
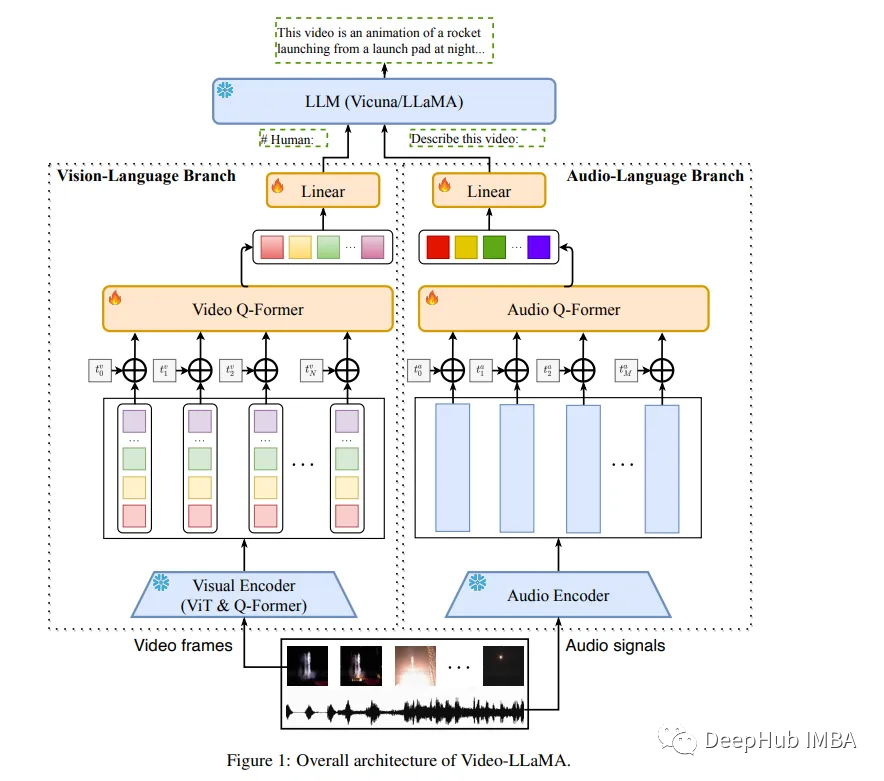
在数字时代,视频已经成为一种主要的内容形式。但是理解和解释视频内容是一项复杂的任务,不仅需要视觉和听觉信号的整合,还需要处理上下文的时间序列的能力。本文将重点介绍称为video - llama的多模态框架。Video-LLaMA旨在使LLM能够理解视频中的视觉和听觉内容。论文设计了两个分支,即视觉语言分支和音频语言分支,分别将视频帧和音频信号转换为与llm文本输入兼容的查询表示。

video - llama结合了视频中的视觉和听觉内容,可以提高语言模型对视频内容的理解。他们提出了一个视频Q-former来捕捉视觉场景的时间变化,一个音频Q-former来整合视听信号。该模型在大量视频图像标题对和视觉指令调优数据集上进行训练,使视觉和音频编码器的输出与LLM的嵌入空间对齐。作者发现video - llama展示了感知和理解视频内容的能力,并根据视频中呈现的视觉和听觉信息产生有意义的反应。

Video-LLaMa的核心组件
1、Video Q-former:一个动态的视觉解释器
Video Q-former是video - llama框架的关键组件。它旨在捕捉视觉场景中的时间变化,提供对视频内容的动态理解。视频Q-former跟踪随时间的变化,以一种反映视频演变性质的方式解释视觉内容。这种动态解释为理解过程增加了一层深度,使模型能够以更细致入微的方式理解视频内容。
VL分支模型:ViT-G/14 + BLIP-2 Q-Former
- 引入了一个两层视频Q-Former和一个帧嵌入层(应用于每帧的嵌入)来计算视频表示。
- 在Webvid-2M视频标题数据集上训练VL分支,并完成视频到文本的生成任务。还将图像-文本对(来自LLaVA的约595K图像标题)添加到预训练数据集中,以增强对静态视觉概念的理解。
- 预训练后,使用MiniGPT-4, LLaVA和VideoChat的指令调优数据进一步微调我们的VL分支。
2、Audio Q-former:视听集成
Audio Q-former是Video-LLaMa框架的另一个重要组件。它集成了视听信号,确保模型完整地理解视频内容。Audio Q-former同时处理和解释视觉和听觉信息,增强对视频内容的整体理解。这种视听信号的无缝集成是Video-LLaMa框架的一个关键特征,它在其有效性中起着至关重要的作用。
- AL分支(音频编码器:ImageBind-Huge)
- 引入两层音频Q-Former和音频段嵌入层(应用于每个音频段的嵌入)来计算音频表示。
- 由于使用的音频编码器(即ImageBind)已经跨多个模态对齐,所以只在视频/图像指令数据上训练AL分支,只是为了将ImageBind的输出连接到语言解码器。

