
在深度学习模型部署和优化领域,计算效率与资源消耗的平衡一直是一个核心挑战。PyTorch团队针对这一问题推出了创新性的技术方案——在其原生低精度计算库TorchAO中引入低位运算符支持。这一技术突破不仅实现了1至8位精度的嵌入层权重量化,还支持了具有8位动态量化激活的线性运算符,为解决资源受限环境下的深度学习计算难题提供了有效解决方案。
这项技术创新的重要性体现在其全面的框架支持上。通过精心的架构设计,新的低位运算符实现了与PyTorch生态系统各个关键组件的无缝集成,包括即时执行模式(eager execution)、torch.compile编译优化框架、预先推理技术(AOTI)以及面向边缘计算的ExecuTorch。这种全方位的技术覆盖确保了开发者能够在各种应用场景中充分利用低位计算带来的性能优势。
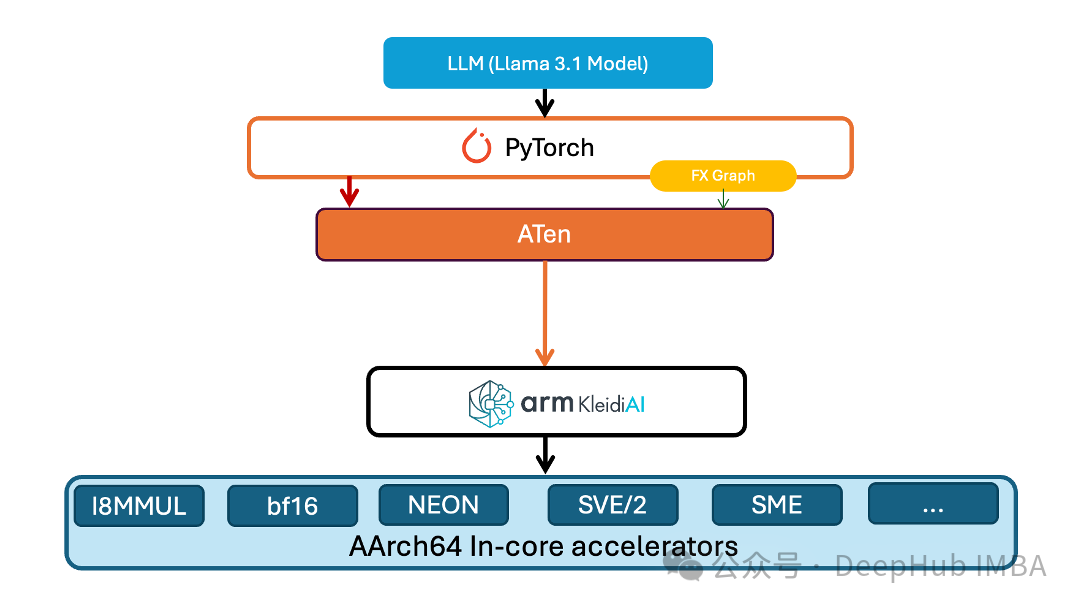
通用低位计算内核的技术创新
在深度学习硬件加速领域,低位计算面临的最大挑战之一是缺乏直接的硬件支持。PyTorch团队通过创新的架构设计巧妙地解决了这个问题。他们采用了高度模块化的设计理念,将低位值解包操作与核心GEMV(通用矩阵-向量乘法)计算逻辑分离,这种解耦不仅提高了代码的可维护性,更为不同精度配置下的计算优化提供了灵活的实现路径。
在具体的技术实现中,团队开发的8位GEMV内核展现了卓越的架构设计。该内核充分利用了Arm架构的NeonDot指令集的并行计算能力,通过实现强制内联的解包例程,高效完成从低位值到int8的精确转换过程。这种模块化设计的优势在于,它实现了位打包逻辑的高度复用,使得同一套核心逻辑可以同时服务于线性计算和嵌入层计算,显著降低了开发成本和维护难度。
PyTorch与ExecuTorch的深度技术融合
为了实现更广泛的技术生态覆盖,开发团队在设计新一代计算内核时特别注重了框架间的兼容性。通过采用原始指针作为数据交互接口,而非直接依赖PyTorch的张量系统,成功实现了PyTorch和ExecuTorch两大框架间的无缝对接。这种设计选择的深远意义在于,它不仅确保了代码的跨平台兼容性,还为未来可能的框架扩展预留了充足的技术空间。
在性能优化层面,团队引入的"torchao::parallel_1d"并行计算机制展现了出色的适应性。这一机制能够根据编译时的具体配置,智能地在ATen的parallel_for和ExecuTorch的线程池之间进行动态切换,不仅提供了卓越的计算性能,还确保了在不同部署环境下的最优性能表现。
可替换内核架构
