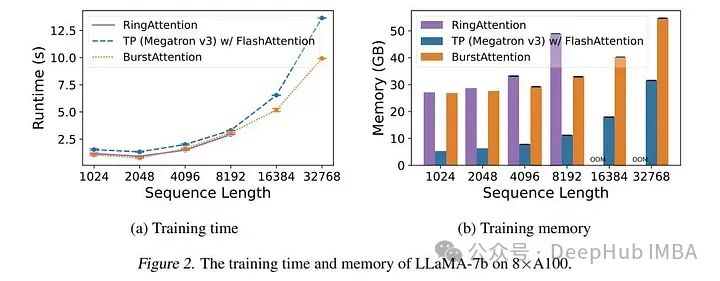
BurstAttention:可对非常长的序列进行高效的分布式注意力计算
而最新的研究BurstAttention可以将2者结合,作为RingAttention和FlashAttention之间的桥梁。
【深度学习:大模型微调】如何微调SAM
Segment Anything 模型 (SAM) 是由 Meta AI 开发的细分模型。它被认为是计算机视觉的第一个基础模型。SAM在包含数百万张图像和数十亿个掩码的庞大数据语料库上进行了训练,使其非常强大。顾名思义,SAM 能够为各种图像生成准确的分割掩码。SAM 的设计允许它考虑人类提示,使其
毕业设计:基于深度学习的人流量检测系统 人工智能
毕业设计:基于深度学习的人流量检测系统旨在解决传统方法存在的效率低下和准确性不稳定等问题。该系统在人流量检测方面取得了显著成果,具有较高的准确率和实时性。还详细介绍了数据集的自制过程和数据扩充技术,为计算机毕业设计提供了一个创新的研究方向。该课题结合了深度学习和计算机视觉技术,为毕业生提供了一个有意
毕业设计:基于机器学习的工地员工安全着装识别系统 目标检测
毕业设计:基于机器学习的工地员工安全着装识别系统通过采用先进的深度学习算法,系统能够自动识别工地员工是否佩戴了必要的安全装备。该系统综合考虑了工地员工的图像特征和相关安全装备的模式,通过构建合适的特征向量和训练数据集,实现了高效准确的安全着装识别。对于计算机专业、软件工程专业、人工智能专业、大数据专
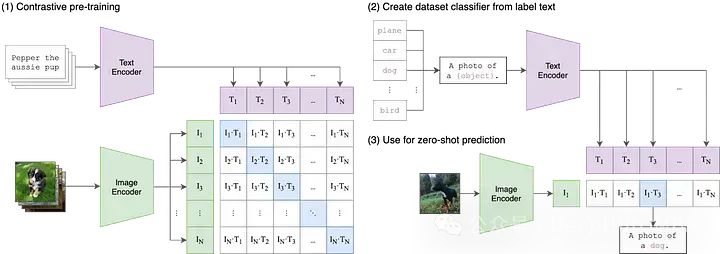
文生图的基石CLIP模型的发展综述
Open AI在2021年1月份发布的DALL-E和CLIP,这两个都属于结合图像和文本的多模态模型,其中DALL-E是基于文本来生成模型的模型,而CLIP是用文本作为监督信号来训练可迁移的视觉模型。
AI:150-基于深度学习的医学数据挖掘与病症关联发现
AI:150-基于深度学习的医学数据挖掘与病症关联发现本文介绍了基于深度学习的医学数据挖掘与病症关联发现。随着医疗信息技术的发展,医学数据的积累已经成为一种常态,但利用这些数据挖掘潜在的病症关联是一项具有挑战性的任务。传统的数据挖掘方法需要大量的人力和时间,并且往往只能发现表面上的相关性。随着深度学
第八章:AI大模型的安全与伦理 8.4 法规遵从
1.背景介绍随着人工智能(AI)技术的快速发展,大型AI模型已经成为了许多应用领域的基石。然而,这些模型在处理敏感数据和影响人类生活的关键决策时,也面临着严峻的安全和伦理挑战。为了确保AI技术的可靠性、安全性和道德性,我们需要关注其法规遵从性。本章将探讨AI大模型在法规遵从的关键方面,包括隐私保护、
谁将主导未来AI市场?Claude3、Gemini、Sora与GPT-4的技术比拼
1.(实操演练)最新超强模型Claude3使用讲解2.OpenAI新模型-GPT-5介绍3.(实操演练)谷歌新模型-Gemini使用讲解4.Meta新模型-LLama35.(实操演练)阿里巴巴-通义千问6.(实操演练)科大讯飞-星火认知7.(实操演练)百度-文心一言8.(实操演练)MoonshotA
