
文章目录
本文完整代码下载
`本文的全套代码下载点击此处:https://download.csdn.net/download/weixin_54546190/85539252人名币二分类完整Python代码(包含数据集)
人名币二分类
**
在介绍数据读取机制(DataLoader与Dataset)之前,我们先学习一下人名币二分类实验,有助于后面的理解。
**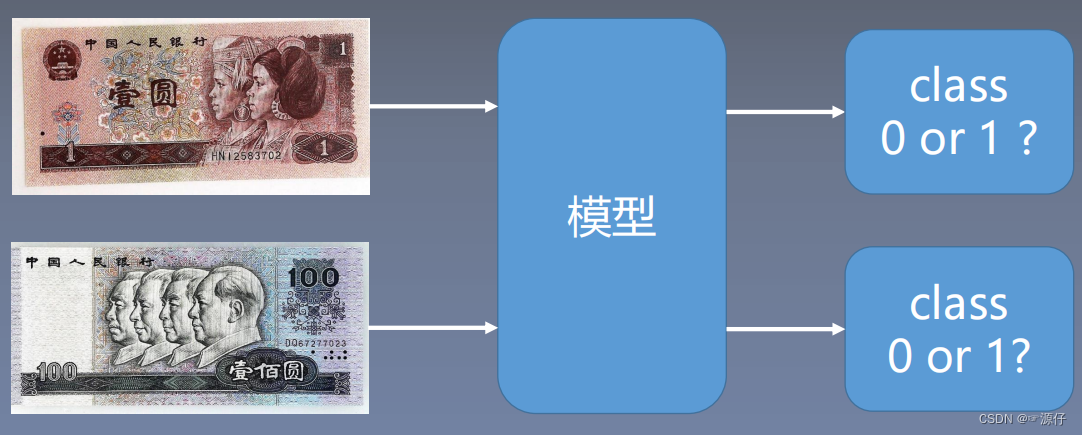
机器学习模型训练步骤
数据处理的过程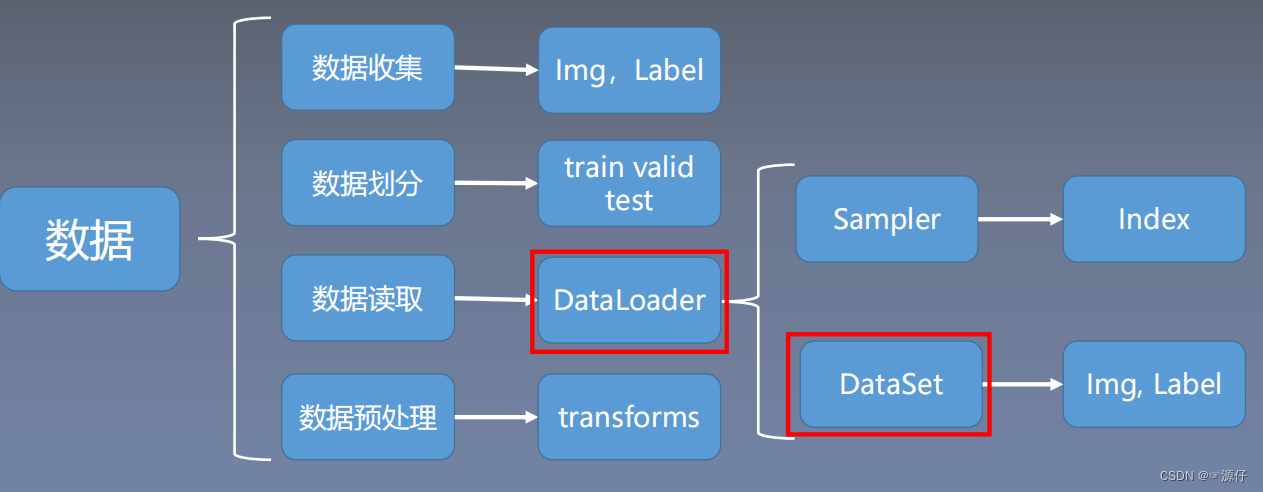
Sampler的作用:生成索引(index)也就是样本的序号。
DataSet的作用:根据索引读取相应的图片和标签。
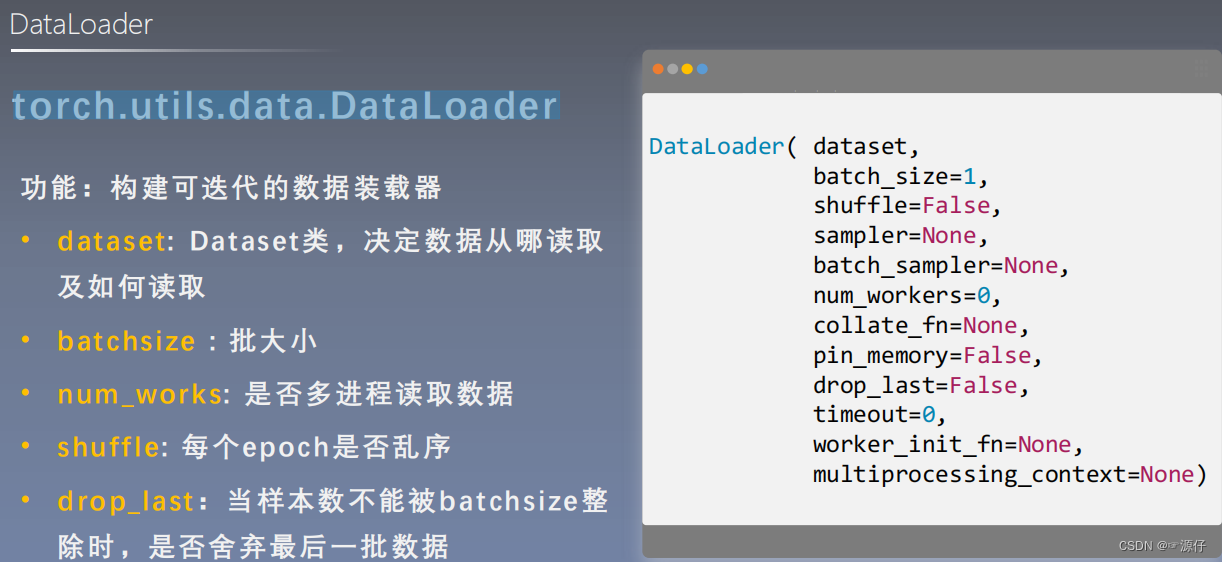
torch.utils.data.DataLoader(迭代数据的作用)
Dataloader构建了一个迭代的数据装载器,训练时每次for循环,每次iteration都会从Dataloader中获取一个batch_size大小的数据进行操作。
Epoch / Iteration / Batchsize之间的关系
Epoch:所有训练样本都已输入到模型中,称为一个EpochIteration:一批样本输入到模型中,称之为一个IterationBatchsize:批大小,决定一个Epoch有多少个Iteration- 例:样本总数:80, Batchsize:8 时
1 Epoch = 10 Iteration
- 例:样本总数:87, Batchsize:8 时
当drop_last = True时:1 Epoch = 10
当drop_last = False时:1 Epoch = 11 Iteration,但是最后一个Iteration只有7个数据。
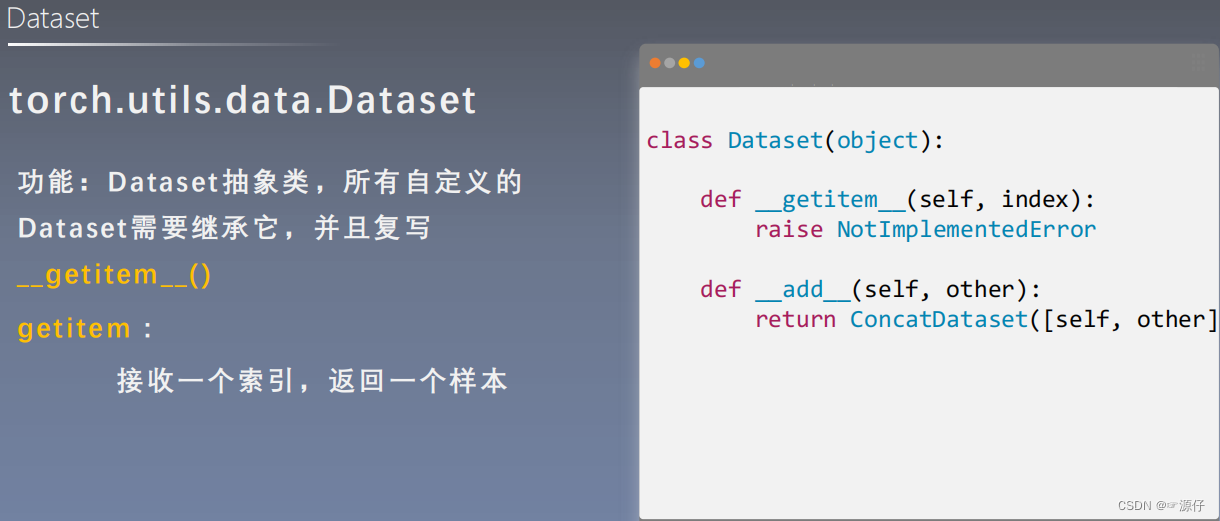
torch.utils.data.Dataset(读取数据的作用)
**
torch.utils.data.Dataset是用来定义数据从哪读取和如何读取的问题。
**
**
Dataset是一个抽象类**:
- 实际使用中需要继承Dataset,并对其__len__()方法和__getitem__(idx)进行重构。前者为返回数据集长度,后者为查询idx所对应的img和其label。
- 在下面的代码中我们会用RMBDataset(data_dir=train_dir, transform=train_transform)继承Dataset,并对其__len__()方法和__getitem__(idx)进行重构。
人民币二分类实验
在人民币二分类之前,我们先了解三个问题,带着这三个问题去学习人名币二分类实验代码。如下图所示:
人名币二分类Code
1、划分数据集Code
**
以训练集0.8,验证集0.1,测试集0.1的比例对总人名币数据集进行划分。通过下述1_split_dataset.py文件运行可得子文件-- -- rmb_split,具体划分之后的文件分布我详细卸载代码下方。
**
# -*- coding: utf-8 -*-"""
# @file name : 1_split_dataset.py
# @date : 2022-06-1 10:08:00
# @brief : 将数据集划分为训练集,验证集,测试集
"""import os
import random
import shutil
BASE_DIR = os.path.dirname(os.path.abspath(__file__))defmakedir(new_dir):ifnot os.path.exists(new_dir):
os.makedirs(new_dir)if __name__ =='__main__':
dataset_dir = os.path.abspath(os.path.join(BASE_DIR,"RMB_data"))
split_dir = os.path.abspath(os.path.join(BASE_DIR,"rmb_split"))
train_dir = os.path.join(split_dir,"train")
valid_dir = os.path.join(split_dir,"valid")
test_dir = os.path.join(split_dir,"test")ifnot os.path.exists(dataset_dir):raise Exception("\n{} 不存在,请下载 02-01-数据-RMB_data.rar 放到\n{} 下,并解压即可".format(
dataset_dir, os.path.dirname(dataset_dir)))
train_pct =0.8
valid_pct =0.1
test_pct =0.1for root, dirs, files in os.walk(dataset_dir):for sub_dir in dirs:
imgs = os.listdir(os.path.join(root, sub_dir))
imgs =list(filter(lambda x: x.endswith('.jpg'), imgs))
random.shuffle(imgs)
img_count =len(imgs)
train_point =int(img_count * train_pct)
valid_point =int(img_count *(train_pct + valid_pct))if img_count ==0:print("{}目录下,无图片,请检查".format(os.path.join(root, sub_dir)))import sys
sys.exit(0)for i inrange(img_count):if i < train_point:
out_dir = os.path.join(train_dir, sub_dir)elif i < valid_point:
out_dir = os.path.join(valid_dir, sub_dir)else:
out_dir = os.path.join(test_dir, sub_dir)
makedir(out_dir)
target_path = os.path.join(out_dir, imgs[i])
src_path = os.path.join(dataset_dir, sub_dir, imgs[i])
shutil.copy(src_path, target_path)print('Class:{}, train:{}, valid:{}, test:{}'.format(sub_dir, train_point, valid_point-train_point,
img_count-valid_point))print("已在 {} 创建划分好的数据\n".format(out_dir))
lesson-06
– – RMB_data
– – 1
– –× × × \times \times \times ×××.jpg– – 100
– –× × × \times \times \times ×××.jpg– – rmb_split
– – test
– – 1
– – 100
– – train
– – 1
– – 100
– – valid
– – 1
– – 100
– – test_data
– – 100
– – 100.jpg
– --tools
– – common_tools.py
– – dcgan.py
– – my_dataset.py
– – unet.py
– --model
– – lenet.py
