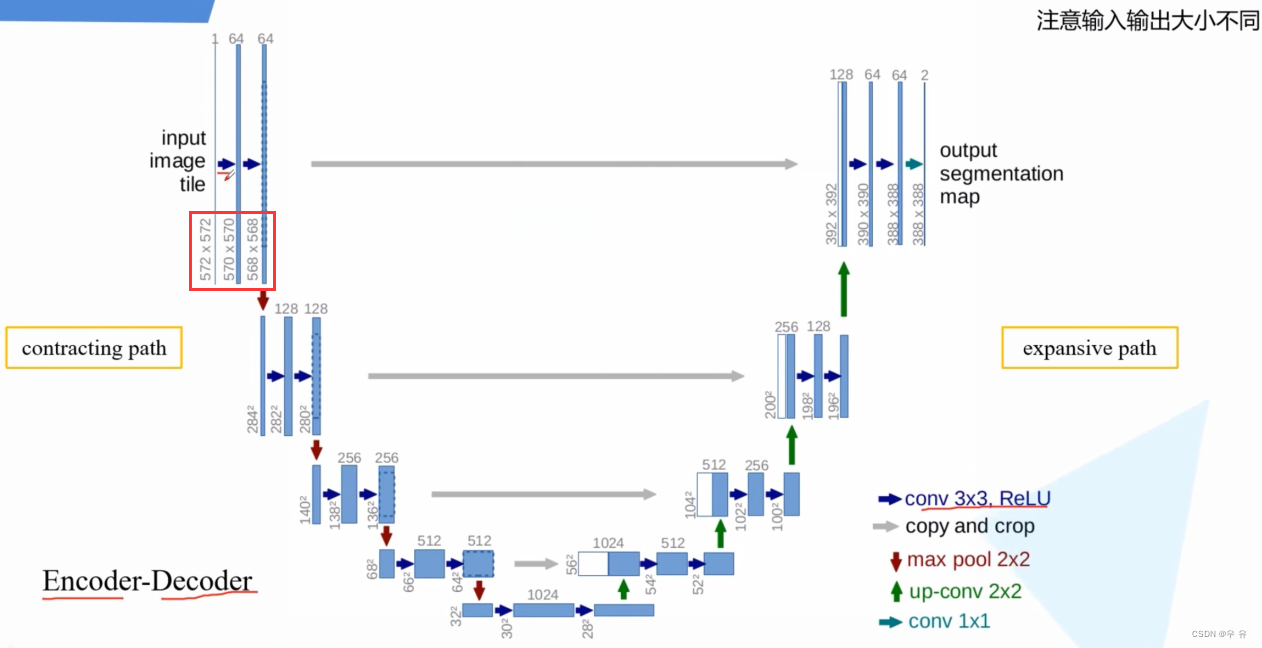
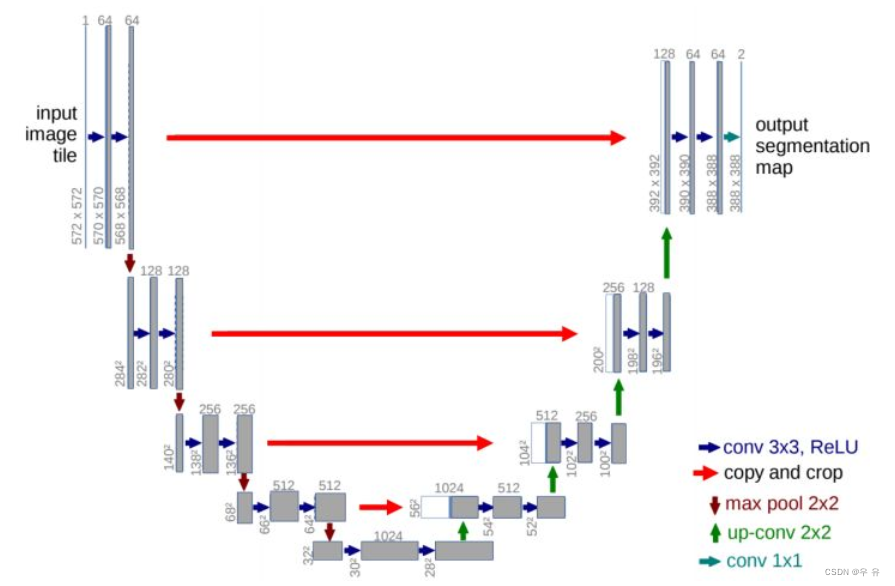
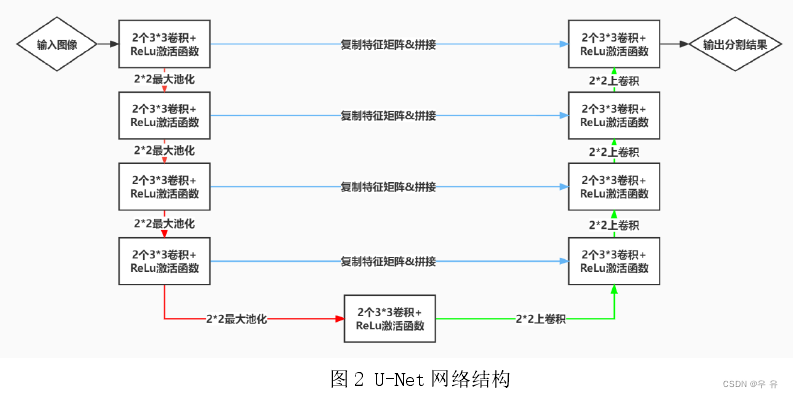
Encoder部分:input后面的conv没有padding且stride=1,所以会发现通过conv之后hw都会减少572x572=> 570x570=> 568x568,而且当时的UNet还没有使用到BN模块。经过maxpool2x2通道数channel不会发生变化,hw变一半;接着后面每经过一个conv通道数都会翻倍。
Decoder部分:原论文里上采样使用的是转置卷积,将原来的hw都放大两倍,channel减半。然后将左边牵过来的浅层特征进行拼接。需要注意的是,以最下面一层的拼接为例,左边浅层是64x64, 而右边深层是56x56,很明显二者没有办法直接拼接,所以就对左侧的浅层特征进行中心裁剪,然后二者进行拼接,这样channel就变成1024了,然后再经过两个3x3conv对hwc调整,然后上采样。类似的,每一层cat之前都先对左侧浅层特征进行中心裁剪操作再拼接,再经过两个3x3conv对hwc调整,再上采样。直到最后一个结束得到388x388x64
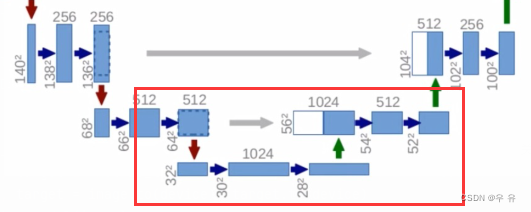
输出:通过一个1x1conv,其卷积核的个数与需要分类的个数保持一致,论文中是两类,所以最后输出的就是388x388x2的分割图,并且最后一个conv是没有relu激活函数的。
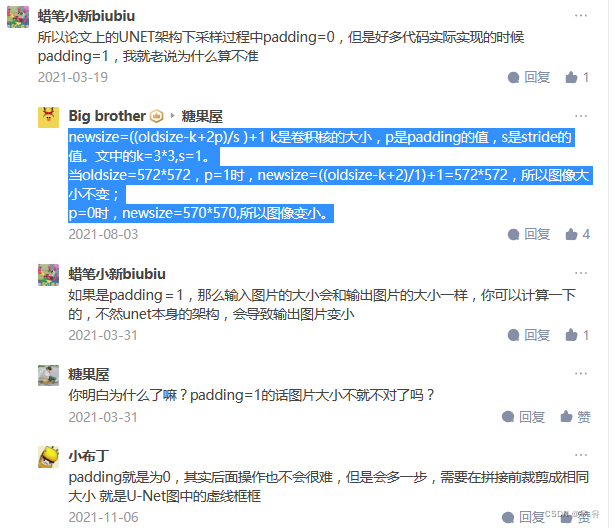
发现input是576x576x1,output是388x388x2,所以这里得到的分割图并不是针对原图的完全对应的分割图,而是只有中间388x388区域的分割图。***=>目前主流的方法是将Input后面卷积里加上padding,不去改变图片的hw,并且在conv和relu中间加上BN.这样在cat的时候浅层就不需要中心裁剪了,可以直接拼接,然后后续操作***。
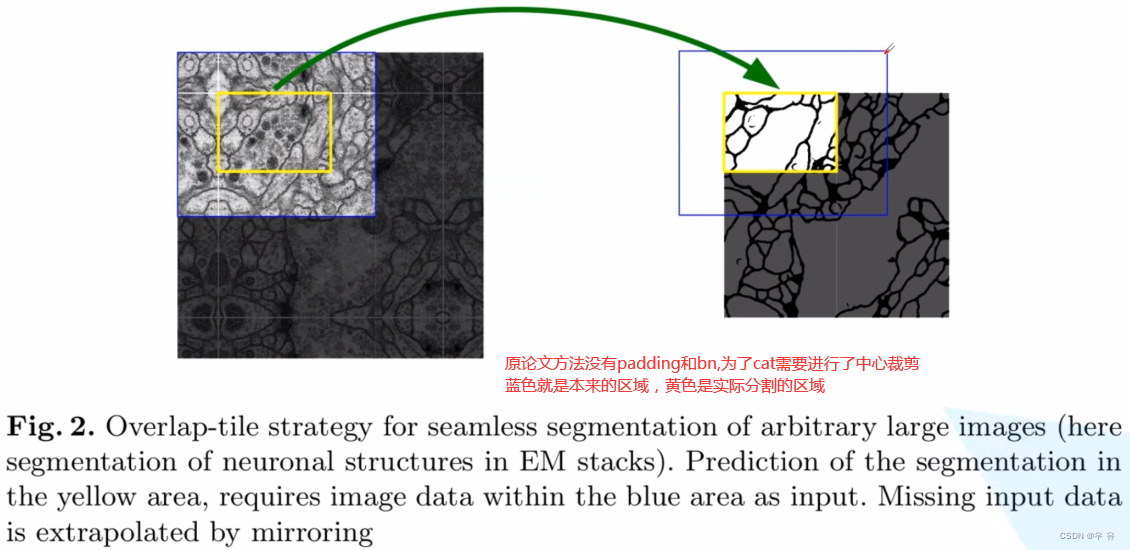
对于高分辨率的影像图片,采用每次分割batch送入的方法,其中相邻batch之间会有一个重叠部分overlap,这样做的目的是考虑到分割边界区域的信息。
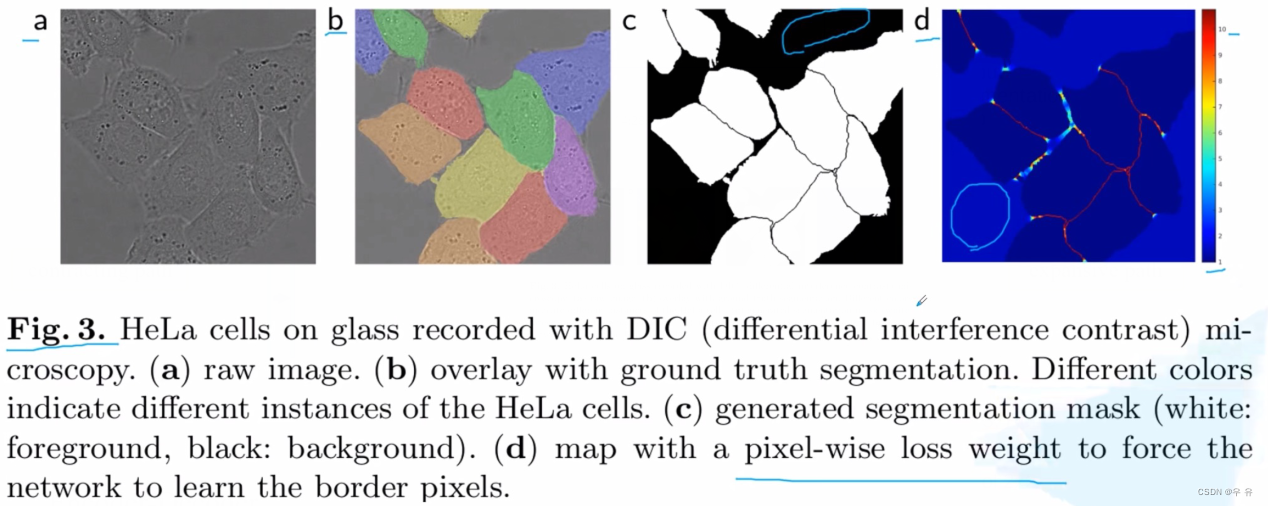
a.待分割的灰度图(原图)
b.人工标注的实例标签数据(每个细胞用不用的颜色表示)
c.gt-前景白色 背景黑色(语义分割任务而言只有2类别)
细胞之间的地方分割比较难,所以使用pixel-wise loss weight施加比较大的权重,对于大面积黑色就赋予较小的权重(理论上这个方法有效,但论文中作者并没有给出实验效果)
d.训练热力图,1~10红色值更大,看到细胞之间的颜色很深
Bubbliiiing☆
【读后感】
bubling小哥你的代码注释待客周全!(网络中有些代码的整合度比较高,直接上手不好理解的话可以听完霹雳的课再来)
【听课笔记】
Pytorch搭建自己的语义分割平台(视频教程)
