
文章目录
前言
在这里,我就简单写一下两个激活函数的概念以及区别,详细的过程可以看看其他优秀的博主,他们写的已经非常好了,我就不必再啰嗦了。
ReLU(Rectified Linear Unit)和SiLU(Sigmoid Linear Unit)都是常用的激活函数,它们的主要区别在于非线性形状不同。
ReLU(Rectified Linear Unit)
概念:
ReLU函数在输入大于0时直接输出,否则输出0。它的数学形式为f(x) = max(0, x),可以看作是一个分段函数,具有非常好的计算性质,使得神经网络的训练更加高效。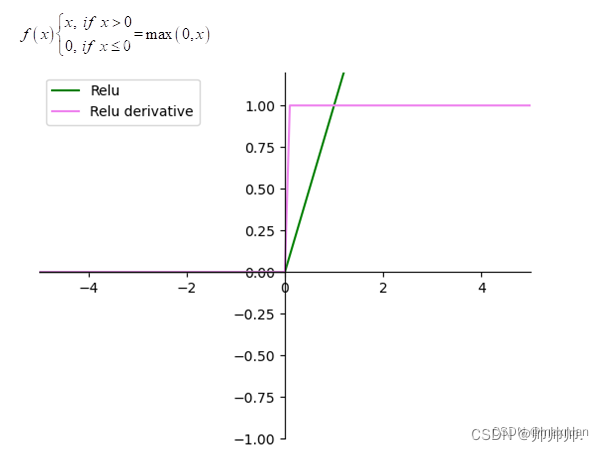
Leaky ReLU
概念:
Leaky ReLU是ReLU的一种变体,改变之处在于 负数的输出不再是0了,而是一个很小的数值,比如0.1或0.01。
优点:
Leaky ReLU的优点在于可以避免出现“神经元死亡”的情况,即在训练过程中某些神经元的输出始终为0,从而导致无法更新其权重,而Leaky ReLU可以在一定程度上解决这个问题。
FReLU(Flatten ReLU)
概念:
FReLU将输入展平(flatten)成一个一维向量,然后对每个元素应用ReLU激活函数,最后再将输出重新恢复成原来的形状。
优点:
- 减少参数量:FReLU不需要额外的参数,因此可以减少模型的参数量。
- 具有更好的表示能力:由于FReLU可以将输入展平成一维向量,因此可以在不增加参数量的情况下提高模型的表示能力。
- 提高模型的鲁棒性:由于FReLU对输入进行了展平操作,因此可以提高模型对输入的鲁棒性,从而减少过拟合的风险。
SiLU(Sigmoid Linear Unit)
相对于ReLU函数,SiLU函数在接近零时具有更平滑的曲线,并且由于其使用了sigmoid函数,可以使网络的输出范围在0和1之间。这使得SiLU在一些应用中比ReLU表现更好,例如在语音识别中使用SiLU比ReLU可以取得更好的效果。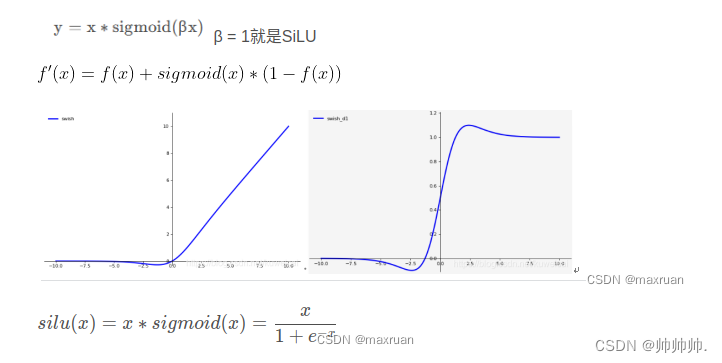
🤬------------注意----------🤬:
在使用SiLU时,如果数据存在过大或过小的情况,可能会导致梯度消失或梯度爆炸,因此需要进行一些调整,例如对输入数据进行归一化等。而ReLU在这方面较为稳定,不需要过多的处理。
总结
- 相较于ReLU函数,SiLU函数可能会更适合一些需要保留更多输入信息的场景。
- ReLU和SiLU都是常用的激活函数,具有各自的优点和适用范围,需要根据具体情况进行选择。
图片来自于:
https://blog.csdn.net/long630576366/article/details/128854678
版权归原作者 帅帅帅. 所有, 如有侵权,请联系我们删除。