详解AI Agent系列|(1)AI Agent到底是什么
从high-level来简明概括地介绍一下AI Agent
进阶课5——人工智能数据分类
数据类型是指数据在计算机中的存储方式,根据数据的不同特征和表示方式,可以将数据分为不同的类型。在IT领域中,随着数字化信息技术的应用不断扩大,数据的种类和格式也越来越多。从人机交互数据类型的视角来看,人工智能数据主要分为文本数据、语音数据、图像数据和视频数据等几大类别。
colab上利用conda管理环境
colab上的环境管理

如何开始定制你自己的大型语言模型
2023年的大型语言模型领域经历了许多快速的发展和创新,发展出了更大的模型规模并且获得了更好的性能,那么我们普通用户是否可以定制我们需要的大型语言模型呢?
毕业设计:基于深度学习的健身动作(引体向上)识别计数系统 人工智能
毕业设计:基于深度学习的健身动作(引体向上)识别计数系统利用深度学习技术和计算机视觉方法,实现了对健身者进行引体向上动作的实时识别和计数。通过深入研究动作识别的图像特征提取、卷积神经网络模型构建等关键技术,我们的系统能够在不同的环境和条件下,准确识别和计数健身者的引体向上动作。对于计算机专业、软件工
YOLOv8改进 | 图像去雾 | 利用图像去雾网络AOD-PONO-Net网络增改进图像物体检测
官方论文地址:官方论文地址点击即可跳转官方代码地址:官方代码地址点击即可跳转这篇论文提出了一种名为全能去雾网络(AOD-Net)的图像去雾模型,该模型是基于重新制定的大气散射模型并利用卷积神经网络(CNN)构建的。与大多数先前的模型不同,AOD-Net不是分别估计传输矩阵和大气光,而是直接通过一个轻
【图像配准】CVPRW21 - 深度特征匹配 DFM
论文解读《DFM: A Performance Baseline for Deep Feature Matching》,用于图像配准/图像匹配的深度特征匹配方法DFM。模型无需训练,利用预训练模型,采用DNNS和HRA策略即可达到SOTA性能。
奶奶看了都会,AI翻唱,RVC声音模型训练制作教学,附 派蒙模型
AI翻唱,AI模型训练
深度学习与机器学习:互补共进,共绘人工智能宏伟蓝图
深度学习和机器学习是人工智能领域的两个重要分支,它们各自具有独特的优势,并在多个层面紧密相连。深度学习通过深度神经网络结构,展现出强大的数据处理能力,能够自动学习数据的特征提取,适用于语音识别、自然语言处理、计算机视觉等领域。而传统机器学习则更加注重模型的简单性和可解释性,依赖于人工设计的特征和算法
最新!最全!深度学习特征提取主干网络总结(内含基本单元结构代码)
接下来为每个模型提供基本结构的代码,并对其亮点进行简要描述。
【深度学习】BERT变体—RoBERTa