源码地址、博客地址(相关连接)
常见问题记录
UNet网络构建思路:

第一部分是主干特征提取部分Encoder,我们可以利用主干部分获得一个又一个的特征层,Unet的主干特征提取部分与VGG相似,为卷积和最大池化的堆叠。利用主干特征提取部分我们可以获得五个初步有效特征层,在第二步中,我们会利用这五个有效特征层可以进行特征融合。
第二部分是加强特征提取部分Decoder,我们可以利用主干部分获取到的五个初步有效特征层进行上采样,并且进行特征融合,获得一个最终的,融合了所有特征的有效特征层。(最终的特征层相当于整个网络的特征浓缩)
第三部分是预测部分,我们会利用最终获得的最后一个有效特征层对每一个特征点进行分类,相当于对每一个像素点进行分类。(只需要根据分类的类别个数对通道数的进行调整就可以了)
程序结果整理:
nets文件夹:
├──vgg.py:Encoder主干网络
├──unet.py:Decoder加强特征提取/cat
├──
predict.py:
unet.py:
训练过程:
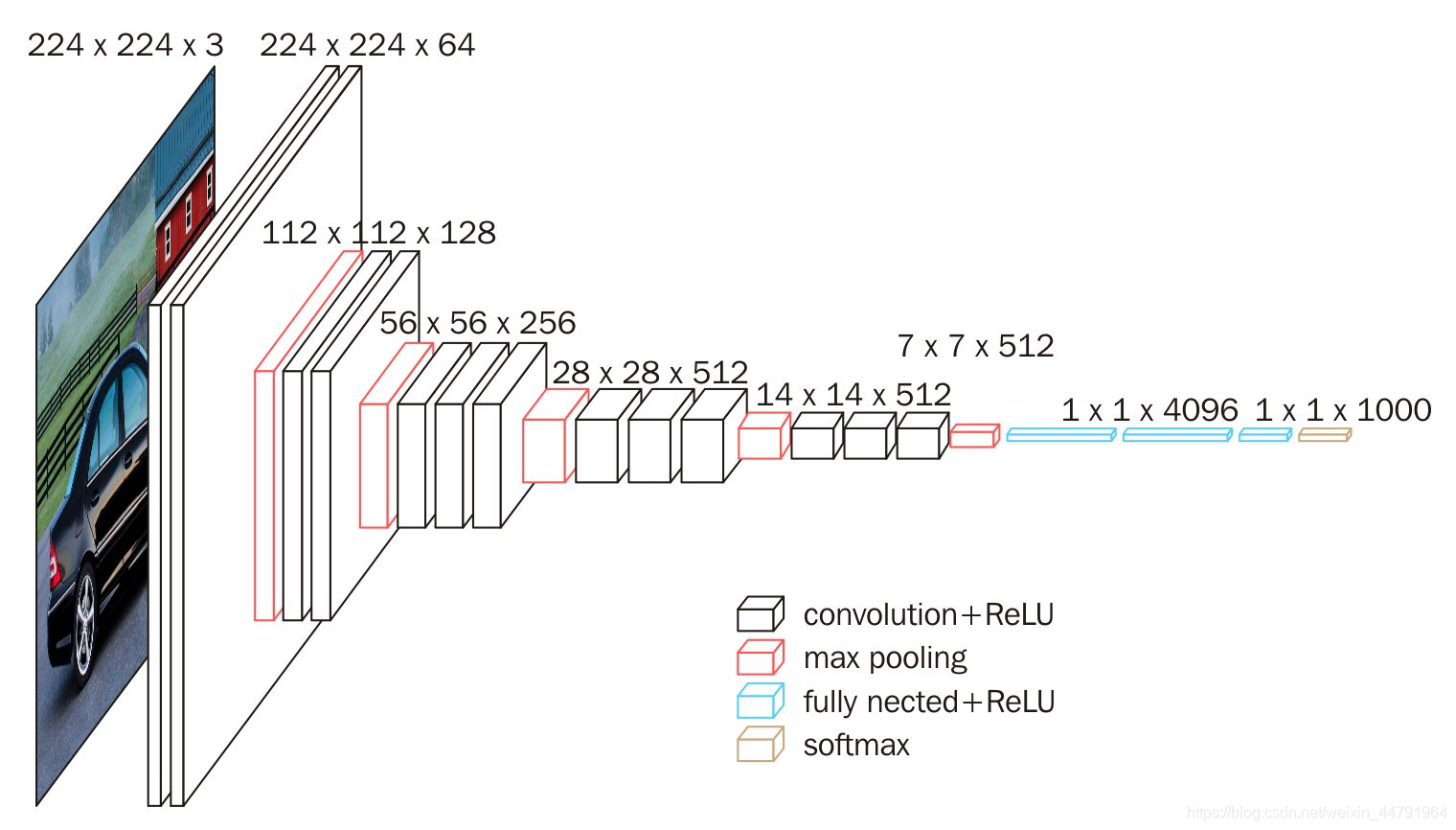
BackBone:主干特征提取网络VGG16,获得五个初步的有效特征层。
vgg.py中make_layers函数:
def make_layers(cfg, batch_norm=False, in_channels = 3):
layers = []
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
cfgs = {
'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M']
}
利用for v in cfg对列表进行循环,判断是数字还是单词M,如果是单词M那就是要进行最大池化,else数字就是卷积的通道数。
cfgs = { 'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'] }
input=512,512,3=(2conv)=>512,512,64=(maxpool)=>256,256,64=(2conv)=> 256,256,128=(maxpool)=>128,128,128=(3conv)=>128,128,256=(maxpool)=>64,64,256=(3conv)=>64,64,512=(maxpool)=>32,32,512=(3conv)=>32,32,512 最后一次最大池化在UNet中没有用到,所以不用。就将最后32x32x512的特征层引出作为Decoder部分的构建初步。【dim的数值变化去看参数定义里面的kernel_size和stride,stride=1是hw不变,conv的input/output都有设置】
所以在class VGG(nn.Module)中init传入的features就是make_layers构建的网络结构,后面的全链接部分并没有使用到。
Decoder加强提取网络:repeat(上采样、堆叠、2次卷积)
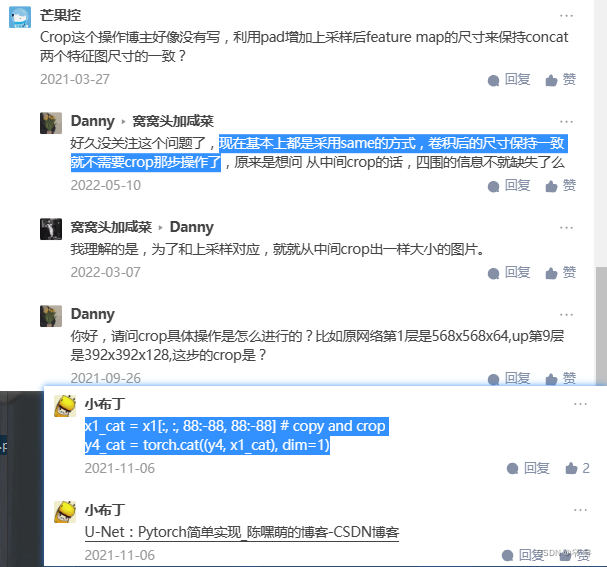
