图片、视频修复并超分 - Real-ESRGAN项目使用(一) | 机器学习
前段时间一直在弄golang,很少关注一些开源项目。正巧碰到一个,可以将模糊的照片或者视频修复清晰,且可以超分处理的项目。
机器学习强基计划8-5:图解局部线性嵌入LLE算法(附Python实现)
局部线性嵌入(Locally Linear Embedding, LLE)限制样本在降维后的低维空间中的k近邻局部线性关系,等价于原始空间。本文详解LLE算法原理并给出Python实现
AI算力碎片化:矩阵乘法的启示
尽管AI的发展取得了巨大进步,但编译器LLVM之父Chris Lattner认为,AI技术应用并不深入,远远没有发挥出已有机器学习研究的所有潜力。而AI系统和工具的单一化和碎片化正是造成这一问题的根源。为了让AI发挥其真正的潜力,计算碎片化是需要解决的重点问题之一,目标是让AI软件开发人员能够无缝地
评估车辆之间安全距离的指标
公式为:KD = V * T + 0.5 * a * T^2,其中V为初始速度,a为加速度,T为时间。TTC(Time to Collision,碰撞时间):指车辆在当前速度下到达前车的时间,通常以秒为单位,公式为:TTC = d / (v_rel + 0.001),其中d为当前距离,v_rel为当
交叉验证之KFold和StratifiedKFold的使用(附案例实战)
交叉验证是在机器学习建立模型和验证模型参数时常用的办法。交叉验证,顾名思义,就是重复的使用数据,把得到的样本数据进行切分,组合为不同的训练集和测试集,用训练集来训练模型,用测试集来评估模型预测的好坏。在此基础上可以得到多组不同的训练集和测试集,某次训练集中的某样本在下次可能成为测试集中的样本,即所谓
【机器学习】KNN算法及K值的选取
KNN算法及K值的选取
【AI大模型】讯飞版大模型来了!首发通用人工智能评测体系,现场发布四大行业应用成果
科大讯飞推出的新一代认知智能大模型,拥有跨领域的知识和语言理解能力,能够基于自然对话方式理解与执行任务。从海量数据和大规模知识中持续进化,实现从提出、规划到解决问题的全流程闭环。
深入理解机器学习——偏差(Bias)与方差(Variance)
即刻画了学习问题本身的难度。给定学习任务,为了取得好的泛化性能,则需使偏差较小,即能够充分拟合数据,并且使方差较小,即使得数据扰动产生的影响小一般来说,偏差与方差是有冲突的,这称为偏差方差窘境(Bias-Variance Dilemma)。随着训练程度的加深,学习器的拟合能力逐渐增强,训练数据发生的
强化学习——多智能体强化学习
文章目录前言多智能体系统的设定合作关系设定下的多智能体系统策略学习的目标函数合作关系下的多智能体策略学习算法MAC-A2C前言本文总结《深度强化学习》中的多智能体强化学习相关章节,如有错误,欢迎指出。多智能体系统的设定多智能体系统包含有多个智能体,多个智能体共享环境,智能体之间相互影响。一个智能体的
损失函数——交叉熵损失(Cross-entropy loss)
对于每个类别i,yi表示真实标签x属于第i个类别的概率,y^i表示模型预测x属于第i个类别的概率。对于每个输入数据x,我们定义一个C维的向量y^,其中y^i表示x属于第i个类别的概率。假设真实标签y是一个C维的向量,其中只有一个元素为1,其余元素为0,表示x属于第k个类别。该函数将输入数
强化学习分类与汇总介绍
强化学习分类与汇总介绍
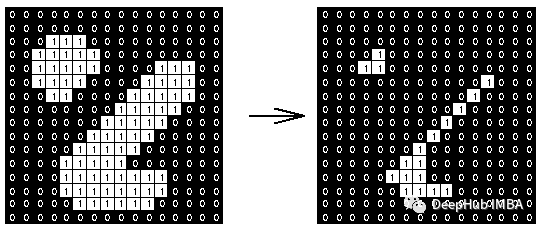
形态学运算与仿真:图像处理中形态学操作的简单解释
形态学是图像处理领域的一个分支,主要用于描述和处理图像中的形状和结构。形态学可以用于提取图像中的特征、消除噪声、改变图像的形状等。其中形态学的核心操作是形态学运算。
很佩服的一个Google大佬,离职了。。
除此之外,他的高曾祖父George Boole还是著名的逻辑学家,也是现代计算科学的基础布尔代数的发明人,而他的叔叔Colin Clark则是一个著名的经济学家。除此之外,Hinton在他的学术生涯中发表了数百篇论文,这些论文中提出了许多重要的理论和方法,涵盖了人工智能、机器学习、神经网络、计算机视
基于Flask+Bootstrap+机器学习的南昌市租房价格预测系统
本项目使用Flask框架搭建基于机器学习的南昌市租房价格预测系统 (简易版)其中关于Flask知识点可参考文章Flask全套知识点从入门到精通,学完可直接做项目其中关于南昌市租房价格预测可参考文章基于XGBoost算法构造房屋租赁价格评估模型整个项目分为以下几个模块:项目文件框架如下:其中manag
gpt.4.0-gpt 国内版
GPT(Generative Pre-trained Transformer)是一种预训练的语言模型,可用于多种自然语言处理任务,如情感分析、文本分类、文本生成等。下面是使用GPT的一些步骤和建议:确定任务和数据集:首先,需明确自己的任务和应用场景,选择合适的数据集进行训练和测试。例如,如果要生成诗
深度学习的定义和未来发展趋势
深度学习的定义及原理📜📜深度学习是一种基于神经网络、具有多个隐藏层来提取高级抽象特征进行模式识别和决策的机器学习技术。其核心思想与人脑神经元相似,通过逐层的计算和学习,将输入数据转化为具有更高级别的表示,从而实现对复杂数据结构的建模和分析。📜深度学习中最重要的思想是构建可训练的人工神经网络模型
ChatGPT重量级对手产品:Claude对外发布
什么是ClaudeClaude是下一代人工智能助手,基于 Anthropic 对训练有用、诚实和无害的人工智能系统的研究。Claude 可通过我们的开发人员控制台中的聊天界面和 API 进行访问,能够执行各种对话和文本处理任务,同时保持高度的可靠性和可预测性。克劳德可以帮助处理总结、搜索、创意和协作
【信息与内容安全】实验二:虚假人脸检测实验
虚假人脸检测实验摘要: 在此次实验中,先尝试了自己手动搭建了一个 CNN 进行虚假人脸的分类实验,但发现有训练速度慢准确率低等缺点。所以尝试使用已有的模型(resnet-18)和预训练的参数进行迁移学习,包括尝试了直接把卷积层借用为固定特征提取器和 Fine-tuning 的方法,大大提高了训练速度
前沿探索,AI 在 API 开发测试中的应用
Apikit 是结合 API 设计、文档管理、自动化测试、监控、研发管理和团队协作的一站式 API 生产平台,可以快速、规范地管理所有 API,已经成为当前 API 研发管理的主流产品。
【五一创作】自动驾驶技术未来大有可为
自动驾驶技术是指通过计算机技术和各种传感器,使得汽车可以在不需要人类干预的情况下完成行驶任务。这项技术在近年来得到了快速的发展,并在汽车制造业、城市规划和交通管理等领域引起了广泛的关注和讨论。传感器技术、计算机视觉技术和人工智能技术。