– – 1_split_dataset.py
– – 2_train_lenet.py
2、训练Code
**
我们首先看一下完整代码和代码训练效果以及结果。
**
"""
# @file name : train_lenet.py
# @author : 源仔
# @date : 2022-06-1 10:08:00
# @brief : 人民币分类模型训练
"""import os
BASE_DIR = os.path.dirname(os.path.abspath(__file__))import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torch.optim as optim
from matplotlib import pyplot as plt
path_lenet = os.path.abspath(os.path.join(BASE_DIR,"model","lenet.py"))
path_tools = os.path.abspath(os.path.join(BASE_DIR,"tools","common_tools.py"))assert os.path.exists(path_lenet),"{}不存在,请将lenet.py文件放到 {}".format(path_lenet, os.path.dirname(path_lenet))assert os.path.exists(path_tools),"{}不存在,请将common_tools.py文件放到 {}".format(path_tools, os.path.dirname(path_tools))import sys
hello_pytorch_DIR = os.path.abspath(os.path.dirname(__file__)+os.path.sep+".."+os.path.sep+"..")
sys.path.append(hello_pytorch_DIR)from model.lenet import LeNet
from tools.my_dataset import RMBDataset
from tools.common_tools import set_seed
set_seed()# 设置随机种子
rmb_label ={"1":0,"100":1}# 参数设置
MAX_EPOCH =10
BATCH_SIZE =16
LR =0.01
log_interval =10
val_interval =1# ============================ step 1/5 数据 ============================# ============================ 读取数据在硬盘中的地址 ============================
split_dir = os.path.abspath(os.path.join(BASE_DIR,"rmb_split"))ifnot os.path.exists(split_dir):raise Exception(r"数据 {} 不存在, 回到lesson-06\1_split_dataset.py生成数据".format(split_dir))
train_dir = os.path.join(split_dir,"train")
valid_dir = os.path.join(split_dir,"valid")# ============================ 这里的均值和方差 ============================
norm_mean =[0.485,0.456,0.406]
norm_std =[0.229,0.224,0.225]# =====================对训练数据和验证数据进行预处理=========================
train_transform = transforms.Compose([
transforms.Resize((32,32)),# 图片的大小缩放到(w,h)=(32,32)
transforms.RandomCrop(32, padding=4),# 随机裁剪
transforms.ToTensor(),# 把图片格式转化为tensor形式
transforms.Normalize(norm_mean, norm_std),# 归一化])
valid_transform = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),])# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)# ============================ step 2/5 模型 ============================
net = LeNet(classes=2)
net.initialize_weights()# ============================ step 3/5 损失函数 ============================
criterion = nn.CrossEntropyLoss()# 选择损失函数# ============================ step 4/5 优化器 ============================
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9)# 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)# 设置学习率下降策略# ============================ step 5/5 训练 ============================
train_curve =list()
valid_curve =list()for epoch inrange(MAX_EPOCH):
loss_mean =0.
correct =0.
total =0.
net.train()for i, data inenumerate(train_loader):# forward
inputs, labels = data
outputs = net(inputs)# backward
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()# update weights
optimizer.step()# 统计分类情况
_, predicted = torch.max(outputs.data,1)
total += labels.size(0)
correct +=(predicted == labels).squeeze().sum().numpy()# 打印训练信息
loss_mean += loss.item()
train_curve.append(loss.item())if(i+1)% log_interval ==0:
loss_mean = loss_mean / log_interval
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, i+1,len(train_loader), loss_mean, correct / total))
loss_mean =0.
scheduler.step()# 更新学习率# validate the modelif(epoch+1)% val_interval ==0:
correct_val =0.
total_val =0.
loss_val =0.