bubling和后面迪哥/霹雳中提到的都一样,没有用到crop操作,直接让输入的hw和输出的hw保持一致,这样网络就会更加具有通用性。
看unet.py里面class unetUp(nn.Module):上采样的定义
init里面定义了2conv+1upsample;forward参数inputs1是浅层inputs2是深层,先对s2上采样然后和s1进行cat,得到的结果再进行2conv,return这个outputs
class unetUp(nn.Module):
def __init__(self, in_size, out_size):
super(unetUp, self).__init__()
self.conv1 = nn.Conv2d(in_size, out_size, kernel_size = 3, padding = 1)
self.conv2 = nn.Conv2d(out_size, out_size, kernel_size = 3, padding = 1)
self.up = nn.UpsamplingBilinear2d(scale_factor = 2)
self.relu = nn.ReLU(inplace = True)
# input1是传过来的浅层特征,input2是深层特征;
# 思路就是: 上采样、堆叠、卷积(简单的特征融合)
def forward(self, inputs1, inputs2):
outputs = torch.cat([inputs1, self.up(inputs2)], 1) # 首先对input2进行上采样,再与input1进行堆叠
outputs = self.conv1(outputs) # 然后进行两次卷积操作
outputs = self.relu(outputs)
outputs = self.conv2(outputs)
outputs = self.relu(outputs)
return outputs
在class Unet里面定义了out_filters对应每一次up之后的channel数
通过上VGG可知,最后一个是32,32,512,所以通道是512,所以上采样之后就是64,64,512;那么经过第二个up_cat操作之后得到128,128,256;up_cat3得256,256,128;up_cat4得到512,512,64
pre_output利用最后一个特征浓缩得到预测结果(借助一个1x1conv)
在train.py里面的Unet函数定义中:对输入进来的图片每一个像素点进行分类self.final = nn.Conv2d(out_filters[0], num_classes, 1)。同样在forword里面也是final = self.final(up1)
预测过程:
简述预测过程:输入一张图片,首先备份,计算其hw,利用letterbox_img进行不失真的resize,接着做图片归一化和batchsize的添加,并用transpose把channel放到dim=1维度。接下来就是把图片送入网络中进行预测,选取图片中每一个像素的最大概率类别,并去除灰条。处理完毕之后判断每一个像素点的种类并涂色,就可以得到分割图,将分割图与原始图进行混合。Done.
