
深度学习作为当前计算机科学领域最具前沿性的研究方向之一,其应用范围涵盖了从计算机视觉到自然语言处理等多个领域。本文将探讨深度学习在游戏领域的一个具体应用:构建一个能够自主学习并完成超级马里奥兄弟的游戏的智能系统。
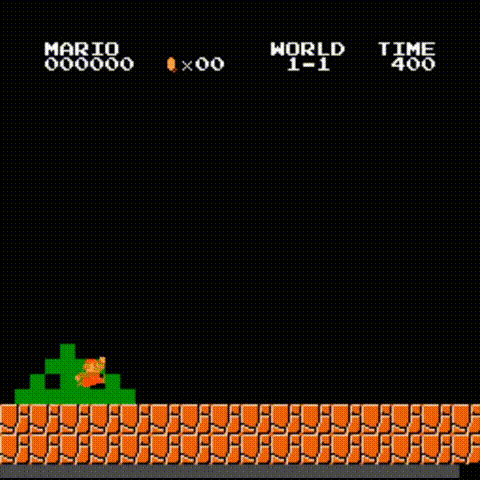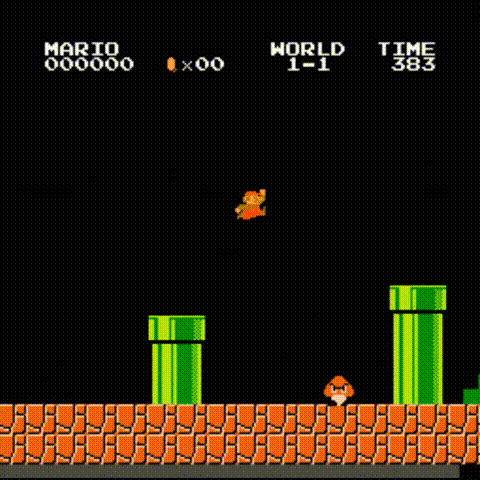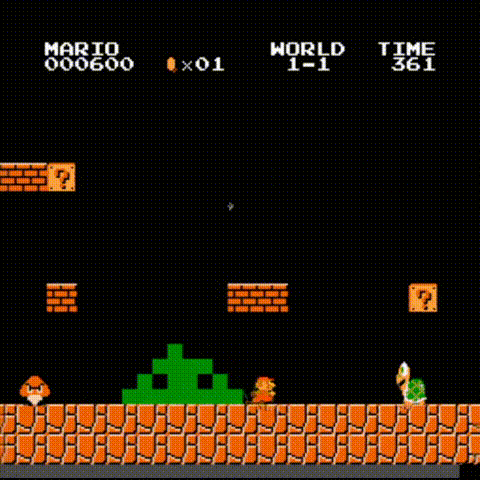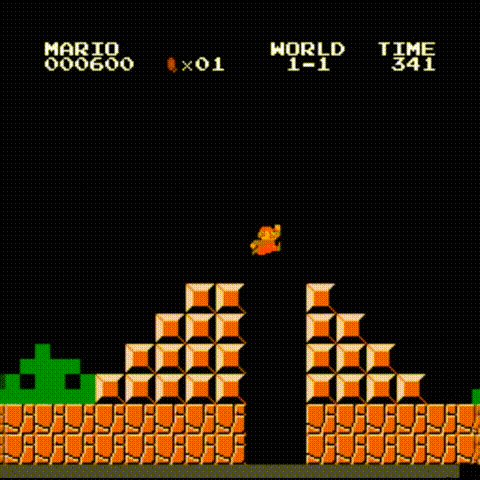
强化学习基础
强化学习是机器学习的一个重要分支,研究智能体如何通过与环境的交互学习来优化其行为策略。类似于人类的学习过程,智能体在虚拟环境中通过不断尝试各种行动并获取反馈,逐步建立最优决策模型。
在强化学习框架中,做出决策的程序被称为智能体(agent),其所处的交互空间被定义为环境(environment)。智能体通过执行动作(actions)与环境进行交互,每个动作都会获得相应的奖励信号,用以评估该动作在特定状态下的效果——这里的状态指的是环境在特定时刻的完整配置信息。
以上图gif为例,作为智能体的人类尝试与环境中的洒水装置进行交互,采取了一个动作:将其对准自己。执行该动作后,智能体接收到了明显的负向奖励信号(从干燥到湿润的状态转换),从而学会了避免重复该动作。
从系统层面来看,智能体通过动作与环境交互,获取奖励信号和新的状态信息,这个新状态又将作为下一个动作决策的依据。
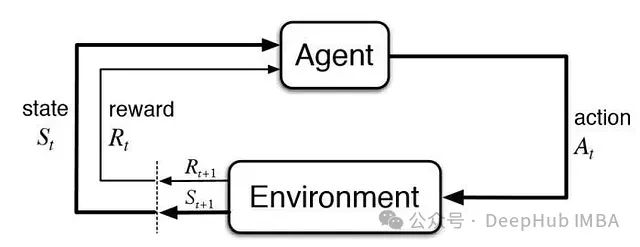
在超级马里奥Bros游戏环境中,智能体是控制马里奥行为的程序系统,环境则包含了游戏世界的所有元素:砖块、管道、敌人等。环境状态即为游戏当前帧的完整信息,这些信息构成了智能体进行决策分析的基础数据。
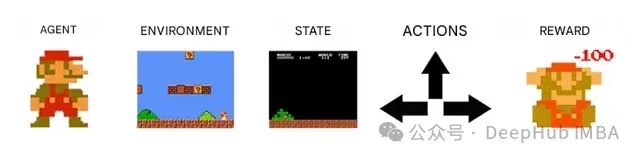
我们的智能体可以执行的动作集合对应着马里奥的控制指令:跳跃、移动、静止等。在游戏的每一帧中,智能体都会根据其行为获得相应的奖励信号:失败时获得负向奖励,而向着目标推进则获得正向奖励。
通过上述理论框架的建立,我们可以深入理解智能程序如何在特定环境中通过学习来形成最优决策策略。
2013年,人工智能领域的领先企业DeepMind推出了突破性的深度Q网络(DQN)技术,该网络在多款雅达利游戏中实现了超越人类水平的表现。这一创新极大地推进了强化学习的发展,使其能够应对更为复杂的问题,包括对游戏画面的实时分析与理解。
我们的目标是构建一个能够自主掌握超级马里奥Bros第一关的深度神经网络系统。
超级马里奥Bros环境构建