毕业设计:基于深度学习的人脸识别考勤签到系统 人工智能 python CNN
毕业设计-基于深度学习的人脸识别考勤签到系统的计算机毕业设计。传统的考勤签到系统存在易被冒用、漏识等问题,而基于深度学习的人脸识别技术提供了一种高效、准确且非侵入性的解决方案。本设计旨在开发一个利用深度学习算法进行人脸特征提取和匹配的考勤签到系统,提高签到准确性、增强安全性、提升工作效率。这个课题不
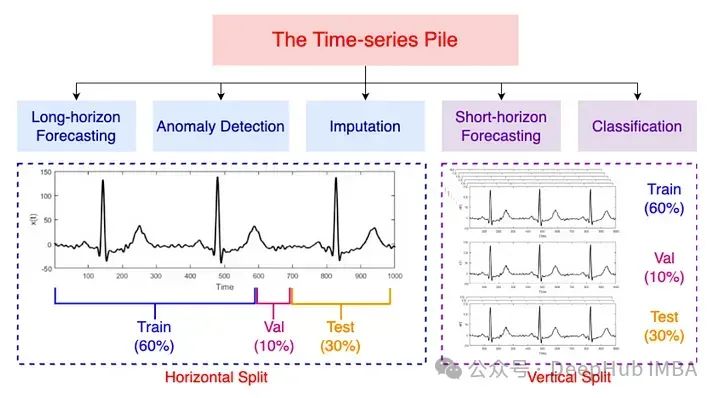
Moment:又一个开源的时间序列基础模型
根据作者的介绍,MOMENT则是第一个开源,大型预训练时间序列模型家族。
【好书推荐2】AI提示工程实战:从零开始利用提示工程学习应用大语言模型
随着大语言模型的快速发展,语言AI已经进入了新的阶段。这种新型的语言AI模型具有强大的自然语言处理能力,能够理解和生成人类语言,从而在许多领域中都有广泛的应用前景。大语言模型的出现将深刻影响人类的生产和生活方式。本书将介绍提示工程的基本概念和实践,旨在帮助读者了解如何构建高质量的提示内容,以便更高效
开源模型应用落地-qwen2模型小试-入门篇(六)
Qwen1.5系列模型的新特性及使用方式
李沐+AutoDL深度学习环境配置
李沐老师课程,在AutoDL服务器配置深度学习环境。
机器人操作——diffusion policy(2023)
机器人操作领域发论文的热点又来了。扩散模型大概率很难和强化学习结合,因为强化学习需要网络足够小从而在每次更新的很短时间内收敛,不过基于扩散模型的动力学模型可以试试。
【语义分割】ST_Unet论文 逐步代码解读
【语义分割】ST_Unet论文 逐步代码解读
开源模型应用落地-业务优化篇(五)
通过多种技术整合,为降本增效赋能,让公司对你眼前一亮。本篇开始进行关键词提取及Redis加速。
AI:149-法律电子邮件图像中的欺诈检测与敲诈勒索追踪—深度学习技术
AI:149-法律电子邮件图像中的欺诈检测与敲诈勒索追踪—深度学习技术在当今数字化的时代,电子邮件已经成为商务和法律交流的主要方式之一。然而,随着电子邮件使用的增加,欺诈和敲诈勒索的风险也在不断增加。面对这一挑战,人工智能技术为法律领域带来了新的解决方案。本文将介绍如何利用人工智能技术,特别是深度学
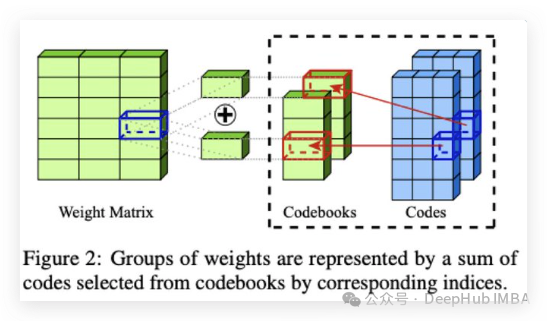
在16G的GPU上微调Mixtral-8x7B
在本文中,我将展示如何仅使用16 GB的GPU RAM对使用AQLM进行量化的Mixtral-8x7B进行微调。
2023计算机(AI)领域相关期刊的SCI分区
就在昨天(12月27日)2023年中科院分区表公布,本文总结了有关计算机领域(尤其是AI(机器学习,CV,NLP,数据挖掘等))的一些期刊的SCI分区,供大家参考学习。
2024年3月的计算机视觉论文推荐
我们今天来总结一下2024年3月上半月份发表的最重要的论文,无论您是研究人员、从业者还是爱好者,本文都将提供有关计算机视觉中最先进的技术和工具重要信息。