predict.py中的detect_image方法(在源目录下的Unet.py里)|| 新提供的代码有比较整合较长
输入是一张图片,首先对数据进行deepcopy备份,并记录hw;
接着进行letterbox_img操作:本质是一种不失真的resize,就是在图像的边缘添加灰条使得图像的主体部分不失真;
接着对图片归一化,加上batchsize的维度;考虑到torch要求channel在dim=1,所以要transpose;
然后就是将获取的图片传入网络.net中进行预测,对预测结果进行permute操作,将通道数转到最后一维;对预测结果取softmax,取出每个像素点对应的最大概率类别;
因为.net输入的图片时经过letterbox_img得到的结果是有灰条的,所以紧接着要对预测结果进行截取处理;
然后在对每一个像素点进行种类判断,并赋予相应的颜色;
将获取的分割图像转换为image,进行resize;
最后就是视觉呈现上将old_img与seg_img进行混合。
预测中的inputshape和train中的Inputshape保持一致
blend参数用于控制是否将识别结果与原图混合
Dataset:
VOCdevkit \ VOC2007:
├──ImageSets \ Segmentation:
├──train.txt: 训练文件-用于训练的图片的名称,除去后缀(10582) ├──val.txt: 验证文件-用于验证的图片的名称,也除去后缀(1449),计算iou (没有test.txt是因为voc的test数据集没有提供标签文件)├──JPEGImages:原图片 .jpg(17126)
├──SegmentationClass: 标签文件 .png(12032)
jpg是原图png是标签
打开下面标签png:灰度图,1个通道,位深度=8,0-255;每一个像素点上的数值就是它所属的种类。虽然看着是黑白但其实不是的,框起来的飞机圈圈里面虽然看着黑色但其实它的标签数值=1;白色的是不易区分的边缘,voc给它设置的很大,在训练时候是忽略这些像素点的;对于左下角的人,在voc数据集中对应的标签数值是15,所以圈起来的人看起来是黑色的但它的标签数值是15。


制作语义分割的数据集
datasets:
├──before:有jpg和jason
├──JPEGImages:原图
├──SegmentationClass:分割标签文件.png
运行json_to_dataset.py
首先修改参数path和num_classes(n+1),然后运行就可以了。生成目录下PEGImages和SegmentationClass就可以把他俩复制到之前的VOC2007目录下,然后就是训练。
训练参数Parameter(视频讲解版):
Cuda = True
num_classes = 21 //☆
backbone = "vgg"
model_path = "model_data/unet_vgg_voc.pth"//☆
input_shape = [512, 512]
整个模型训练分为两个阶段:冻结阶段、解冻阶段。(设置冻结阶段是为了满足机器性能不足的同学的训练需求)
冻结阶段训练参数:此时模型的主干被冻结了,特征提取网络不发生改变;占用的显存较小,仅对网络进行微调。(然后这个freeze_lr再最新的代码里 两个阶段被合并到一起)
Init_Epoch = 0
Freeze_Epoch = 50 //训练50-0=50 epoch
Freeze_batch_size = 2 //冻结时模型占用的显存较小,这可以大一些4-8
Freeze_lr = 1e-4 //冻结阶段模型调整的参数较小,可大一点来跳出局部最优解
解冻阶段训练参数:此时模型的主干不被冻结了,特征提取网络会发生改变;占用的显存较大,网络所有的参数都会发生改变。(因为UNet网络中没有批标准化层,所以batch_size可设为1?)(由于resnet50中有BatchNormalization层,当主干为resnet50的时候batch_size不可为1。关于BN与batchsize的关系整理在之前的 blog里)