在开发针对超级马里奥Bros的智能系统之前,我们需要首先构建一个合适的仿真环境。Gym-Super-Mario-Bros提供了一个专门的强化学习环境框架,支持智能体在超级马里奥Bros系列前两代游戏的各个关卡中进行训练。
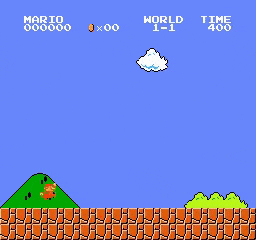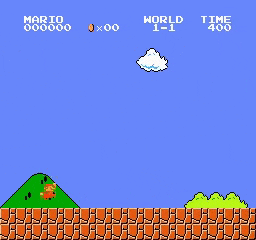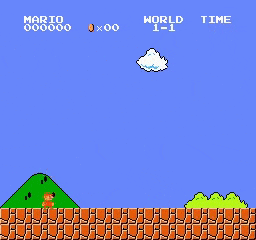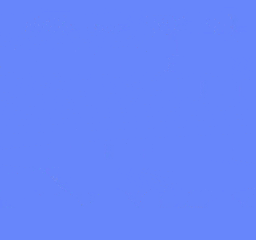
在环境中,系统接收当前游戏画面作为状态输入,并需要基于该状态信息选择相应的动作,如跳跃、左右移动或保持静止等。
Gym-Super-Mario-Bros框架提供了根据不同研究目标选择游戏关卡和视觉特征的灵活性。我们选用SuperMarioBros-1-1-v1作为实验环境,这是第一关卡的简化版本,通过降低背景复杂度来优化图像识别效率。
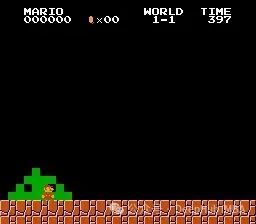
为了深入理解该环境的特性,我们首先实现一个基于随机策略的基准智能体,用于测试第一关卡的基本交互机制。
DQN架构设计
从本质上讲,神经网络是一类通过样本学习来建立输入输出映射关系的函数系统。在图像识别等任务中,网络通过学习样本建立分类模型。
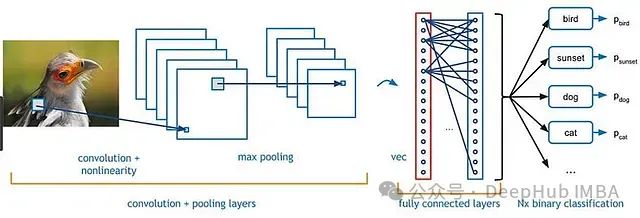
网络的输入为游戏当前状态的图像数据,输出为各可能动作的价值评估(Q值),其中最高价值对应的动作被认为是当前状态下的最优决策。
Q值定义为在特定状态下执行某动作所能获得的预期累积奖励,即在该状态采取特定动作后所获得的总体奖励的期望值。
从实用角度看,它量化了在某个状态下选择特定动作的价值。
据此我们设计的神经网络架构如下图所示:
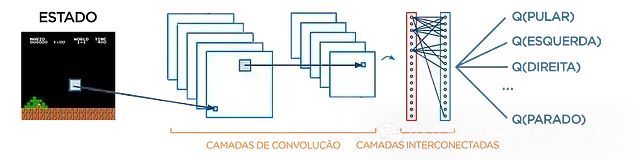
系统架构的具体实现如下:
- 输入层接收游戏的最近四帧画面。这种帧堆叠技术(Frame Stacking)的引入使网络能够捕获时序信息
- 这些图像数据经由网络的卷积层处理,用于提取和识别图像中的关键特征模式
- 卷积层的特征输出传递给全连接层,用于计算每个可能动作的Q值
- 系统基于计算得出的Q值选择最优动作,即选择Q值最高的动作执行
在训练初期,DQN在图像特征提取和动作价值评估方面的表现都相对欠佳。但通过持续的训练优化,网络逐步提升其状态理解能力和动作评估准确度,最终能够在不同状态下做出合理的决策。
虽然网络实现的具体细节较为复杂,感兴趣的读者可以参考源代码,相关技术细节也将在文末附录中详细说明。
在理解了神经网络的基本架构后,我们现在关注其与环境的交互实现。
智能体-环境交互机制
在此前介绍的随机策略智能体的基础上,我们将构建一个具有学习能力的智能体系统。