net.eval()with torch.no_grad():for j, data inenumerate(valid_loader):
inputs, labels = data
outputs = net(inputs)
loss = criterion(outputs, labels)
_, predicted = torch.max(outputs.data,1)
total_val += labels.size(0)
correct_val +=(predicted == labels).squeeze().sum().numpy()
loss_val += loss.item()
loss_val_epoch = loss_val /len(valid_loader)
valid_curve.append(loss_val_epoch)print("Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, j+1,len(valid_loader), loss_val_epoch, correct_val / total_val))
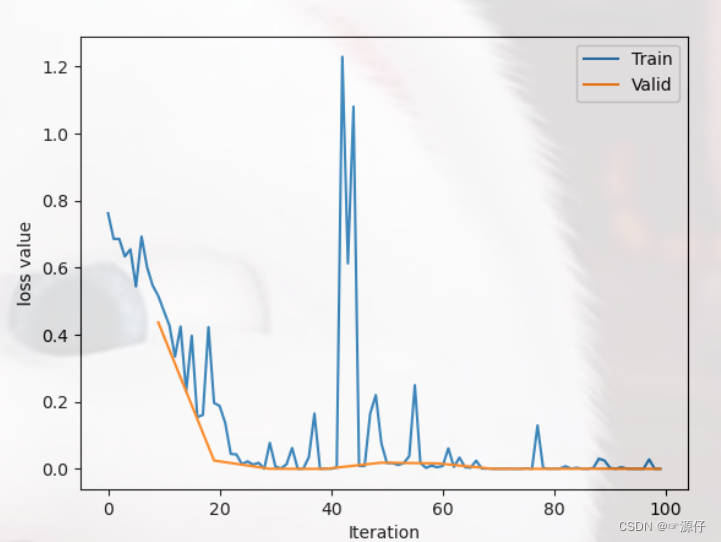
train_x =range(len(train_curve))
train_y = train_curve
train_iters =len(train_loader)
valid_x = np.arange(1,len(valid_curve)+1)* train_iters*val_interval -1# 由于valid中记录的是epochloss,需要对记录点进行转换到iterations
valid_y = valid_curve
plt.plot(train_x, train_y, label='Train')
plt.plot(valid_x, valid_y, label='Valid')
plt.legend(loc='upper right')
plt.ylabel('loss value')
plt.xlabel('Iteration')
plt.show()# ============================ inference ============================
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
test_dir = os.path.join(BASE_DIR,"test_data")
test_data = RMBDataset(data_dir=test_dir, transform=valid_transform)
valid_loader = DataLoader(dataset=test_data, batch_size=1)for i, data inenumerate(valid_loader):# forward
inputs, labels = data
outputs = net(inputs)
_, predicted = torch.max(outputs.data,1)
rmb =1if predicted.numpy()[0]==0else100print("模型获得{}元".format(rmb))
OUT:
Training:Epoch[000/010] Iteration[010/010] Loss:0.6326 Acc:61.25%
Valid: Epoch[000/010] Iteration[002/002] Loss:0.4373 Acc:85.00%
Training:Epoch[001/010] Iteration[010/010] Loss:0.3222 Acc:88.12%
Valid: Epoch[001/010] Iteration[002/002] Loss:0.0250 Acc:100.00%
Training:Epoch[002/010] Iteration[010/010] Loss:0.0559 Acc:98.12%
Valid: Epoch[002/010] Iteration[002/002] Loss:0.0003 Acc:100.00%
Training:Epoch[003/010] Iteration[010/010] Loss:0.0287 Acc:99.38%
Valid: Epoch[003/010] Iteration[002/002] Loss:0.0001 Acc:100.00%