UnFreeze_Epoch = 100 //训练是100-50=50epoch
Unfreeze_batch_size = 2 //占用显存大,小一点(和前一样自行调整)
Freeze_lr = 1e-5 //调整的参数较多,lr小一点保证模型训练的稳定性
然后就设置数据集路径,默认放在根目录下 VOCdevkit_path = 'VOCdevkit'
是否使用dice_loss、focal_loss(背景像素点多目标像素点少)【抽空夸一下bubling你的代码注释真的很周到!】
设置是否给不同种类赋予不同的损失权值,默认是平衡的。设置的话,注意设置成numpy形式的,cls_weights的长度和num_classes一样。
cls_weights = np.ones([num_classes], np.float32)
//比如:
num_classes = 3
cls_weights = np.array([1, 2, 3], np.float32)//①
cls_weights = np.array([3, 2, 1], np.float32)//②
num_workers 用于设置是否使用多线程读取数据,1代表关闭多线程
miou:
up视频这里用的是deeplab.py:上来还是修改model_path和Num_classes
然后返回get_miou.py:
miou_mode用于指定该文件运行时计算的内容,一般miou_mode=0代表整个miou计算流程,包括获得预测结果、计算miou,结果保存在miou_out里面(也可=1=2);
这里的num_classes要和deeplab/train里面设置的一样;
name_classes表示区分的种类,要和json_to_dataset里面的一样;
VOCdevkit_path = 'VOCdevkit';
10%的验证集用于验证和计算miou:利用自己训练好的语义分割 模型进行miou计算;
训练other医药数据集:
标签png:黑色=0边缘、白色=255背景;(与voc不一样,voc中标签值=要区分的种类)
在train_medical.py:
只需要区分背景和cell边缘,所以num_classes=2;
预训练pretrained = True,因为使用主干网络的预训练权重;
model_path = ""表示不会加载整个模型的预训练权重,而是在backbone的基础上进行训练。【终于明白up为什么把Encoder和Decoder分开py来写,可以只用en就backbone的特征提取网络的预训练权重】
预训练权重:模型的预训练权重用于进行特征提取,对不同数据集是通用的,因为特征是通用的。(预训练权重对于99%的情况都必须要用,不用的话主干部分的权值太过随机,特征提取效果不明显,网络训练的结果也不会好。训练自己的数据集时提示维度不匹配正常,预测的东西都不一样了自然维度不匹配。)
代码实现:

因为标签的格式和普通的不太一样,所以dataloader_medical.py里会进行一些额外的处理:判断标签中每一个像素点的值,将所有<127.5的像素值设置成1,即目标类别,其他像素点设置为0,这样将背景像素点和目标像素点进行人为区分,0&1,传入网络中进行训练。(没有miou测试)
modify_png = np.zeros_like(png)
modify_png[png <= 127.5] = 1
seg_labels = modify_png
seg_labels = np.eye(self.num_classes + 1)[seg_labels.reshape([-1])]
seg_labels = seg_labels.reshape((int(self.input_shape[0]), int(self.input_shape[1]), self.num_classes + 1))
如何运用训练好的医药数据集进行预测:logs下存放了训练好的权重.pth文件,在Unet.py里修改model_path,然后运行predict.py文件进行预测(输入图片路径)
