
时间序列异常检测的5种方法:从统计阈值到深度学习
异常检测的核心不在于找出"奇怪的数字",而在于理解每个时间点上什么才算正常。
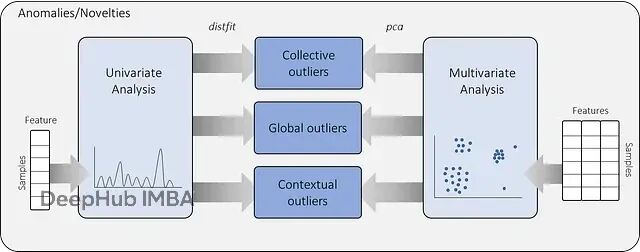
Python离群值检测实战:使用distfit库实现基于分布拟合的异常检测
本文会先讲清楚异常检测的核心概念,分析anomaly和novelty的区别,然后通过实际案例演示如何用概率密度拟合方法构建单变量数据集的无监督异常检测模型。所有代码基于distfit库实现。
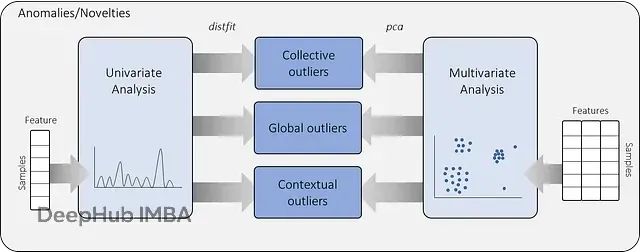
PCA多变量离群点检测:Hotelling's T2与SPE方法原理及应用指南
本文将系统阐述基于PCA的异常值检测理论框架,重点介绍霍特林T²统计量和SPE/DmodX(平方预测误差/距离建模残差)两种核心方法,并通过连续变量和分类变量的实际案例,详细演示无监督异常值检测模型的构建过程。
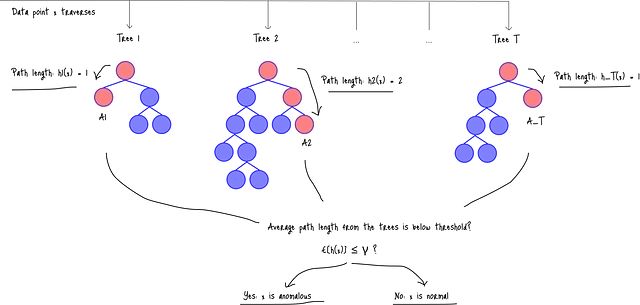
机器学习异常检测实战:用Isolation Forest快速构建无标签异常检测系统
本研究通过实验演示了异常标记如何逐步完善异常检测方案和主要分类模型在欺诈检测中的应用。实验结果表明,Isolation Forest作为一个强大的异常检测模型,无需显式建模正常模式即可有效工作,在处理未见风险事件方面具有显著优势。
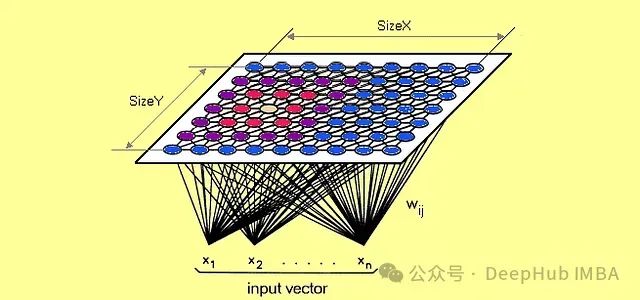
面向概念漂移的动态自组织映射(SOM)及其在金融风险预警中的效能评估
自组织映射(Self-Organizing Maps),又称**Kohonen映射**,是由芬兰学者**Teuvo Kohonen**在20世纪80年代提出的一种无监督神经网络模型。其核心功能是将高维数据空间投影到低维(通常为二维)网格结构中。
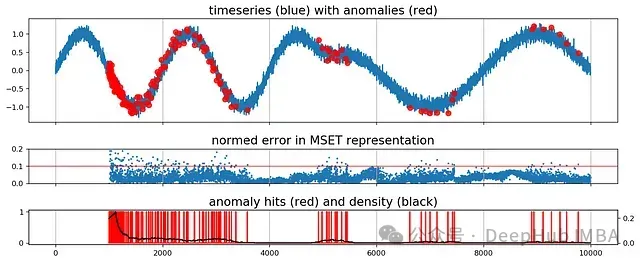
时间序列异常检测:MSET-SPRT组合方法的原理和Python代码实现
MSET-SPRT框架通过上述两种技术的协同作用,为多元数据异常检测提供了准确且高效的解决方案,特别适用于高维度、高相关性的时间序列数据分析。
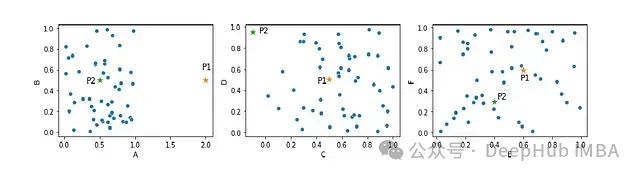
基于特征子空间的高维异常检测:一种高效且可解释的方法
本文将重点探讨一种替代传统单一检测器的方法:不是采用单一检测器分析数据集的所有特征,而是构建多个专注于特征子集(即*子空间*)的检测器系统。
pyflink 时序异常检测——PEWMA
EWMA:μt=αμt−1+(1−α)Xt\mu_t = \alpha \mu_{t-1} + (1 - \alpha ) X_tμt=αμt−1+(1−α)XtPEWMA:μt=α(1−βPt)μt−1+(1−α(1−βPt))Xt\mu_t = \alpha (1 - \beta P_t)
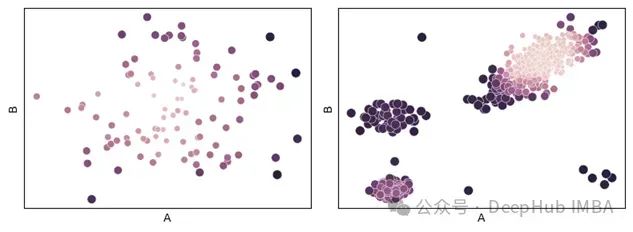
基于距离度量学习的异常检测:一种通过相关距离度量的异常检测方法
但在本文中,将一种非常通用且可能未被充分使用的方法,用于计算表格数据中两条记录之间的差异,这对异常检测非常有用,称为*距离度量学习* - 以及一种专门应用于异常检测的方法。