首先实现**state_reshape(state)**函数用于状态数据的预处理和标准化,然后构建智能体训练函数:
# 状态数据预处理和标准化函数
defstate_reshape(state):
state=np.swapaxes(state, -3, -1)
state=np.swapaxes(state, -1, -2)
returnstate/255.
# 智能体训练主函数
deftrain(agent, env, total_timesteps):
# 环境初始化
state=env.reset()
# 状态预处理
state=state_reshape(state)
timestep=0
# 训练循环
whiletimestep<total_timesteps:
# 动作选择
actions=agent.act(state)
# 执行动作并获取新状态信息
next_state, rewards, dones, _=env.step(actions)
# 新状态预处理
next_state=state_reshape(next_state)
# 经验数据存储
agent.remember(state, actions, rewards, next_state, dones)
# 网络训练
agent.train()
timestep+=1
# 状态更新
state=next_state
# epsilon重置,维持探索性
iftimestep%50000==0:
agent.epsilon=0.1
相比随机策略实现,本系统有以下关键改进:
- 采用智能体的***.act(state)***方法进行动作选择,替代了随机选择机制
- 引入***.remember(state, actions, rewards, next_state, dones)***方法实现经验回放机制,存储交互数据用于后续训练
- 通过***.train()***方法实现持续的在线学习,不断优化网络性能
- 引入epsilon参数控制探索-利用平衡,每50,000步重置以维持适度的探索性> 各方法的详细技术说明请参见文末附录
系统实现完成后,只需执行训练程序即可启动学习过程。经过数小时的训练,我们使用DQN获得的最佳表现如文章开头所示,并且在引入更复杂的强化学习算法后,系统性能得到进一步提升:
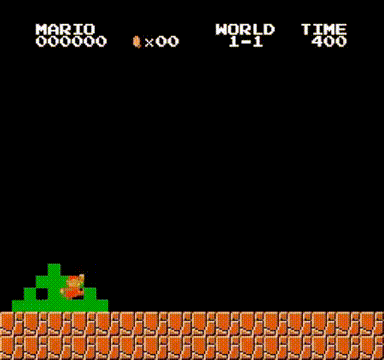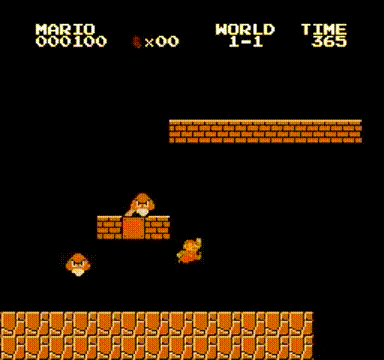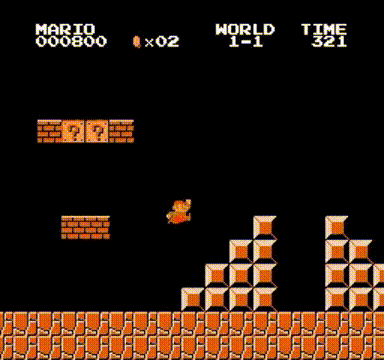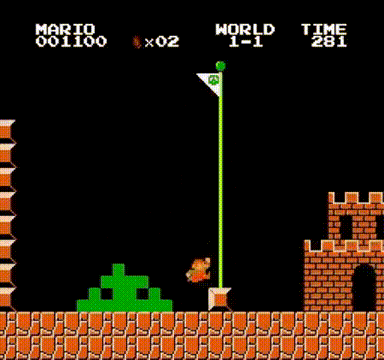
总结
本研究展示了强化学习在游戏人工智能领域的应用潜力。通过具体项目实践,我们期望能够推动该领域的研究发展,并激发更多研究者的兴趣。