麋鹿
读后感:
V1讲框架流程、V2V3狠真实,日常各种报错|预处理|size|格式|维度;“又出错了 狠棒狠棒 T T”
看V1脑袋有个框架,后面两个有较多设计预处理等报错.注意num_classes和weight_path
V1(视频教程)、源码:github、gitee
【个人记录】
data:原jpg=>png——.replace('png','jpg')
utils:预处理——先 max h&w,统一之后再resize
nets:①P2的04:12提到预处理的一个点:用reflect代替全0填充,保证全图都有特征,加强提取特征的能力;②加padding是为了保持形状不变,dim:NCHW=0123:
Downsample里:nn.conv2d(c,c,3[3x3卷积],2[stride],1[填充为1],paddingmode=reflect);
Upsample里:interpolate插值法、torch.cat((out,feature),dim=1)
train:思路还是一样,先cude再weightpath实例化;P3路径、图片拼接显示的代码
test:实例化网络、加载权重.input-归一化-升维-送网络-输出
评论区有一些报错及答疑,以及围绕resize的一些讨论
V2重新梳理UNet(视频)、源码github
【个人记录】
官方是有labelme生成mask脚本的
make_mask_data:先取出所有的jason文件temp_data,然后遍历拿到jason文件
jason坐标显示、Image.new、.polygon画多边形、tuple元组转换、如何显示mask(22min)
get_evaluation:指标MIOU、keep_image_size_open
net.eval()容易忘记[test.py]:唤醒norm和dropout
神经网络输出也是单通道的,所以要有个处理,改成三通道输出
cv2.waikey、torch.permute、.astype(int)
分割的过程/可视化-不同数值赋值、rgb问题、维度问题、尺寸size不一样问题、输出通道问题;
V3:UNet完结篇
调用One-hot(只在一个通道上为1else均为0),以tensor形式:transform后面再.long()
set(img.reshape(-1)展平.tolist())
以2类别为例:先make_mask生成,再vis_label可视化(可以只打印label,=N+1背景)
function:input->transform预处理-加维度加批次->.eval()/argmax(1)得256/squeeze()、uns...->permute.detach.numpy->result
cv.imshow('out',out255.0)这里与显示都要注意位置
评价指标MIOU/Recall/Precision、github代码、CSDN、
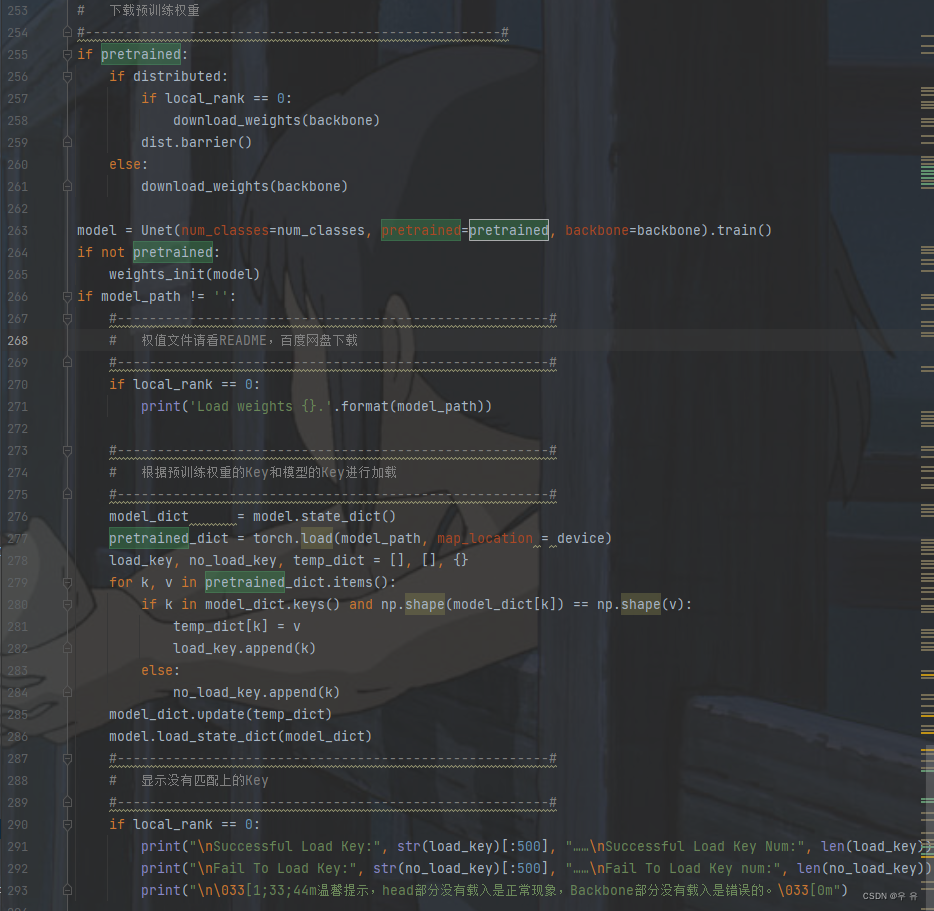
混淆矩阵:from sklearn.metrics import confusion_matrix ,miou的计算大概思路↓
 以0-0为例:
以0-0为例: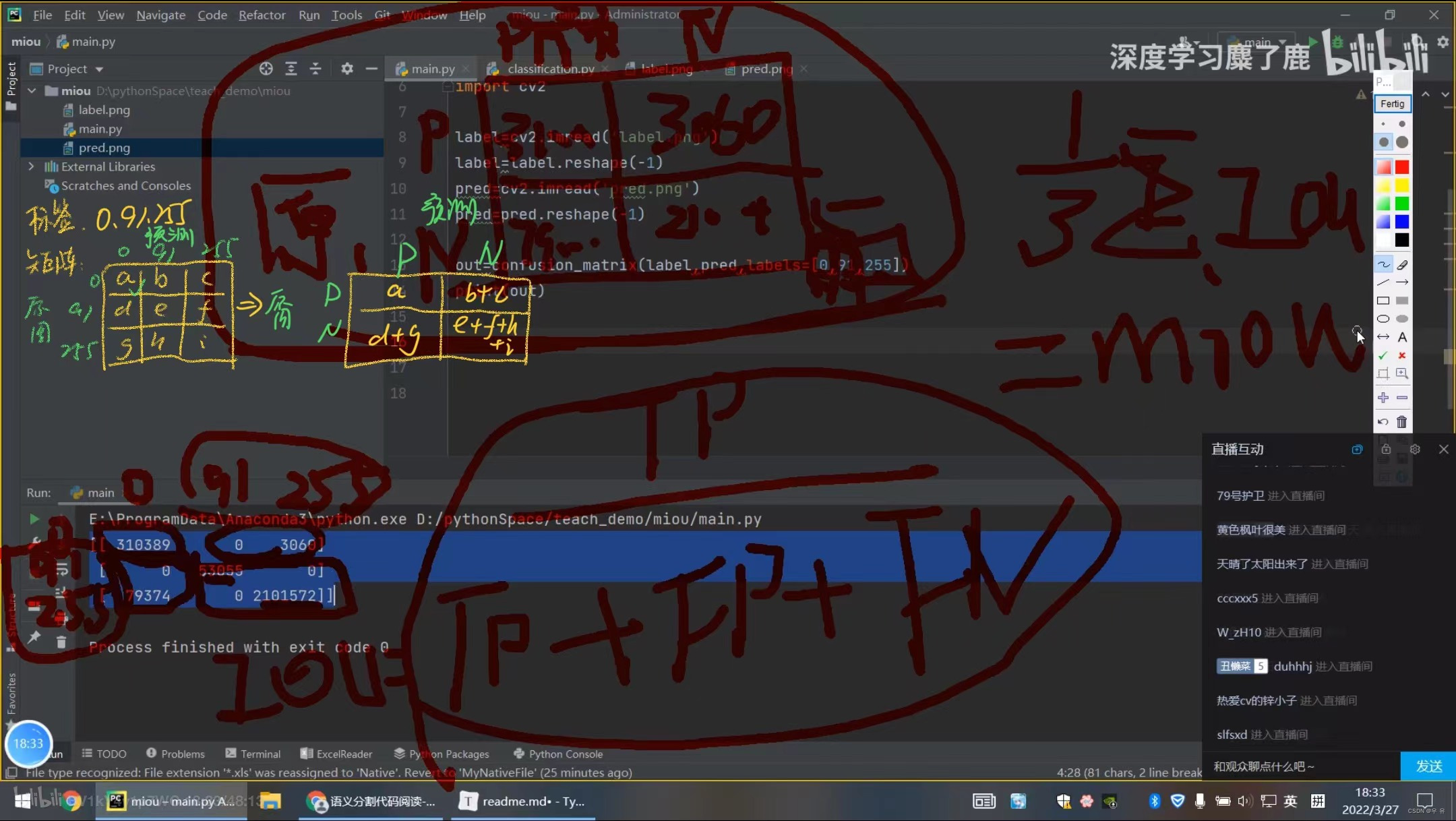
迪哥
【读后感】
前两个视频都是讲了UNet、UNet++、UNet+++
代码讲了UNet++,并用打断点的方式带着一起看整个过程的torch.size[batch,c,h,w]变化
第三个视频更加详细
【个人记录】
UNet分割实战 (视频一)
下采样卷积步长为2,上采样插值;特征融合;-拼接
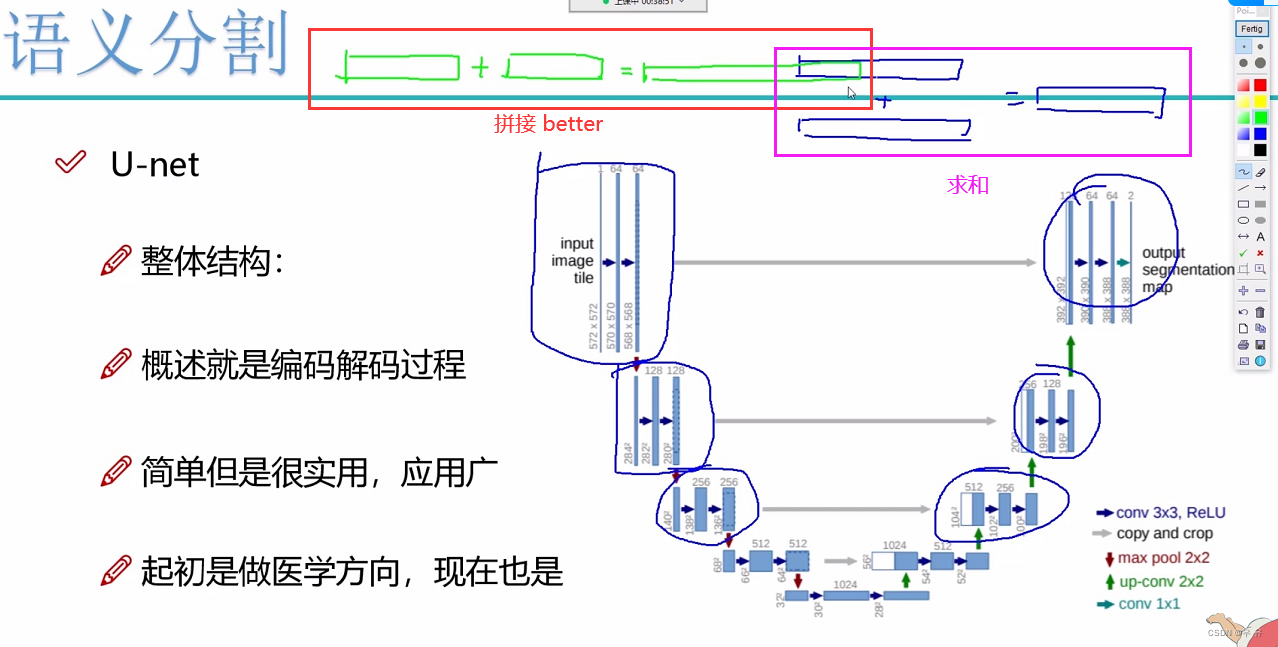
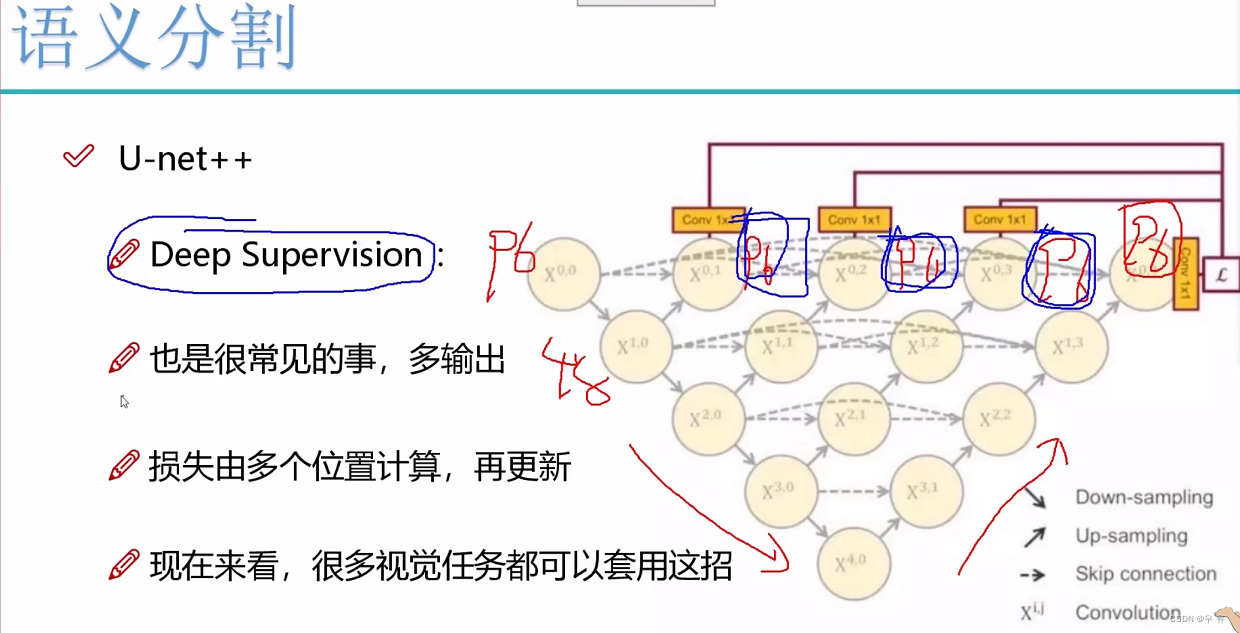
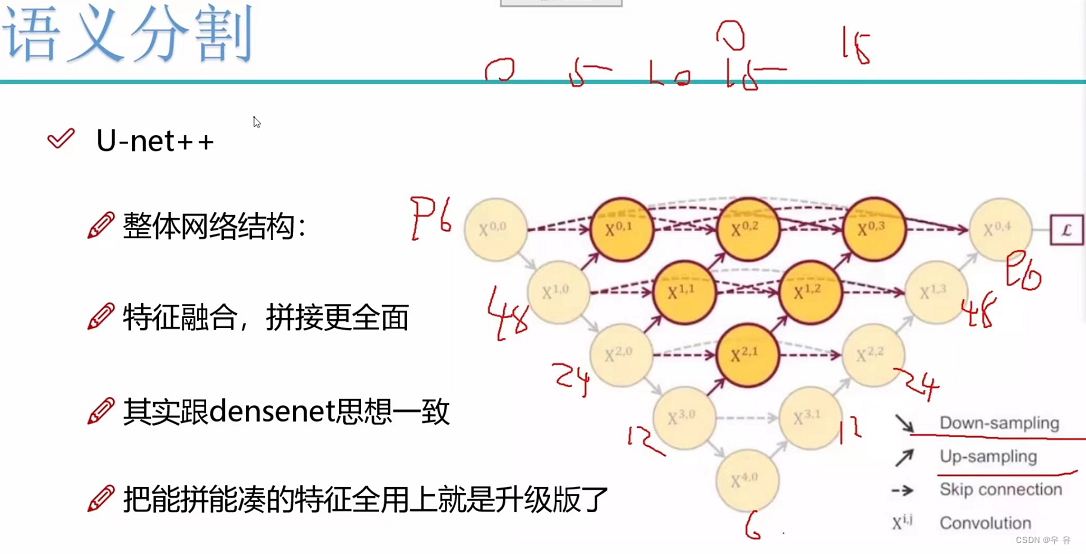
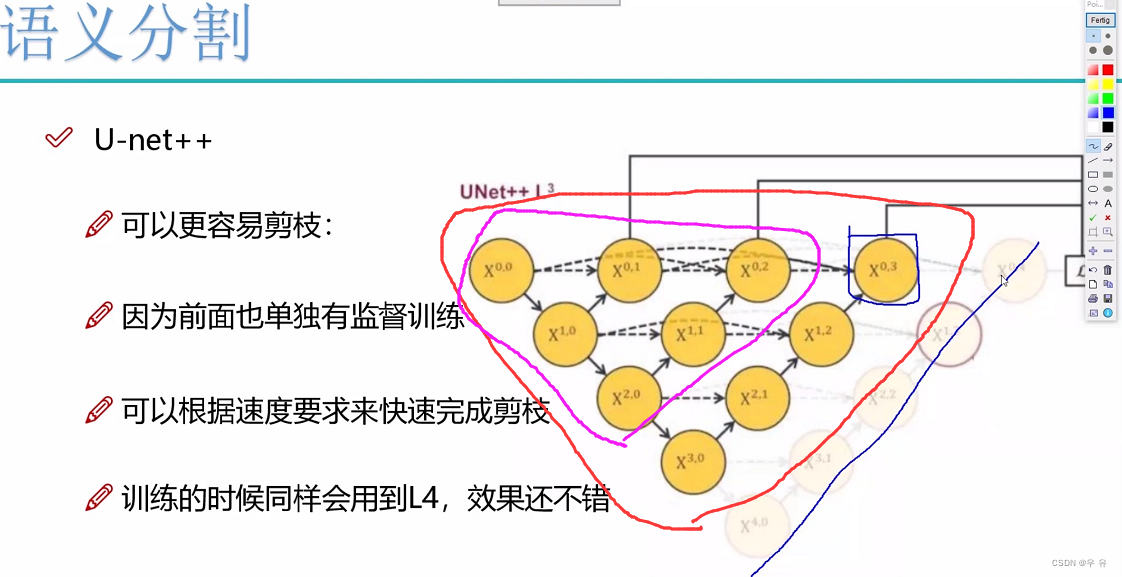