Doping:使用精心设计的合成数据测试和评估异常检测器的技术
使用Doping方法,真实数据行会被(通常是)随机修改,修改的方式是确保它们在某些方面可能成为异常值,这时应该被异常检测器检测到。然后通过评估检测器检测Doping记录的效果来评估这些检测器。

使用PyOD进行异常值检测
异常值检测各个领域的关键任务之一。PyOD是Python Outlier Detection的缩写,可以简化多变量数据集中识别异常值的过程。在本文中,我们将介绍PyOD包,并通过实际给出详细的代码示例
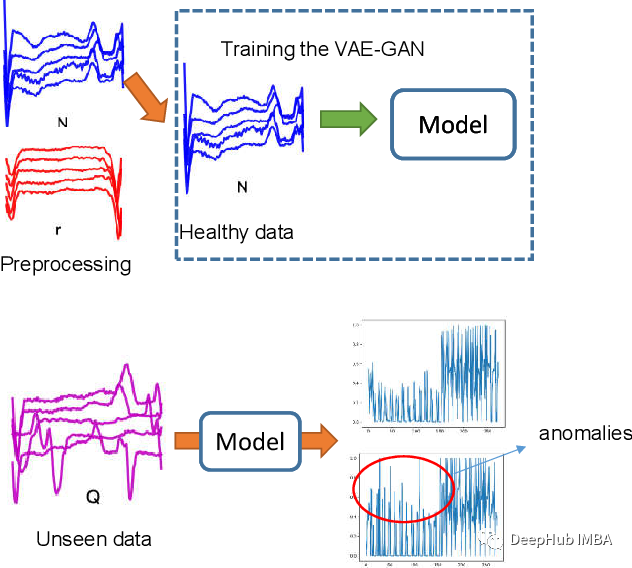
使用GAN进行异常检测
GAN是一种深度学习模型,可以学习生成与给定数据集相似的真实数据样本。这一特性表明它们可以成功地用于异常检测