Training:Epoch[004/010] Iteration[010/010] Loss:0.3408 Acc:92.50%
Valid: Epoch[004/010] Iteration[002/002] Loss:0.0186 Acc:100.00%
Training:Epoch[005/010] Iteration[010/010] Loss:0.0386 Acc:98.75%
Valid: Epoch[005/010] Iteration[002/002] Loss:0.0165 Acc:100.00%
Training:Epoch[006/010] Iteration[010/010] Loss:0.0145 Acc:100.00%
Valid: Epoch[006/010] Iteration[002/002] Loss:0.0004 Acc:100.00%
Training:Epoch[007/010] Iteration[010/010] Loss:0.0136 Acc:99.38%
Valid: Epoch[007/010] Iteration[002/002] Loss:0.0002 Acc:100.00%
Training:Epoch[008/010] Iteration[010/010] Loss:0.0072 Acc:100.00%
Valid: Epoch[008/010] Iteration[002/002] Loss:0.0005 Acc:100.00%
Training:Epoch[009/010] Iteration[010/010] Loss:0.0039 Acc:100.00%
Valid: Epoch[009/010] Iteration[002/002] Loss:0.0000 Acc:100.00%
模型获得100元
**
关于模型中输入数据的预处理(如裁剪,旋转,颜色扰动等)、step 2/5 模型 、step 3/5 损失函数、step 4/5 模型、step 5/5 训练四个内容,在后面的博客会陆续更新,一口吃不成胖子,我们要按部就班的去学习,本张只讲step 1/5 训练数据的导入.
**
RMBDataset详解(Dataset读取数据)
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
- data_dir=train_dir:str, 数据集所在路径。
- train_transform:对训练数据进行预处理,代码如下:
**
train_transform: 数据预处理代码如下
**
train_transform = transforms.Compose([
transforms.Resize((32,32)),# 图片的大小缩放到(w,h)=(32,32)
transforms.RandomCrop(32, padding=4),# 随机裁剪
transforms.ToTensor(),# 把图片格式转化为tensor形式
transforms.Normalize(norm_mean, norm_std),# 将数据转换为正太分布,使模型更容易收敛。])
RMBDataset类
我们从
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
开始, 这一句话里面的核心就是
RMBDataset
,这个是我们自己写的一个类,继承了上面的抽象类
Dataset
,并且重写了
__getitem__()
方法, 这个类的目的就是传入数据的路径,和预处理部分(看参数),然后给我们返回数据,下面看它是怎么实现的(Pycharm里面按住Ctrl+B键,或按住Ctrl,然后点击这个RMBDataset位置就进入当前的RMBDataset类中):
classRMBDataset(Dataset):def__init__(self, data_dir, transform=None):"""
RMB:面额分类任务的Dataset
:param data_dir: str, 数据集所在路径
:param transform: torch.transform,数据预处理
"""
self.label_name ={"1":0,"100":1}
self.data_info = self.get_img_info(data_dir)# data_info存储所有图片路径和标签,在DataLoader中通过index读取样本