同一层的分辨率一致,是不是可以每一个都拉出来λ-loss,每一个都很好那最终是不是也最好=>剪枝
数据预处理process_dsb2018:读入每张图的所有标签图 并汇总到一张标签图;
train:
数据增强:对于分割图片来说比较容易,但是对于点检测/坐标等 容易在构建标签的时候出错。
拿来主义之数据&标签一起做好数据增强的albumentation工具包来啦!(train.py里260行左右)
val/test需要数据增强吗:train需要,其他就不用了。
数据增强:
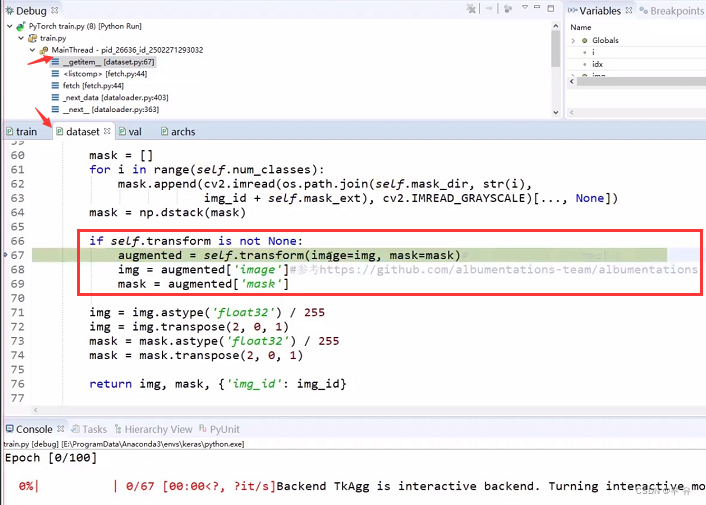
P7:打断点一般在dataset文件里getitem(用于构建batch),就可以找到如何构建数据。以该程序为例:首先通过opencv读入img、然后mask,再transform[augmented-2key=image+mask]、归一化、因为opencv与pytorch的图像维度存在不一致问题所以需要transpose转换,循环batch次。
train.py:先设置path,然后train/val_loader,设置相关参数;log日志打印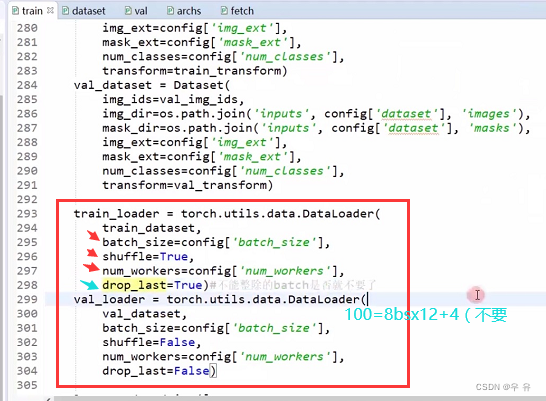
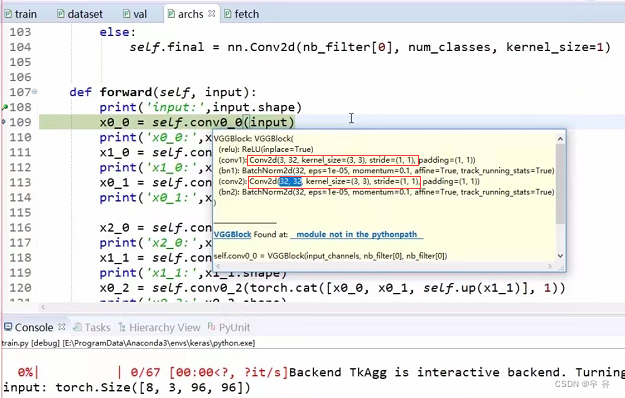
网络架构archs:在forward网络入口处打断点走流程(先不看class),注意debug过程中的数据维度,forward一键三连啊哈哈哈conv/bn/relu,这里VGGBlock相当于做了两次卷积,stride=1不做下采样
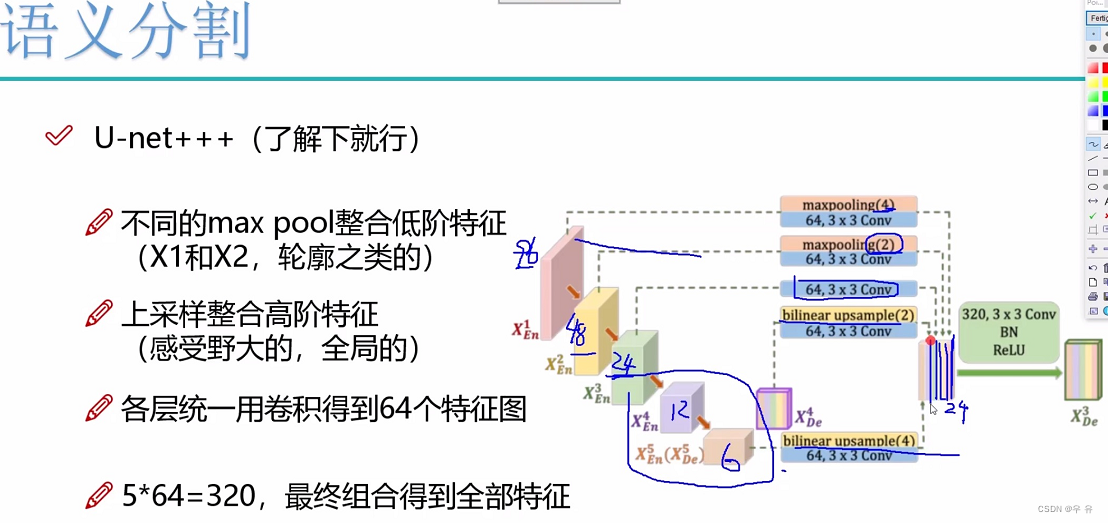
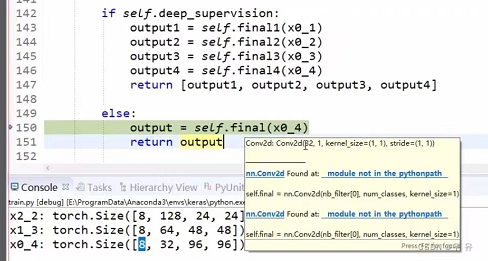
torch.size([一批8batchsize,3dim,96h,96w])[P8详细展示UNET++的演示过程]↓(conv参数设置截图放在自己推算的后面)
//【x0_0、x1_0、x0_1】
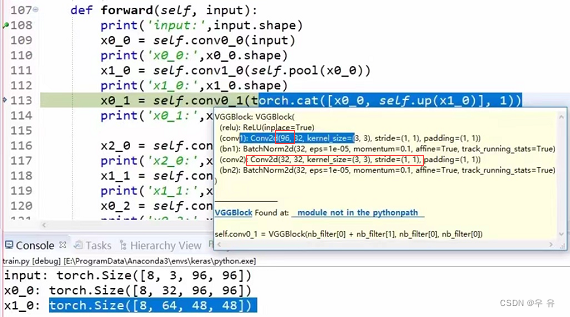
def forward(self,input):
print('input',input.shape)//[8,3,96,96]
x0_0 = self.conv0_0(input)
//kernel_size=3,input=3,output=32,stride=1
print('x0_0',x0_0.shape)//[8,32,96,96]
x1_0 = self.conv1_0(self.pool(x0_0))
//pool:kernel_size=2,stride=2 => [8,32,48,48]
//conv:kernel_size=3,input=32,output=64,stride=1
print('x1_0',x1_0.shape)//[8,64,48,48]
x0_1 = self.conv0_1(torch.cat([x0_0,self.up(x1_0)],1))
//x1_0Up:factor=2 => [8,64,96,96]
//cat:kernel_size=3,input=32+64=96,output=32,stride=1 => [8,32,96,96]
print('x0_1',x0_1.shape)//[8,32,96,96]

x0_0与x0_1一致
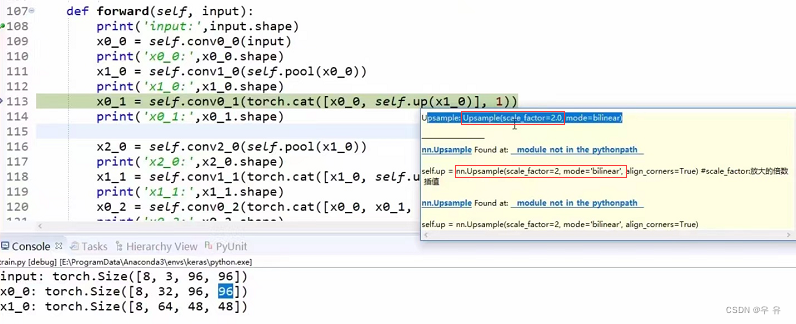
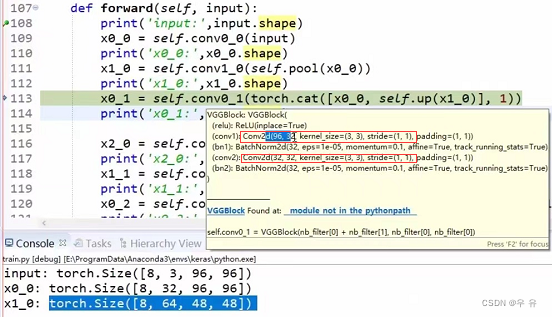
接下来是x0_2,需要注意它的输入来自于多个部分
//【x0_2=x0_0、x1_1、x0_1】
//x0_0、x1_1←x2_0|x1_0、x0_1←x1_0
x2_0 = self.conv2_0(self.pool(x1_0))
//x1_0:[8,32,48,48]
//pool:kernel_size=2,stride=2 => [8,32,48,48]