在系统架构设计层面,PyTorch团队采用了高度抽象的多层次架构。高层多线程线性运算符的设计完全独立于底层的单线程内核实现,这种解耦通过精心设计的"ukernel config"接口得以实现。该接口通过函数指针机制定义了一系列核心操作,包括激活数据的预处理、权重数据的管理以及内核计算的执行等关键环节。这种架构设计的优势在于,它为第三方硬件厂商和算法开发者提供了标准化的接口,使他们能够根据特定硬件平台的特性开发优化的计算内核,从而充分发挥硬件性能潜力。
深入性能分析与优化策略
为了全面评估新运算符的实际性能表现,开发团队在M1 MacBook Pro(32GB RAM)平台上进行了系统的性能测试。测试以Llama3.1 8B这一大规模语言模型为基准,对不同位宽配置下的性能特性进行了深入分析。测试结果揭示了位宽选择对性能的显著影响:
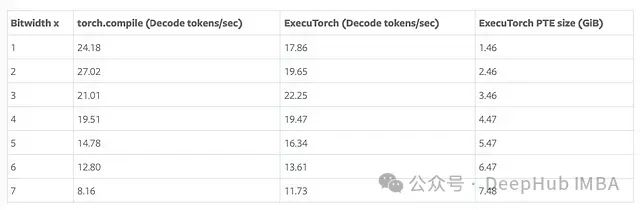
在测试配置中,团队采用了精心设计的量化策略。嵌入层采用组大小为32的细粒度量化方案,而线性层则结合了基于token的8位动态量化激活技术和组大小为256的权重组量化方法。这种多层次的量化策略在保持模型精度的同时,实现了计算效率的显著提升。测试结果不仅验证了低位计算的性能优势,更为不同应用场景下的量化策略选择提供了重要的实践指导。
技术发展前沿与未来展望
PyTorch在低位运算符领域的创新为深度学习框架优化开辟了多个重要的研究方向:
- 通用低位GEMM内核研究: 将现有的技术创新扩展到GEMM(通用矩阵-矩阵乘法)计算领域,这对于提升模型训练阶段的计算效率具有重要意义。
- 智能化运行时内核调度: 开发基于硬件指令集架构(ISA)、数据特征和计算模式的自适应内核选择机制,实现计算资源的最优配置。
- 异构计算平台支持: 针对x86等主流CPU架构开发专门的低位计算内核,扩大技术方案的适用范围。
- 生态系统整合: 推进与KleidiAI等专业加速库的深度集成,构建更加开放和高效的深度学习计算生态。
PyTorch团队在高性能低位运算符领域的技术突破,标志着Arm平台深度学习计算优化进入了新阶段。通过融合模块化设计思想、跨平台代码共享和可替换内核架构等创新技术,PyTorch为下一代高效率深度学习计算框架奠定了坚实的技术基础。这些技术创新不仅推动了资源受限场景下深度学习应用的发展,更为人工智能技术在边缘计算等新兴领域的广泛应用提供了关键支持。随着深度学习技术的持续发展,这些创新性的技术方案必将在推动人工智能产业化进程中发挥越来越重要的作用。
官方新闻地址