训练过程
模型是在视频图像标题对和视觉指令调优数据集的大量数据集上训练的。这个训练过程将视觉和音频编码器的输出与语言模型的嵌入空间对齐。这种对齐确保了高水平的准确性和理解力,使模型能够根据视频中呈现的视觉和听觉信息生成有意义的响应。
作者还提供了预训练的模型:
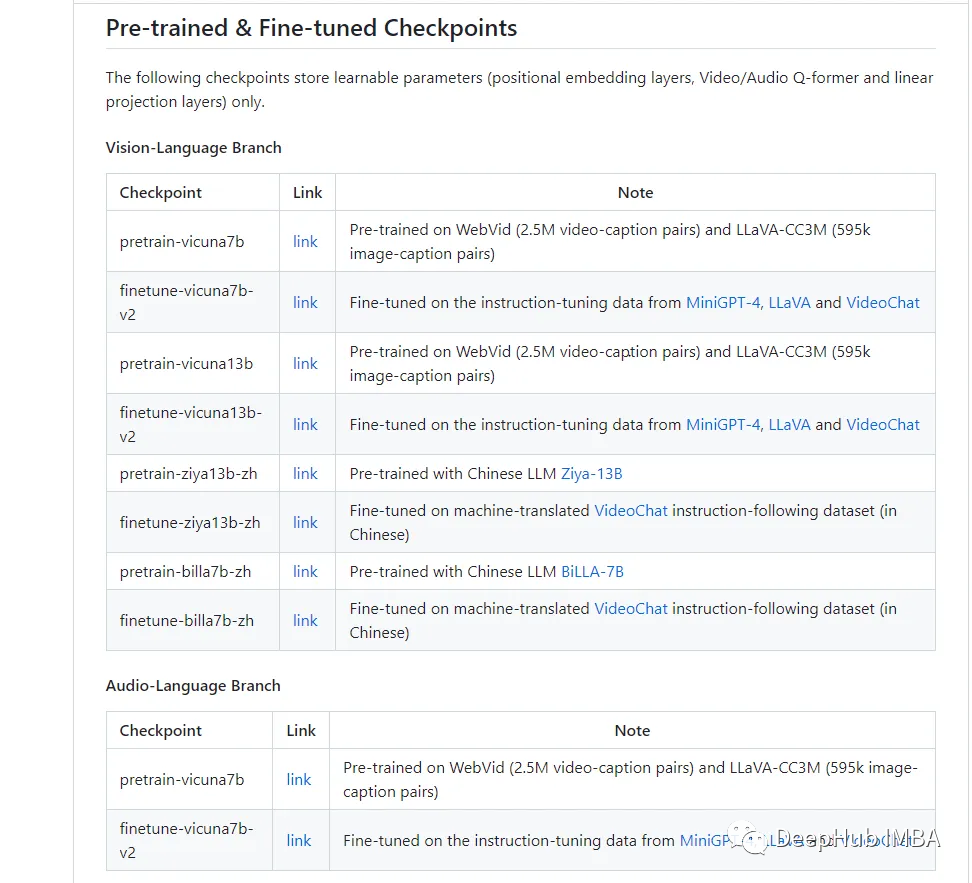
我们可以直接下载测试或者微调
影响和潜力
video - llama模型展示了一种令人印象深刻的感知和理解视频内容的能力。它基于视频中呈现的视觉和听觉信息。这种能力标志着视频理解领域的重大进步,为各个领域的应用开辟了新的可能性。

例如,在娱乐行业,Video-LLaMa可用于为视障观众生成准确的语音描述。在教育领域,它可以用来创建交互式学习材料。在安全领域,它可以用来分析监控录像,识别潜在的威胁或异常情况。
论文和源代码在这里:
https://arxiv.org/abs/2306.02858
https://github.com/damo-nlp-sg/video-llama
作者:TutorMaster