快速找到离群值的三种方法
本文将介绍3个在数据集中查找离群值的Python方法
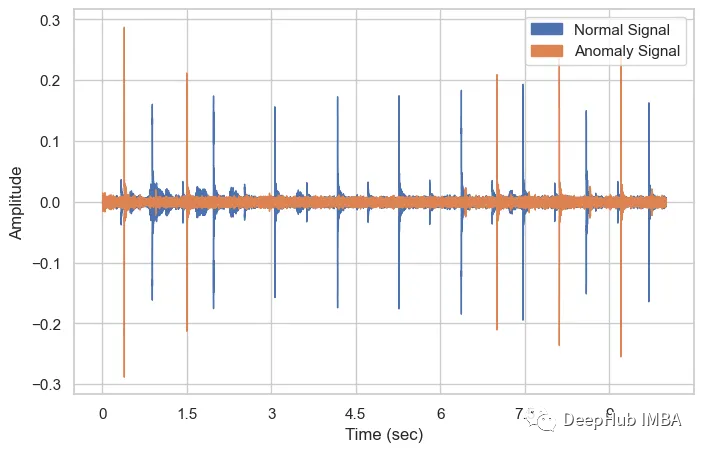
基于声音信号的工业设备异常检测
本文将介绍基于声音信号的工业机械异常检测,使用的数据集是MIMII声音数据集,该数据集很容易在网上获得。
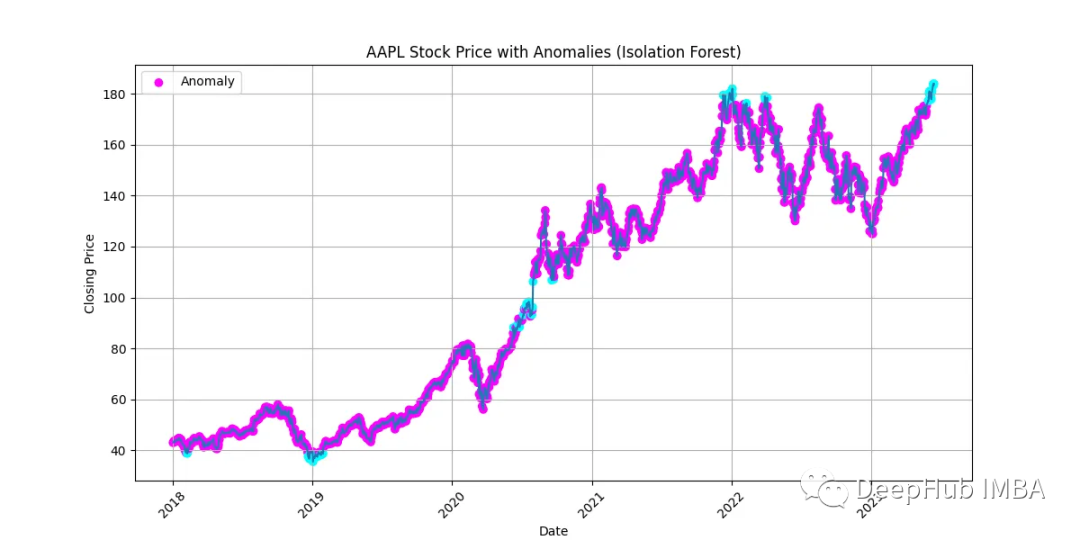
时间序列异常检测:统计和机器学习方法介绍
在本文中将探索各种方法来揭示时间序列数据中的异常模式和异常值。

检测和处理异常值的极简指南
本文是关于检测和处理数据集中的异常值
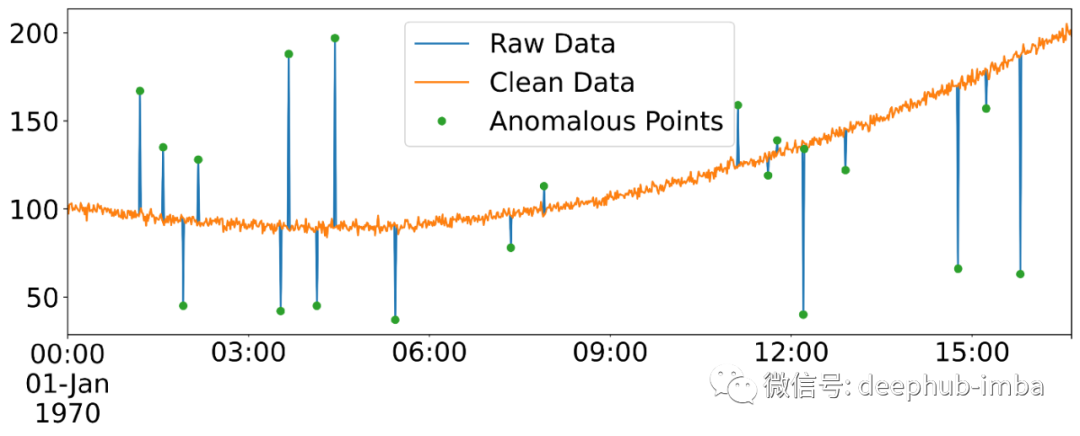
用于时间序列异常检测的学生化残差( studentized residual)的理论和代码实现
学生化这个词其实就是studentized的中文直译,因为约定俗成了所以也没什办法,studentized就是把其他分布转换成t分布,所以其实 studentized residual 翻译为 化残差,要比 学生化残差 更自然,也更好理解

使用孤立森林进行无监督的离群检测
孤立森林是 一种无监督算法的异常检测,可以快速检测数据集中的异常值。