self.transform = transform
def__getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB')# 0~255if self.transform isnotNone:
img = self.transform(img)# 在这里做transform,转为tensor等等return img, label
def__len__(self):returnlen(self.data_info)
__init__的原理详解
这一部分解释来自Python中__init__的用法和理解,在此感谢这位博主。
在Python中定义类经常会用到__init__函数(方法),首先需要理解的是,两个下划线开头的函数是声明该属性为私有,不能在类的外部被使用或访问。而__init__函数(方法)支持带参数类的初始化,也可为声明该类的属性(类中的变量)。__init__函数(方法)的第一个参数必须为self,后续参数为自己定义。
从文字理解比较困难,通过下面的例子能非常容易理解这个概念:
例如我们定义一个Box类,有width, height, depth三个属性,以及计算体积的方法:
# -*- coding utf-8 -*-#Created by Lu ZhanclassBox:defsetDimension(self, width, height, depth):
self.width = width
self.height = height
self.depth = depth
defgetVolume(self):return self.width * self.height * self.depth
b = Box()
b.setDimension(10,20,30)print(b.getVolume())
我们在Box类中定义了setDimension方法去设定该Box的属性,这样过于繁琐,而用__init__()这个特殊的方法就可以方便地自己对类的属性进行定义,init()方法又被称为构造器(constructor)。
#!/usr/bin/python# -*- coding utf-8 -*-#Created by Lu ZhanclassBox:#def setDimension(self, width, height, depth):# self.width = width# self.height = height# self.depth = depthdef__init__(self, width, height, depth):
self.width = width
self.height = height
self.depth = depth
defgetVolume(self):return self.width * self.height * self.depth
b = Box(10,20,30)print(b.getVolume())
__getitem__的原理详解(全网最细,不接受反驳)
上述代码重点在
__getitem__这里,那我们先要大概搞懂
__getitem__是起什么作用的。w我们下先看一段代码去了解
__getitem__。
classAnimal:def__init__(self, animal_list, age):
self.animals_name = animal_list
self.animals_age = age
def__getitem__(self, index):return self.animals_name[index]
animals = Animal(["dog","cat","fish"],[1,2,3])for i in animals:print(i)
OUT:
dog
cat
fish
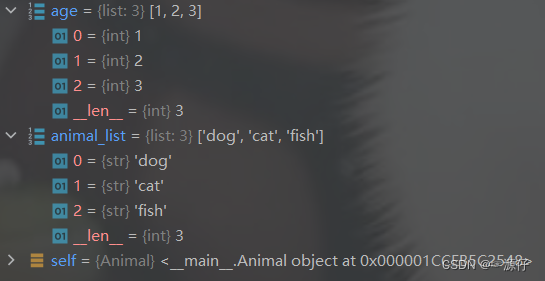
- 我们先
Debug进入Animal这个类,如下动态图所示,可以发现并没有执行def __getitem__(self, index):,而是只执行了初始化def __init__(self, animal_list, age):,导入初始化数据,如动态图下方图片所示:

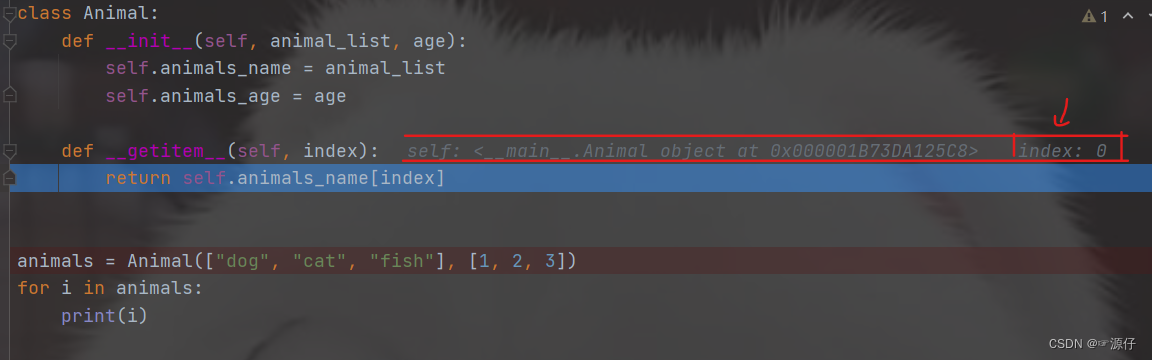
- 那这个
def __getitem__(self, index):是在哪里执行的呢 ! 那我们继续Debug试试。可以从上面动态图注意到,每当
