CVPR2022 多目标跟踪(MOT)汇总
CVPR2022 MOT文章汇总
模型部署入门教程(三):PyTorch 转 ONNX 详解
OpenMMLab:模型部署系列教程(一):模型部署简介OpenMMLab:模型部署系列教程(二):解决模型部署中的难题知道你们在催更,这不,模型部署入门系列教程来啦~在前二期的教程中,我们带领大家成功部署了第一个模型,解决了一些在模型部署中可能会碰到的困难。今天开始,我们将由浅入深地介绍 ONNX
windows下CUDA的卸载以及安装
一、缘由对于CUDA新手来说,安装问题里面有很多需要注意的细节,很多自定义的选项,如果漏选就会出现一些莫名奇妙的问题。为此,会经常出现卸载CUDA,再安装CUDA的问题,下面总结。二、卸载前的准备(1)卸载工具:①windows自带的控制面板,用来卸载主程序②腾讯电脑管家等类似杀毒软件,用来清除卸载
周志华《机器学习》第三章课后习题
目录3.1 试析在什么情形下式(3.2) 中不必考虑偏置项 b.3.2、试证明,对于参数w,对率回归的目标函数(3.18)是非凸的,但其对数似然函数(3.27)是凸的. 3.3、编程实现对率回归,并给出西瓜数据集3.0α上的结果.3.4 选择两个 UCI 数据集,比较 10 折交叉验证法和留一法所估
学习率设置
本篇主要学习神经网络超参数学习率的设置,包括人工调整和策略调整学习率。在模型优化中,常用到的几种学习率衰减方法有:分段常数衰减、多项式衰减、指数衰减、自然指数衰减、余弦衰减、线性余弦衰减、噪声线性余弦衰减。......
安装Pytorch-gpu版本(第一次安装 或 已经安装Pytorch-cpu版本后)
由于已经安装了cpu版本了,如果再在该环境下安装gpu版本会造成环境污染.因此,再安装gpu版本时,需要再新建一个虚拟环境才能安装成功。然后去官网下载所适配的版本。 安装完cuda和cudnn后,开始安装pytorch的gpu版本。1.安装cude首先查看windows电脑之前是否成功安装了CUDA
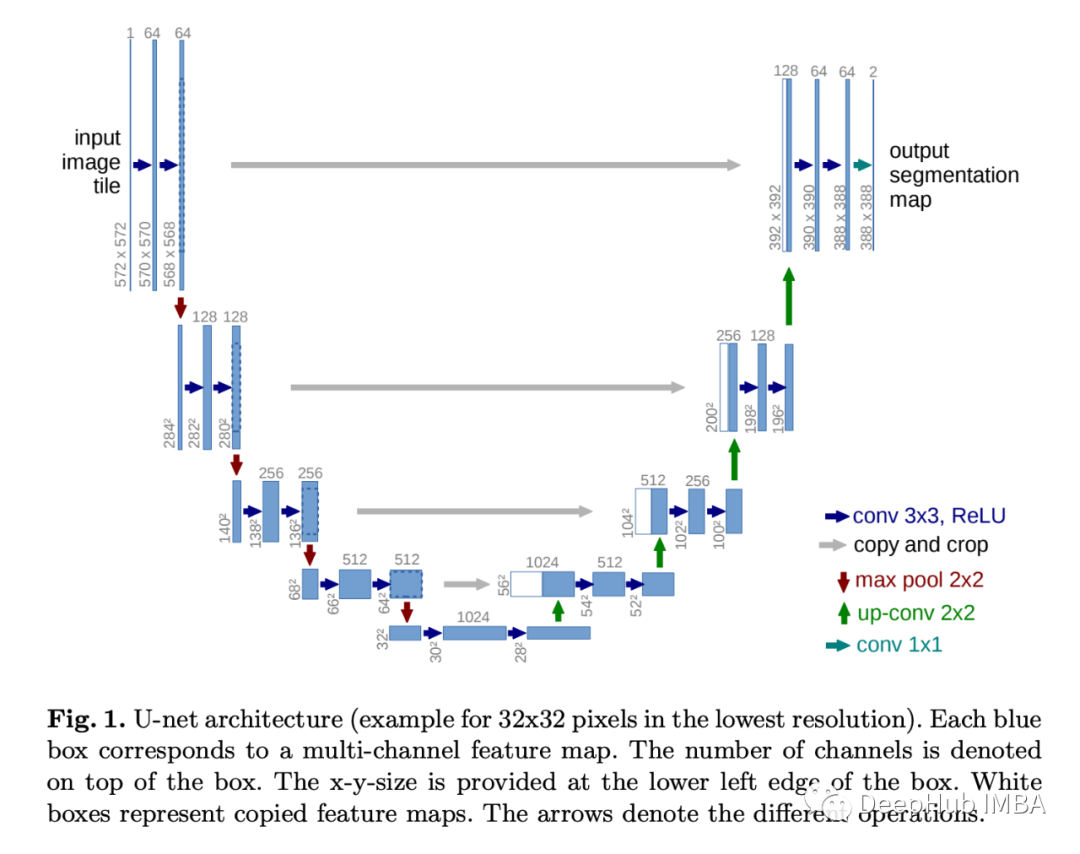
U-Net在2022年相关研究的论文推荐
UNet 可以算是 FCN 的一种变体,是最常用、最简单的一种分割模型,简单、高效、易懂、容易构建,且可以从小数据集中训练。2015 年,UNet 在论文 U-Net: Convolutional Networks for Biomedical Image Segmentation 中被提出 。
TensorFlow安装并在Pycharm搭建环境
TensorFlow手把手安装教学,还有Pycharm环境配置。含有丰富图片,适合新手教程!