如需深入了解本项目的技术细节,请参考下方附录和完整的源代码。
以下是对文中部分技术细节的补充说明:
神经网络架构
本项目采用基于PyTorch实现的神经网络,包含三个卷积层和两个全连接层。
importtorch.nnasnn
importtorch.nn.functionalasF
classNetwork(nn.Module):
def__init__(self, in_dim: int, out_dim: int):
super(Network, self).__init__()
self.out_dim=out_dim
self.convs=nn.Sequential(nn.Conv2d(4, 32, 8, stride=4, padding=0), nn.ReLU(),
nn.Conv2d(32, 64, 4, stride=2, padding=0), nn.ReLU(),
nn.Conv2d(64, 64, 3, stride=1, padding=0), nn.ReLU())
self.advantage1=nn.Linear(7*7*64, 512)
self.advantage2=nn.Linear(512, out_dim)
self.value1=nn.Linear(7*7*64, 512)
self.value2=nn.Linear(512, 1)
defforward(self, state):
conv=self.convs(state)
flat=conv.reshape(-1, 7*7*64)
adv_hid=F.relu(self.advantage1(flat))
val_hid=F.relu(self.value1(flat))
advantages=self.advantage2(adv_hid)
values=self.value2(val_hid)
q=values+ (advantages-advantages.mean())
这里采用了Dueling Deep Q-Network架构,将网络输出分为状态价值(V)估计和动作优势(Advantage)估计两个分支。这种架构设计通过将Q值分解为两个独立的组件,提高了网络的学习效率和性能。
动作选择策略
为了平衡探索与利用,系统采用ε-贪心策略进行动作选择。初始阶段较高的探索率确保对动作空间的充分探索,随训练进行逐步降低探索率,但保留最小探索概率以维持适应性。
经验存储机制
每次交互后的经验数据(当前状态、动作、奖励、下一状态、终止标志)被存储到经验回放缓冲区,用于后续批量训练。
完整代码见
https://github.com/Berbardo/MarioRL
作者:Larissa Barcellos