//conv:kernel_size=3,input=64,output=128,stride=1
print('x2_0',x2_0.shape)//[8,128,24,24]
x1_1 = self.conv1_1(torch.cat([x1_0,self.up(x2_0)],1))
//x2_0up:factor=2 => [8,128,48,48]
//cat:kernel_size=3,input=,output=64,stride=1 => [8,32,48,48]
print('x1_1',x1_1.shape)//[8,64,48,48]
x0_2 = self.conv0_2(torch.cat([x0_0,x0_1,self.up(x1_1)],1))
print('x0_2',x0_2.shape)//[8,32,96,96]
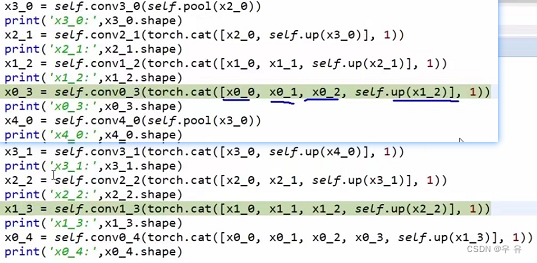
这里的ifelse是是否加入多层损失函数





UNet分割(2022-3) (视频二)
图像分割:逐像素点做分类
IoU(intersection over Union,交并比)
MIOU就是计算所有类别的平均值,一般当做分割任务的评估指标。接近于1√
卷积的目的是提取特征
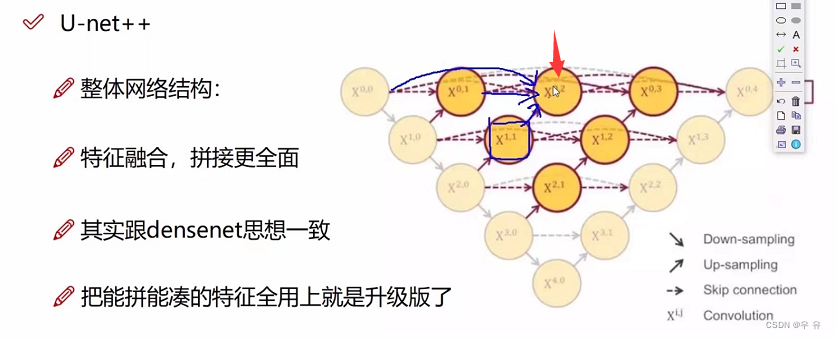
拼接的目的是让网络既有浅层特征又有深层特征,因为拼接跨度有点大,所以UNet++,且损失由多个位置计算,再更新(每一步都监督,且容易剪枝)。
对maxpooling的理解
UNet分割详解(视频三/)
【框架结构】
基于U-Net的新生儿脑组织图像分割:对UNet和transformer介绍通俗易懂,适合入门
UNet:

U-Net原理分析与代码解读
Upsampling 上采样常用的方式有两种:1.FCN 中介绍的反卷积;2. 插值。这里介绍文中使用的插值方式。在插值实现方式中,bilinear 双线性插值的综合表现较好也较为常见 。双线性插值的计算过程没有需要学习的参数,实际就是套公式。
CNN 网络要想获得好效果,skip-connection 基本必不可少。Unet 中这一关键步骤融合了底层信息的位置信息与深层特征的语义信息:torch.cat([low_layer_features, deep_layer_features], dim=1)需要注意的是,FCN 中深层信息与浅层信息融合是通过对应像素相加的方式,而 Unet 是通过拼接的方式。
那么这两者有什么区别呢,其实 在 ResNet 与 DenseNet 中也有一样的区别,Resnet 使用了对应值相加,DenseNet 使用了拼接。个人理解在相加的方式下,feature map 的维度没有变化,但每个维度都包含了更多特征,对于普通的分类任务这种不需要从 feature map 复原到原始分辨率的任务来说,这是一个高效的选择;而拼接则保留了更多的维度/位置 信息,这使得后面的 layer 可以在浅层特征与深层特征自由选择,这对语义分割任务来说更有优势。
评论区答疑:
总结的很好。Unet的一个最突出的contribution便是它的skip connection操作,很好地解决了由于下采样操作所丢失掉的细节损失(比如边界信息,这对于语义分割这种dense 预测型任务来说是至关重要的),从而帮助网络更好的完成精确的定位。相对于add操作,concat操作虽然增加了计算量,但是却能保留更多的空间信息,然后利用卷积层去进行一个特征的提取,通过这种利用学习的方式来融合adjcent-level feature显然会比直接将两者add来的更加有效。同样地道理,上采样一般采用反卷积会比直接双线性插值来的效果要好,当然如果模型处于过拟合的状态下应用反卷积就会起得适得其反的作用。Unet的分割精度很大程度上也取决于Backbone的选择,剩下的就是选择一些合适的数据增强和以及合理的后处理方式。
【U-Net】Pytorch实现_陈嘿萌的博客-CSDN博客
版权归原作者 우 유 所有, 如有侵权,请联系我们删除。