Debug到for循环时,下一步会进入def __getitem__(self, index):获取对应的index,那我怎么知道是去获取对应的index呢,那是因为你们仔细看上面的动态图过程。我从中截取了3张图片,如下图。获取到
index,之后def __getitem__(self, index):会执行return函数,返回return self.animals_name[0](等于dog)、self.animals_name[1](等于cat)、self.animals_name[2](等于fish),那么返回出来的就是我们for循环遍历中的i,到这里我相信大家因该都懂__getitem__的用法了吧。
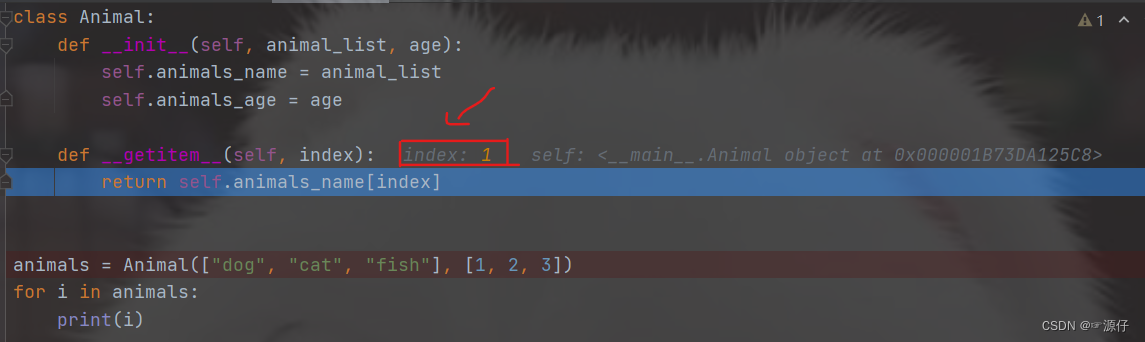
下面我们在返回去看class RMBDataset(Dataset):这段代码,为了方便大家查看,在此在下方复制了一遍。
classRMBDataset(Dataset):def__init__(self, data_dir, transform=None):"""
RMB:面额分类任务的Dataset
:param data_dir: str, 数据集所在路径
:param transform: torch.transform,数据预处理
"""
self.label_name ={"1":0,"100":1}
self.data_info = self.get_img_info(data_dir)# data_info存储所有图片路径和标签,在DataLoader中通过index读取样本
self.transform = transform
def__getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB')# 0~255if self.transform isnotNone:
img = self.transform(img)# 在这里做transform,转为tensor等等return img, label
def__len__(self):returnlen(self.data_info)
1、由上面的讲解,我们会先执行__init__初始化参数。
self.label_name:数据集的标签(label),也就是数据集的类别。data_info:存储所有图片路径和标签,在DataLoader中通过index读取样本。self.transform:就是数据预处理。
问了能大家能更好了理解,我
debug
了两个循环的参数给大家看看(上述
RMBDataset
类中所有变量参数都在下图中展示出来了),如下图所示: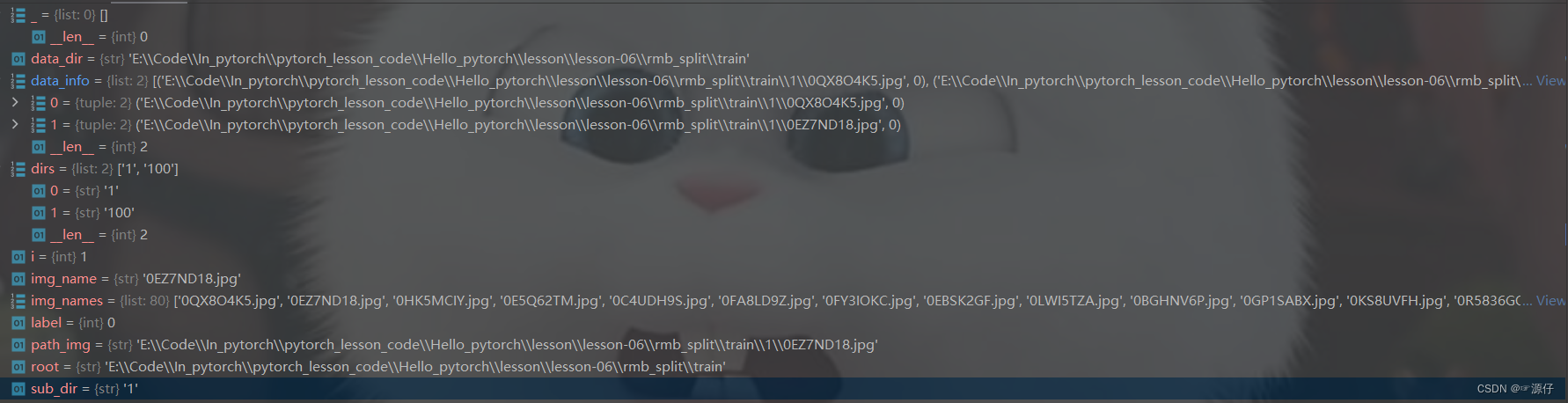
最后我们看一下经过RMBDataset类后的train_data和valid_data包含什么?如下图所示:

# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
DataLoader这个类,接收的参数就是上面的
RMBDataset,我们知道这个是返回一个样本的张量和标签,然后又跟了一个
BATCH_SIZE, 看到这个,你心里应该有数了,这个不就是说一个
batch里面有多少个样本吗? 如果有了一个batch的样本数量,有了样本总数,就能得到总共有多少个
batch了。 后面的
shuffle,这个是说我取图片的时候,把顺序打乱一下,不是重点。 那么你是不是又好奇点东西了, 这个
DataLoader在干啥事情呢? 其实它在干这样的事情,我们只要指定了
Batch_SIZE, 比如指定
10个, 我们总共是有
100个训练样本,那么就可以计算出批数是
10, 那么
DataLoader就把样本分成
10批顺序打乱的数据,每一个
Batch_size里面有
10个样本且都是
张量和
标签的形式。
由于DataLoader源码太长,我们大概知道DataLoader是起什么作用的就好。下面我们直接从训练的部分看,像中间的模型,损失函数,优化器不是重点,所以这里先不放上来:
for epoch inrange(MAX_EPOCH):
loss_mean =0.
correct =0.
total =0.
net.train()for i, data inenumerate(train_loader):# forward
inputs, labels = data
outputs = net(inputs)# backward