RoBERTa是的BERT的常用变体,出自Facebook的。来自Facebook的作者根据BERT训练不足的缺点提出了更有效的预训练方法,并发布了具有更强鲁棒性的BERT:RoBERTa。RoBERTa通过以下四个方面改变来改善BERT的预训练:在MLM任务中使用动态掩码而不是静态掩码;移除NSP
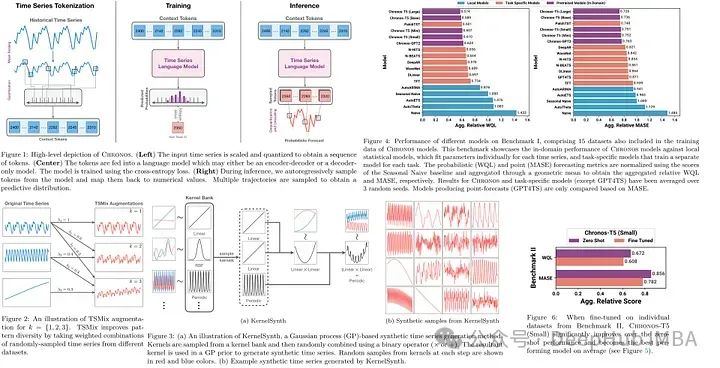
Chronos: 将时间序列作为一种语言进行学习
这是一篇非常有意思的论文,它将时间序列分块并作为语言模型中的一个token来进行学习,并且得到了很好的效果。
秒懂AI-深度学习五大模型:RNN、CNN、Transformer、BERT、GPT简介
BERT是一种基于Transformer的预训练语言模型,它的最大创新之处在于引入了双向Transformer编码器,这使得模型可以同时考虑输入序列的前后上下文信息。GPT也是一种基于Transformer的预训练语言模型,它的最大创新之处在于使用了单向Transformer编码器,这使得模型可以更
YOLOv8改进 | 主干篇 | 轻量级的低照度图像增强网络IAT改进YOLOv8暗光检测(全网独家首发)
本文给大家带来的改进机制是轻量级的变换器模型:Illumination Adaptive Transformer (IAT),用于图像增强和曝光校正。其基本原理是通过分解图像信号处理器(ISP)管道到局部和全局图像组件,从而恢复在低光或过/欠曝光条件下的正常光照sRGB图像。具体来说,IAT使用注意
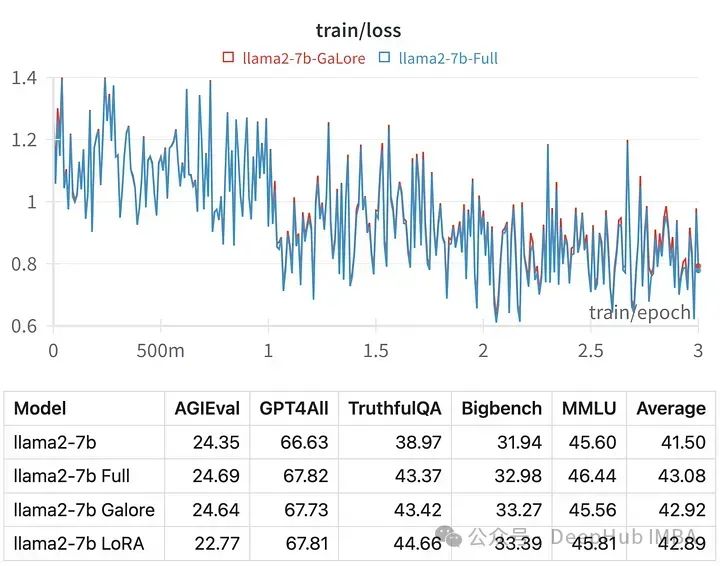
使用GaLore在本地GPU进行高效的LLM调优
,GaLore可以让我们在具有24 GB VRAM的消费级GPU上微调7B模型。结果模型的性能与全参数微调相当,并且似乎优于LoRA。
【深度学习】【部署】Flask快速部署Pytorch模型【入门】
【深度学习】【部署】Flask快速部署深度学习模型【入门】
AllenAI 开源了关于大模型的所有细节!数据、代码、参数、训练过程,完全复现
这些计划的发布将有助于研究目前尚不甚了解的模型方面,例如预训练数据与模型能力之间的关系、设计和超参数选择的影响,以及各种优化方法对模型训练的影响。OLMo模型的训练过程也不例外。需要注意的是,这些估算值应被视为下限,因为它们没有包括其他排放源,如硬件和数据中心基础设施的制造、运输和处置过程中的固有排
爆肝3W多字,100多张配图!深度学习从小白到精通一篇博文帮你打开人工智能的大门建议收藏不容错过!!!
在介绍深度学习之前,我们先看下这幅图:人工智能>机器学习>深度学习。深度学习是机器学习的⼀个子集,也就是说深度学习是实现机器学习的一种方法。与机器学习算法的主要区别如下图所示:传统机器学习算术依赖人工设计特征,并进行特征提取,而深度学习方法不需要人工,而是依赖算法自动提取特征,这也是深度学习被看做黑



