
红衣大叔讲AI:Sora技术原理大揭秘
前沿:Sora是一个OpenAI技术大集成模型,融合了ChatGPT、DALL E3,以及把视频融合到Transformer中,生成一个一的视频帧,利用矢量来表示,最后把这个矢量送到Transformer中训练视觉大模型。
Sora生成图像能力:Sora是一个文生视频模型,但同样具备生成图像能力,这个创新属于业内第一家。Sora可以生成不同大小,分辨率高达2048x2048的图像例如,充满活力的珊瑚礁,有色彩缤纷的鱼类和海洋生物。

苹果树下有一只可爱的小老虎,哑光绘画数字风格,细节华丽

Sora****技术原理以及“视频帧片”
Sora****技术原理:
衣服破了一个洞怎么办?通常的方法是打一个补丁,然后缝缝补补又穿3年。同理,OpenAI从大语言模型ChatGPT领悟到了灵感:大模型可以生成各种细化文本内容,主要得益于精准的数据标记,统一了文本代码、数学和各种自然语言的不同模式。既然大模型有文本标记,那Sora当然也可以有“视频帧片”。
OpenAI****发现,视频帧片是一种高度可扩展且有效的表示形式,可用于在不同类型的视频和图像上训练生成模型。
在较高维度上,OpenAI首先将视频压缩到低维潜在空间中,然后将其分解为时空补丁,从而将视频转化为补丁。
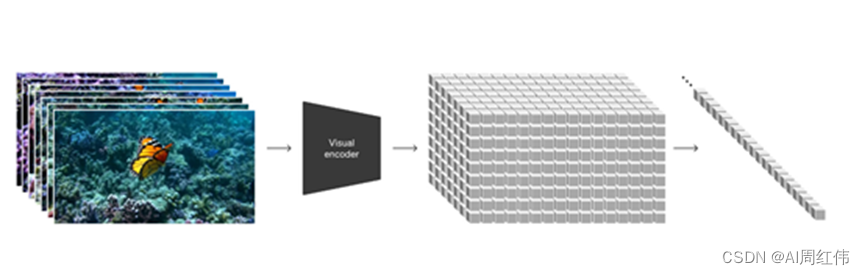
视频压缩网络:OpenAI训练了一个降低视觉数据维度的网络。该网络将原始视频作为输入,并输出在时间和空间上压缩的潜在表示。Sora 在这个压缩的潜在空间中接受训练,并随后生成视频。同时还训练了相应的解码器模型,将生成的潜伏映射回像素空间。

时空潜伏斑块:给定一个压缩输入视频,OpenAI提取了一系列时空补丁作为转换标记。基于补丁的表示法,使 Sora 能够在不同分辨率、持续时间和长宽比的视频和图像上进行训练。在推理时,可以通过在适当大小的网格中排列随机初始化的补丁,来控制生成视频的大小。
模型架构:Sora是一个扩散模型在给定输入噪声补丁,被训练来预测原始的“干净”补丁。此外,Sora 和ChatGPT一样使用了Transformer 架构,在语言建模、计算机视觉以及图像生成等方面非常优秀。
改善构图:OpenAI发现,在原始长宽比的视频上进行训练,可以极大改善构图和取景,并将 Sora 与所有训练视频裁剪成正方形的模型版本进行了比较,取景效果获得了极大的改善。

右图为Sora生成全景视频。
精准文本语义理解:训练视频模型需要大量,带有相应字幕的视频。OpenAI将DALL·E 3的重新字幕技术引入到了Sora。首先训练一个高度描述性的字幕模型,然后用它为训练集中的所有视频制作文本字幕。
OpenAI表示,在高度描述性的视频字幕上进行训练,可提高文本的保真度以及视频的整体质量。与 DALL-E 3 一样,OpenAI也通过 GPT 将简短的用户提示转化为较长的详细字幕,并发送给视频模型。这使得 Sora 能够精准地还原用户的文本提示,生成高质量的长视频。
从这份技术报告来看,Sora更像是OpenAI的技术大集合,使用到了很多ChatGPT、DALL E3以及之前积累的技术沉淀,也是Sora能呈现出那么多超强视频技术的原因。

总之:Sora是一个OpenAI技术大集成模型,融合了ChatGPT、DALL E3,以及把视频融合到Transformer中,生成一个一的视频帧,利用矢量来表示,最后把这个矢量送到Transformer中训练视觉大模型。
版权归原作者 AI周红伟 所有, 如有侵权,请联系我们删除。