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()# update weights
optimizer.step()
上面就是训练部分的核心了,这个比较好理解, 两层循环,外循环表示的迭代
Epoch,也就是全部的训练样本喂入模型一次, 内循环表示的批次的循环,每一个
Epoch中,都是一批批的喂入, 那么数据读取具体使用的重点就是
for i, data in enumerate(train_loader)这句话了, 所以我们
Debug看看这个函数究竟是怎么去得到数据的?
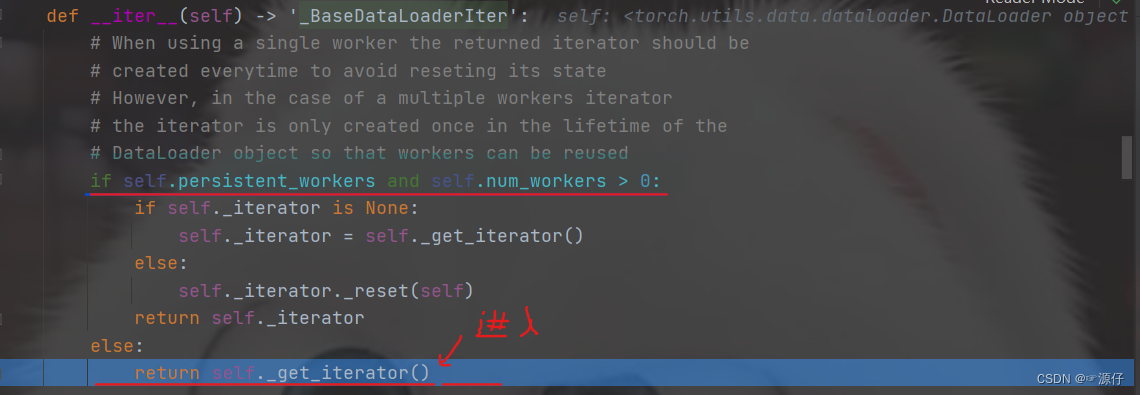
Step-into进入后这样就会看到,程序跳转到了
DataLoader的
__iter__(self)这个方法,毕竟这是个迭代的过程, 但是简单的瞄一眼这个函数,就会发现就一个判断,说的啥呢? 原来在说是用单进程还是用多进程读取机制进行处理, 关于读取数据啥也没干。 所以这个也不是重点, 我们使用
stepover进行下一步,然后在
stepinto进入单进程(
_SingleProcessDataLoaderIter)的这个机制里面。
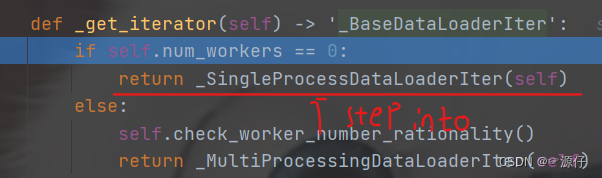
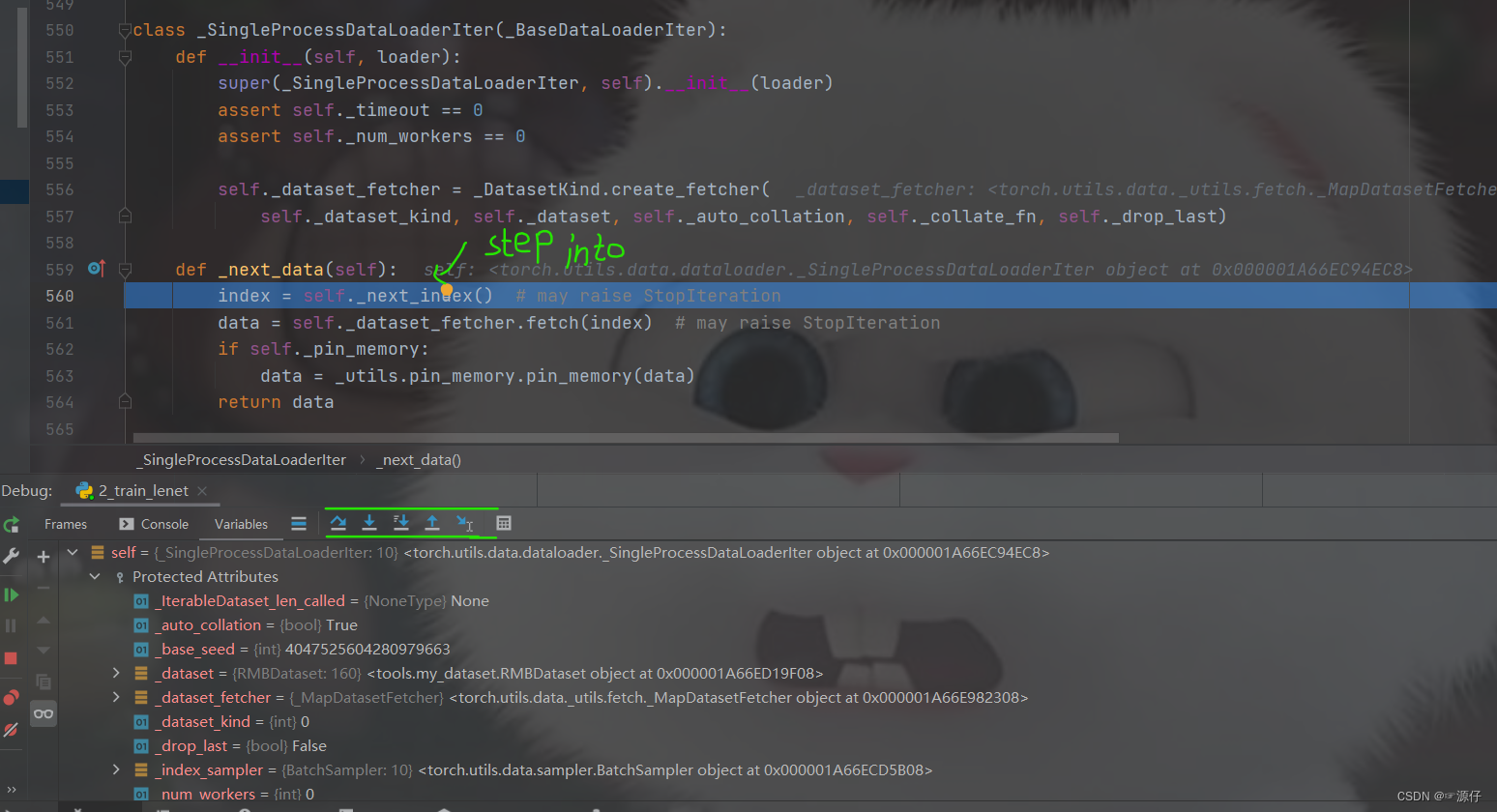
在stepinto进入单进程(
_SingleProcessDataLoaderIter)的这个机制后,比较重要的一个方法就是
__next__(self), 上面不是说
RMBDataset函数是能返回一个样本和标签吗? 这里的这个next, (如下图所示)看其字面意义就知道这个是获取下一个样本和标签,重要的两行代码就是红色线条
(index\data)这两行,
self.__next__index()获取下一个样本的
index, 然后
self.dataset_fetcher.fetch(index)根据
index去获取下一个样本, 那么是怎么做到的? 继续调试:将光标放到
__next__index()这一行,然后点击下面的
run to cursor图表,就会跳到这一行,然后
stepinto。
操作如下图所示:step-into进入,这里是返回了一个
return next(self.sampler_iter), 所以重点应该是这个东西,我们继续
stepinto
step-into进入后,这里发现进入了
sampler.py, 这里面重要的就是这个
__iter__(self), 这个方法正是一次次的去采样我们的数据的索引,然后够了一个
batch_size了就返回了。 那这一次取到的哪些样本的索引呢? 我们可以跳出这个函数,回去看看(连续两次跳出函数,回到
dataloader.py):
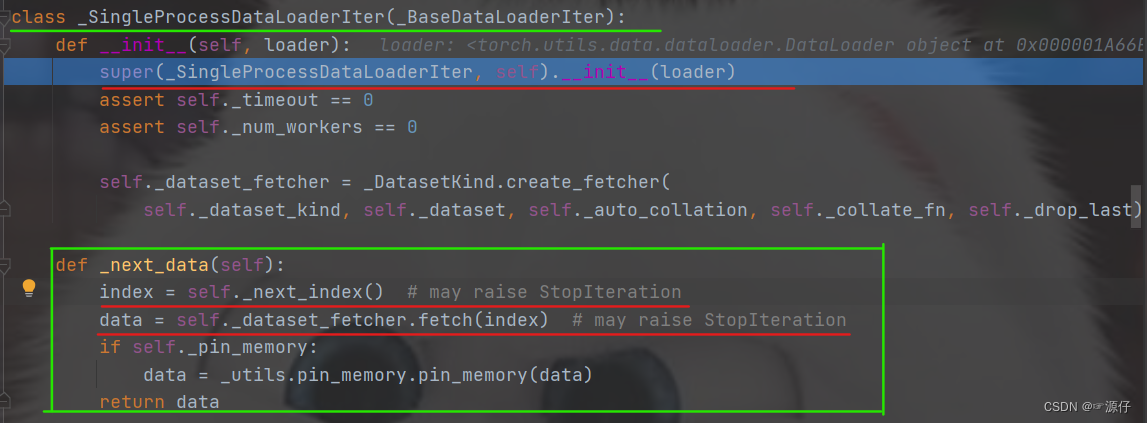

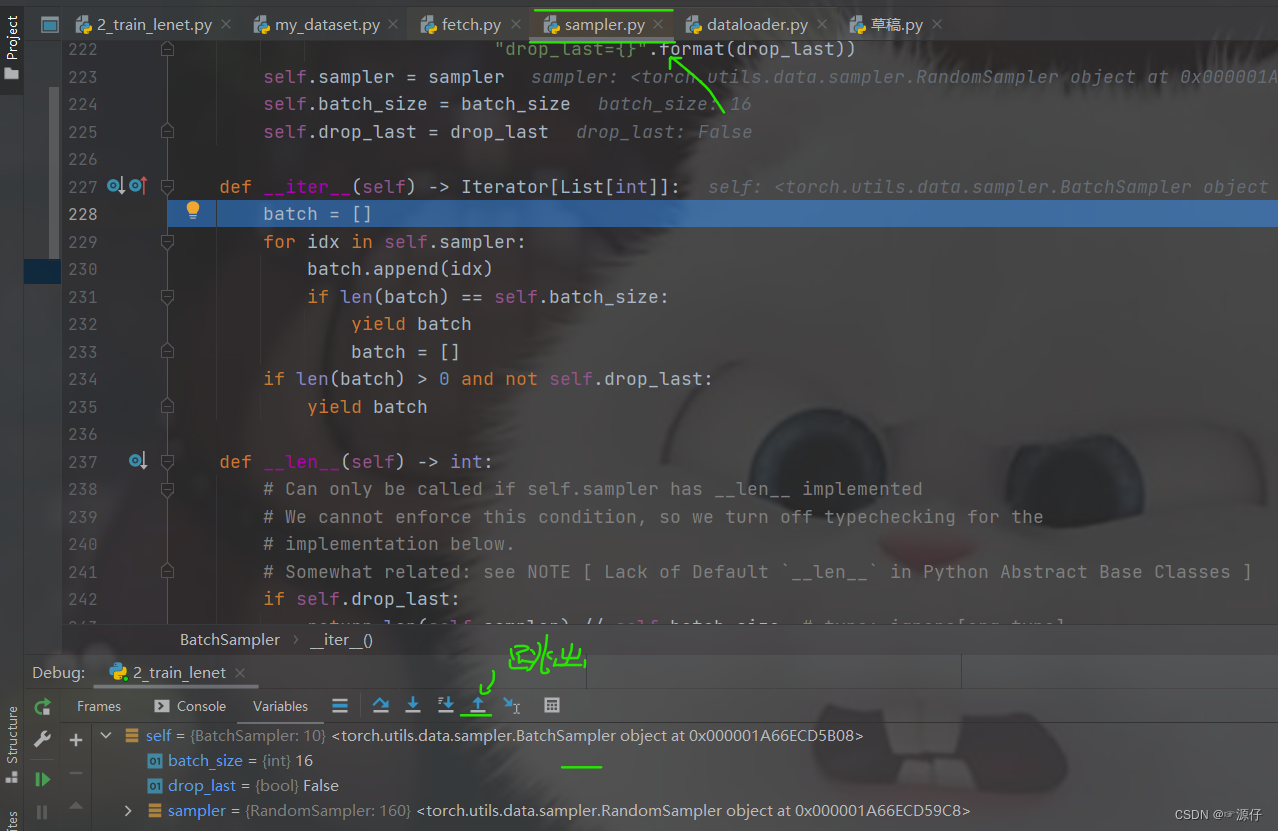
然后
stepover到
data这一行, 这个意思就是说,
index这一样代码执行完毕,我们可以看到最下面取到的
index(可以和上上张图片,没执行这个函数的时候对比一下),我们的
batch_size设置的
16, 所以通过上面的
sampler.py获得了
16个样本的索引。
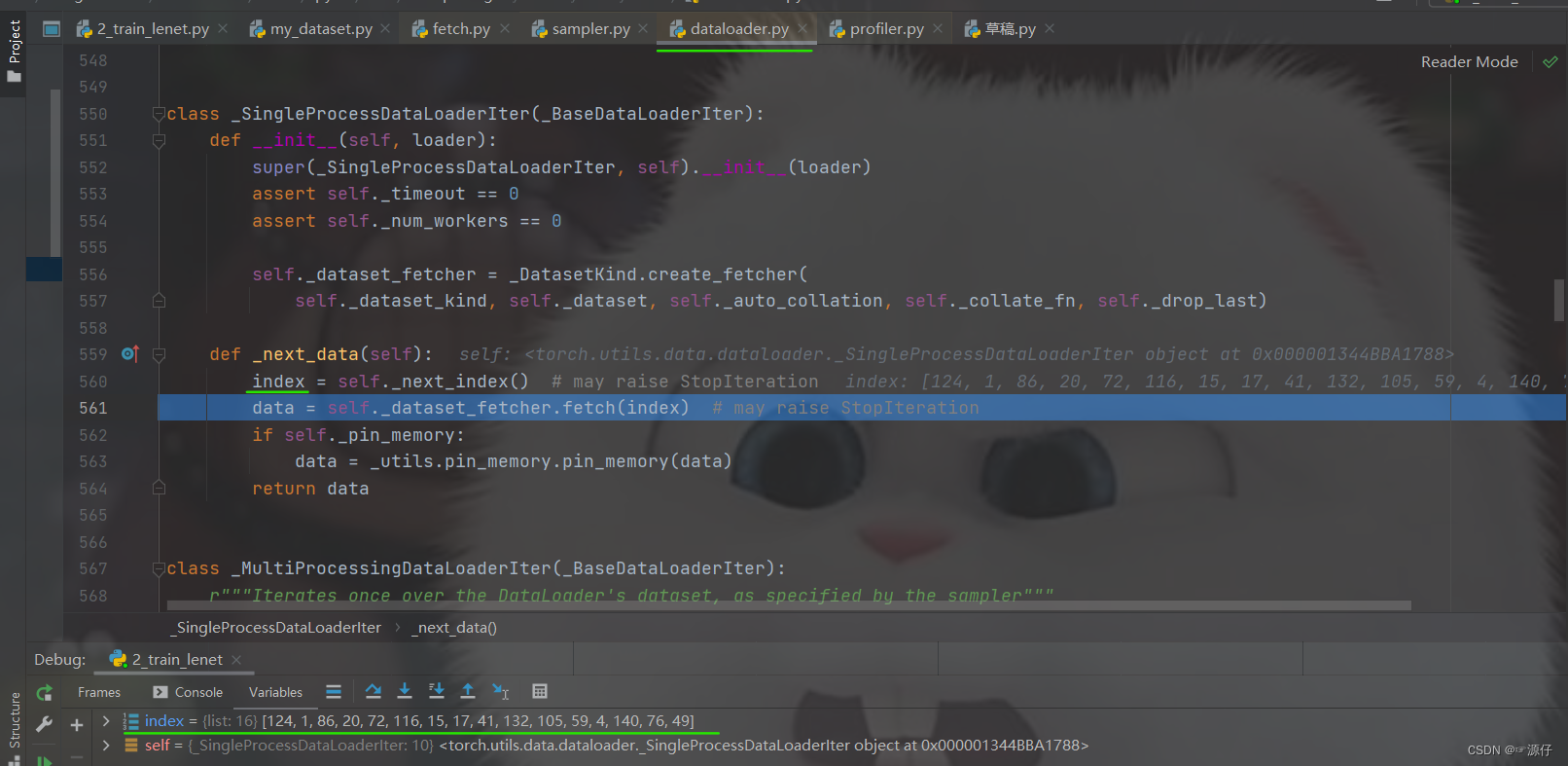
这样,我们就有了一个批次的
index, 那么就好说了,根据
index取不就完事了, 所以第二行代码
data = self.dataset_fetcher.fetch(index)就是取数据去了,重点就是这里的
dataset_fetcher.fetch方法, 我们继续
debug看看它是怎么取数据的。
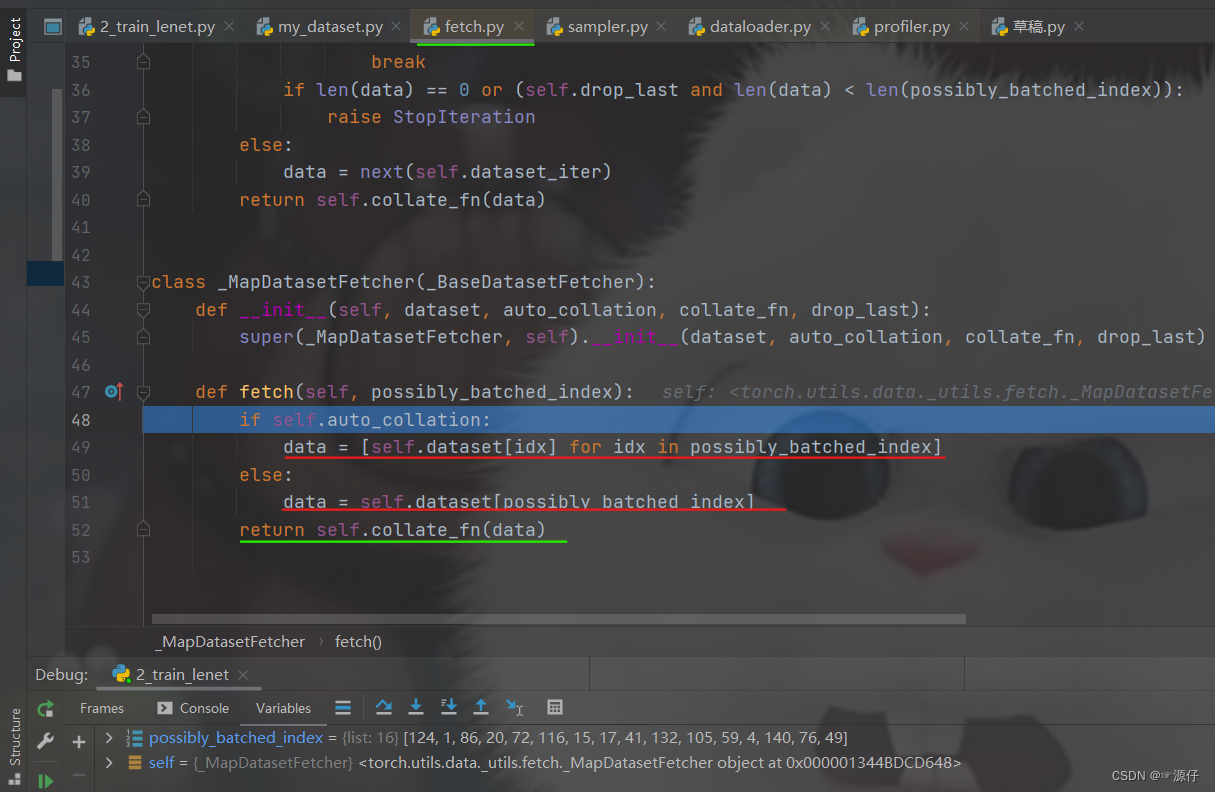
这样进入了
fetch.py, 然后核心是这里的
fetch方法,这里面会发现调用了
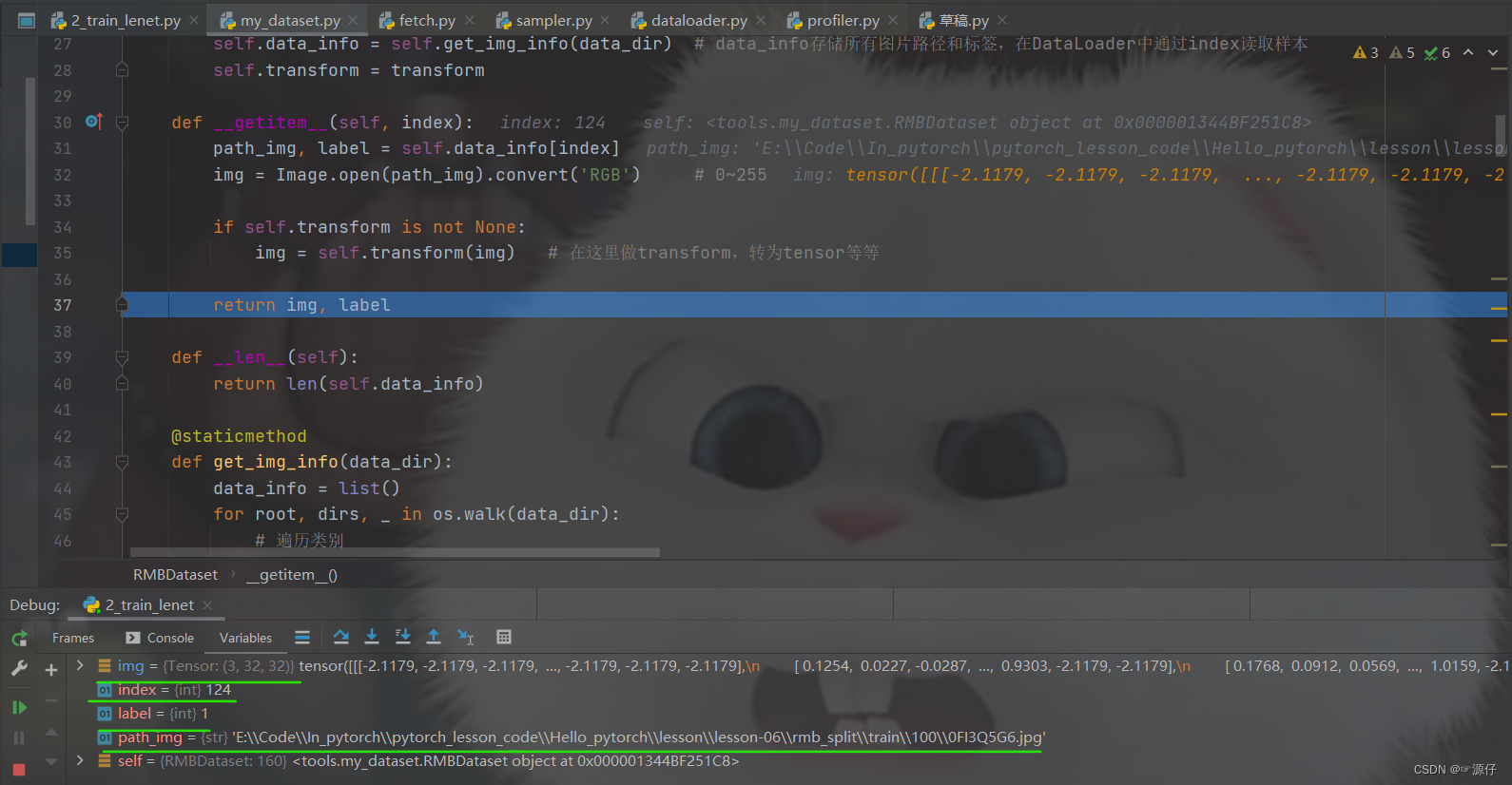
self.dataset[idx]去获取数据, 那么我们再步入一步,就看到了奇迹:

我们步进式运行一下,看一下对应的
path_img和
img以及
label输出的形式,如下图:
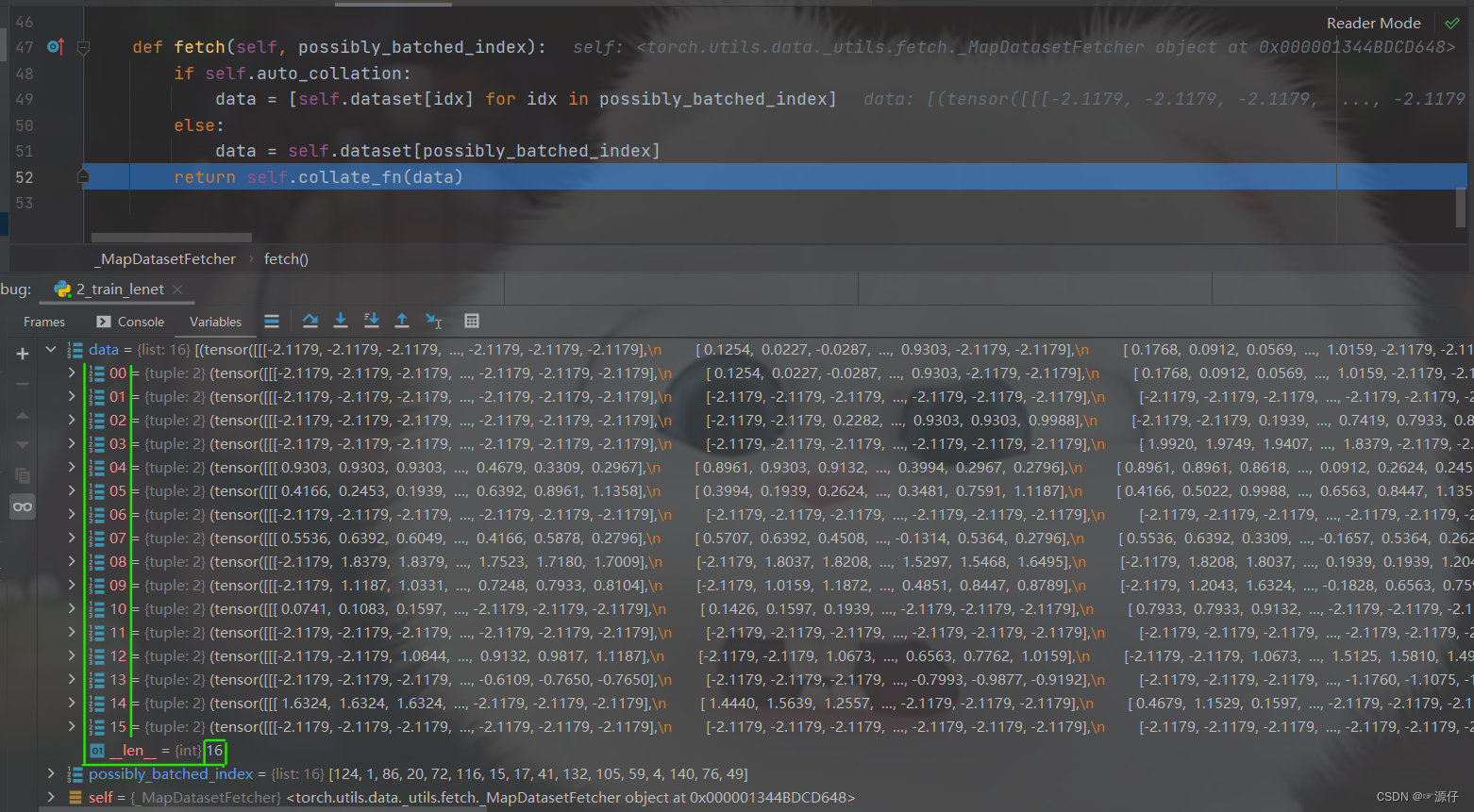
在
Run to cursor到