Deformable DETR源码解读
Deformable DETR源码解读
pytorch-lightning安装
一般pytorch-lightning 需要torch版本≥1.8.0。在安装pytorch-lightning时一定注意自己的torch是pip安装还是conda安装,两者要保持一致,不然会导致安装pytorch-lightning时会直接卸载掉你的torch,安装cpu版本的torch。http
Cuda与GPU显卡驱动版本一览
cuda版本是??gpu 驱动? 两者怎么对应
详解:yolov5中推理时置信度,设置的conf和iou_thres具体含义
详解:yolov5中推理时置信度,设置的conf和iou_thres具体含义
YOLOv5训练自己的数据集详解
入门小菜鸟,希望像做笔记记录自己学的东西,也希望能帮助到同样入门的人,更希望大佬们帮忙纠错啦~侵权立删。一、YOLOv5源码下载网址指路:GitHub - ultralytics/yolov5: YOLOv5 ???? in PyTorch > ONNX > CoreML > TF
CoCo数据集下载
文章目录1.介绍2.下载2.1 官网2.2 百度网盘2.3 下载到linux服务器1.介绍MS COCO的全称是Microsoft Common Objects in Context,起源于微软2014年的Microsoft COCO数据集COCO is a large-scale object d
联邦学习(FL)+差分隐私(DP)
联邦学习+差分隐私(FL+DP)
论文阅读笔记:ShuffleNet
背景由于深度学习模型结构越来越复杂,参数量也越来越大,需要大量的算力去做模型的训练和推理。然而随着移动设备的普及,将深度学习模型部署于计算资源有限基于ARM的移动设备成为了研究的热点。ShuffleNet[1]是一种专门为计算资源有限的设备设计的神经网络结构,主要采用了pointwise group
特征融合的分类和方法
1、特征融合的定义特征融合方法是模式识别领域的一种重要的方法,计算机视觉领域的图像识别问题作为一种特殊的模式分类问题,仍然存在很多的挑战,特征融合方法能够综合利用多种图像特征,实现多特征的优势互补,获得更加鲁棒和准确性的识别结果。2、特征融合的分类按照融合和预测的先后顺序,分类为早融合和晚融合(Ea
基于时序模式注意力机制(TPA)的长短时记忆(LSTM)网络TPA-LSTM的多变量输入风电功率预测
0 前言1、TPA理论注意力机制(Attention mechanism)通常结合神经网络模型用于序列预测,使得模型更加关注历史信息与当前输入信息的相关部分。时序模式注意力机制(Temporal Pattern Attention mechanism, TPA)由 Shun-Yao Shih 等提出
【ROS】VSCODE + ROS 配置方法(保姆级教程,总结了多篇)
vscode + ros 配置方法(正在更新……)最近开始学习ROS,但是官方给的教程都是在终端命令行下实现的,如果想要编写代码我使用的是vscode进行编写。首先vscode它不是一个IDE,vscode只提供编辑的环境而不提供编译的环境,如果想要用vscode来集成开发环境,就必须安装必须的编译
解决pytorch中Dataloader读取数据太慢的问题
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档文章目录前言一、造成的原因二、查找不匹配的原因三、解决方法四、使用方法后言前言最近在使用pytorch框架进行模型训练时遇到一个性能问题,即数据读取的速度远远大于GPU训练的速度,导致整个训练流程中有大部分时间都在等待数据发送到GPU,