return self.collate_fn(data)这是已经取完了一个批次, 然后进入
self.collate_fn(data)进行整合,就得到了我们一个批次的data,最终我们返回来。
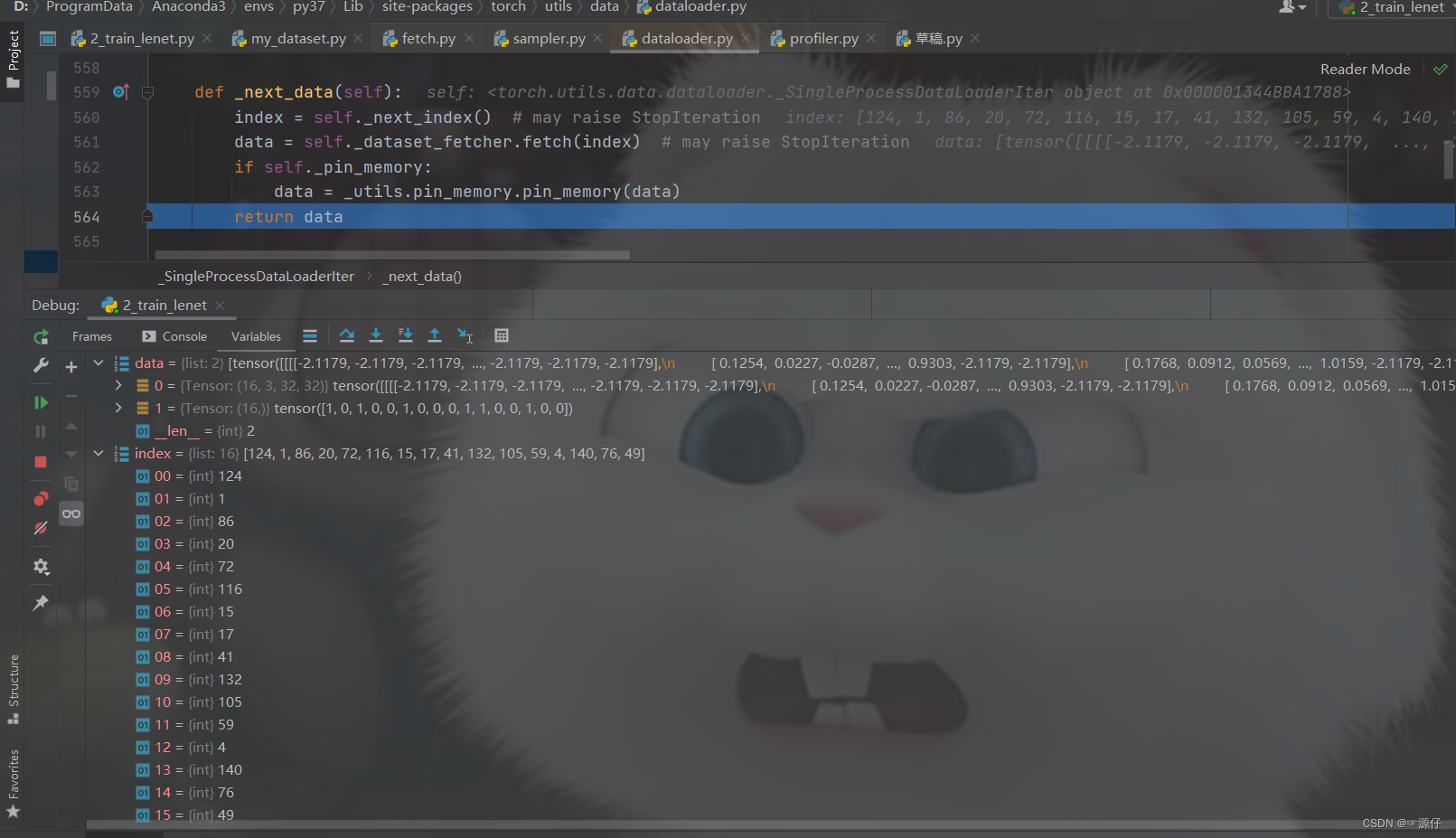
再
step over就返回到
def _next_data(self):中:
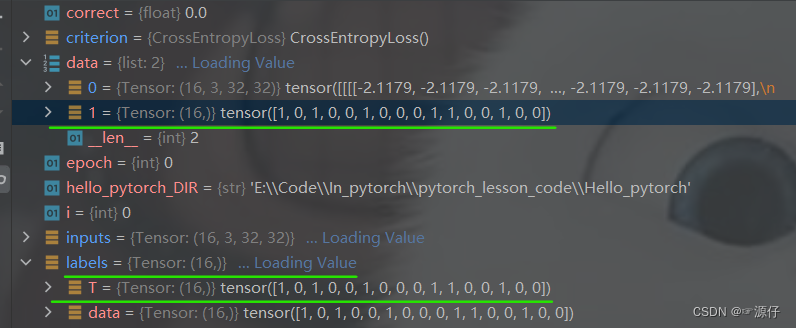
由下面两张图我们可以知道,
data中含有:
input = 0 = {Tensor: 16,3,32,32}: 这指的是16张 32 × 32 32 \times 32 32×32的彩色(3通道)图片。label= 1 = {Tensor: 16,},{1,0,1,0,0,1,0,0,0,1,1,0,0,1,0,0}:这指的是16张图片分别对应的标签,也就是每张图片对应的类别。
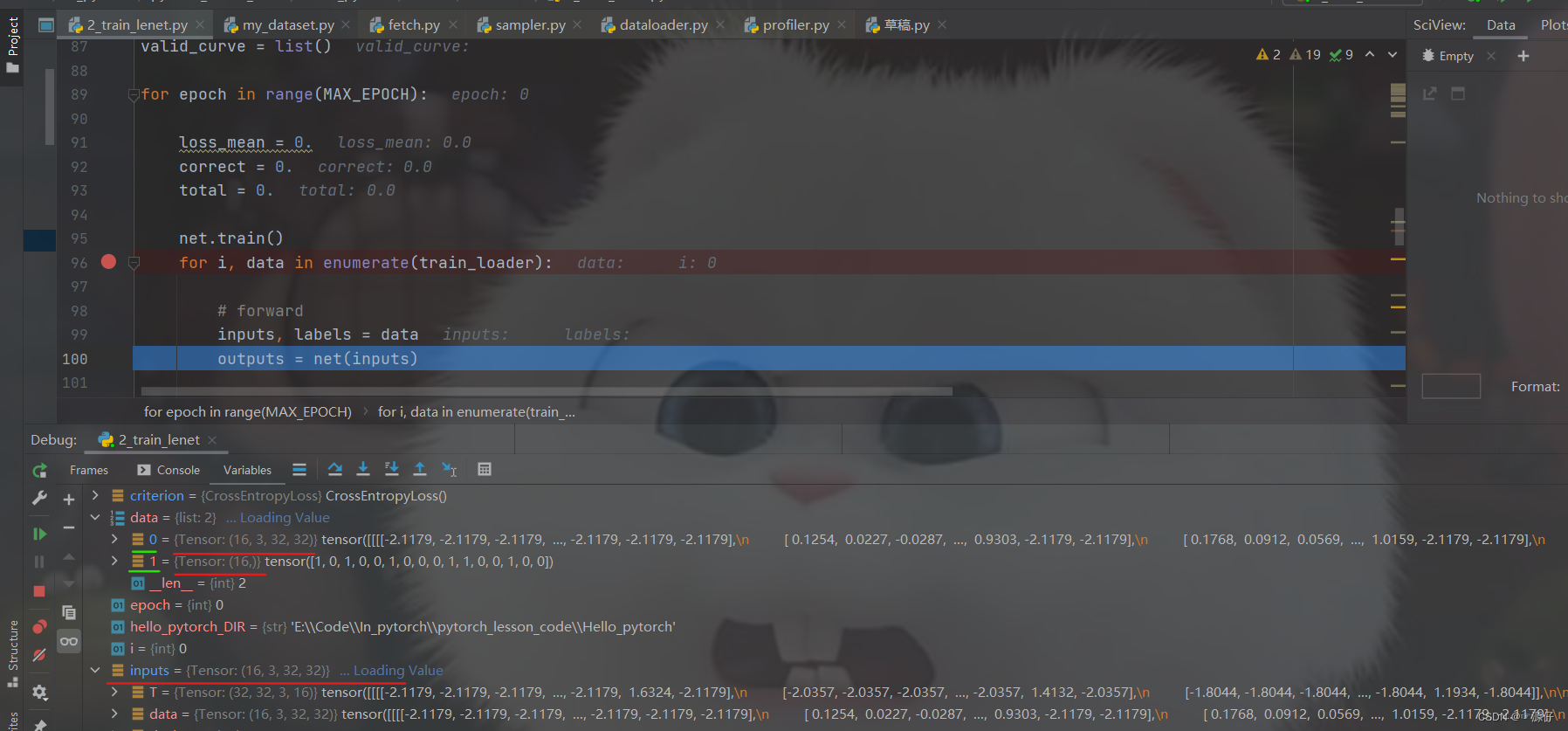
好了, 上面就是
DataLoader读取数据的过程了,可能代码调试的过程确实比较乱,或许看不大懂,所以我们基于那三个问题梳理一遍逻辑,把逻辑关系看懂就好了, 并且最后用灵魂画笔来个流程图再进行梳理。 还记得我们的三个问题吗?
- 读哪些数据? 这个我们是根据
Sampler出的index决定的- 从哪读数据? 这个是
Dataset的data_dir设置数据的路径,然后去读- 怎么读数据? 这个是
Dataset的getitem方法,可以帮助我们获取一个样本
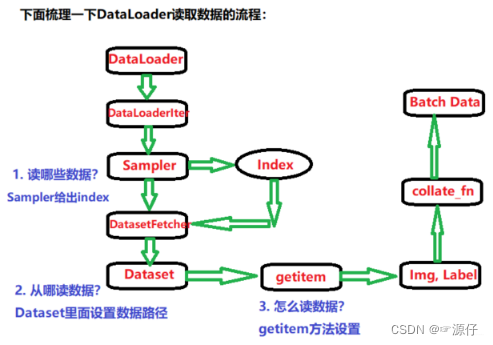
我们知道,DataLoader读取数据的过程比较麻烦,用到了四五个.py文件的跳转,所以梳理这个逻辑关系最好的方式就是流程图:
通过这个流程图,把DataLoader读取数据的流程梳理了一遍,具体细节不懂没有关系,但是这个逻辑关系应该要把握住,这样才能把握宏观过程,也能够清晰的看出
DataLoader和
Dataset的关系。 根据前面介绍,
DataLoader的作用就是构建一个数据装载器, 根据我们提供的
batch_size的大小, 将数据样本分成一个个的
batch去训练模型,而这个分的过程中需要把数据取到,这个就是借助
Dataset的
getitem方法。
这样也就清楚了,如果我们想使用Pytorch读取数据的话,首先应该自己写一个
MyDatase,这个要继承
Dataset类并且实现里面的
__getitem__方法,在这里面告诉机器怎么去读数据。 当然这里还有个细节,就是还要覆盖里面的
__len__方法,这个是告诉机器一共有多少个样本数据。 要不然机器没法去根据
batch_size的个数去确定有多少批数据。这个写起来也很简单,返回总的样本的个数即可。
def__len__(self):returnlen(self.data_info)
这样, 机器就可以根据Dataset去硬盘中读取数据,接下来就是用DataLoader构建一个可迭代的数据装载器,传入如何读取数据的机制Dataset,传入batch_size, 就可以返回一批批的数据了。 当然这个装载器具体使用是在模型训练的时候。 当然,由于DataLoader是一个可迭代对象,当我们构建完毕之后,也可以简单的看下里面的数据到底长什么样, 大致代码是:
# 查看一个batch_size的数据for x, y in train_loader:print(x, y)break
好了,上面就是
Pytorch读取机制
DataLoader和
Dataset的原理部分了。
人民币二分类的数据模块里面,除了数据读取机制
DataLoader,还涉及了一个图像的预处理模块
transforms, 是对图像进行预处理的,在下一篇博客中,我会详解讲解
Pytorch中对数据预处理的常用方法,再搞定这个细节,人民币二分类任务的数据模块就全部结束了哈。
本文参考博客链接
**
本文的全套代码下载点击此处
**:https://download.csdn.net/download/weixin_54546190/85539252人名币二分类完整Python代码(包含数据集
**
感谢大家观看,如果觉得博主写的不错的话,别忘了点个赞啊。
**
1、数据加载Dataset和DataLoader的使用
2、Pytorch数据读取机制(DataLoader)与图像预处理模块(transforms)
版权归原作者 ☞源仔 所有, 如有侵权,请联系我们删除。