
生产环境中真正烧钱、拖慢体验的环节不是训练、是推理。自回归的方式一次只产出一个 token,每个 token 都要完整走一遍模型所有层的前向传播。70B 参数的模型在 H100 上运行,每个 token 对应 700 亿次乘累加运算,而 GPU 大部分时间都在等内存搬运数据,真正用于计算的比例很低。
这就是内存带宽墙,H100 的算力高达 990 TFLOPS,但内存带宽只有 3.35 TB/s,自回归解码时后者才是瓶颈。
投机解码在2026 年变成了工程实践中的标配。
什么是投机解码?
投机解码的出发点很简单:用一个小而快的模型去猜测大模型接下来要输出什么,而大多数时候它能猜对。
核心算法分三步。
第一步:草稿生成。一个小型草稿模型(比如 Llama-3 8B)以自回归方式快速生成 K 个候选 token。小模型只占 GPU 显存的一小部分,单 token 生成速度比大模型快约 10 倍。
第二步:验证。大型模型(Llama-3 70B)在一次前向传播中处理全部 K 个草稿 token。验证是并行的,目标模型同时为每个位置计算下一个 token 的概率分布,一次前向传播完成 K 个 token 的校验,而自回归方式需要 K 次。
第三步:接受或拒绝。逐个比较草稿模型与目标模型给出的概率分布:一致则接受,不一致则拒绝并从目标模型在该位置的分布中重新采样,同时丢弃后续所有草稿 token。
数学上有一个严格保证:输出分布与目标模型独立运行时完全一致。不是近似,是严格相同,也就是没有质量损失。
加速幅度取决于接受率。假设草稿模型 80% 的情况下与目标模型一致,每步生成 5 个草稿 token,那么每次前向传播实际验证约 4 个 token 而非 1 个,大模型的前向传播开销降到原来的四分之一。
Speedup = avg_accepted_tokens + 1/1
If acceptance_rate = 0.8 and K = 5:
avg_accepted = 0.8 * 5 = 4
speedup ~ 4x in forward passes
real-world speedup ~ 2–2.5x (accounting for draft model overhead)
SSD:Speculative Speculative Decoding
2026 年Together AI 与斯坦福联合发表了一篇论文,将投机解码从"有趣的研究技巧"推入了"生产级基础设施"的范畴。该技术名为 Speculative Speculative Decoding(SSD),针对的是原始投机解码的两个核心痛点。
第一个痛点:草稿模型的选择。原始方案需要一个与目标模型兼容的独立草稿模型,这样内存中要同时驻留两个模型,管理两组权重,还得指望二者的词表能对齐。实际操作中选择面很窄,GPU 显存也被白白占用。
第二个痛点:接受率在困难 token 上的退化。目标模型对某个 token 高度确信时(分布尖锐),草稿模型往往能猜对;但目标模型自身也不确定时(分布平坦,典型场景如创意生成),草稿模型开始大量偏离,token 接连被拒绝,加速效果随之坍塌。
SSD 分两个阶段解决这两个问题。
第一阶段:自草稿生成。SSD 不再依赖外部小模型,而是直接将目标模型的前 N 层充当草稿生成器。Llama-3 70B 的浅层网络做预测,一个用极少计算量训练出的轻量级预测头将隐藏状态映射为 token 概率,独立草稿模型由此被彻底移除。
第二阶段:带回滚树的投机验证。SSD 不再生成单一的 K-token 线性序列,而是在每个草稿位置提出 top-2 或 top-3 候选 token,构成一棵分支树。目标模型借助专门设计的注意力掩码,在一次前向传播中验证整棵树,最终取其中被接受的最长路径作为输出。
树结构对接受率有直观的提升——即使某个位置的草稿拿不准,分支中总有一条路径是对的。实测结果: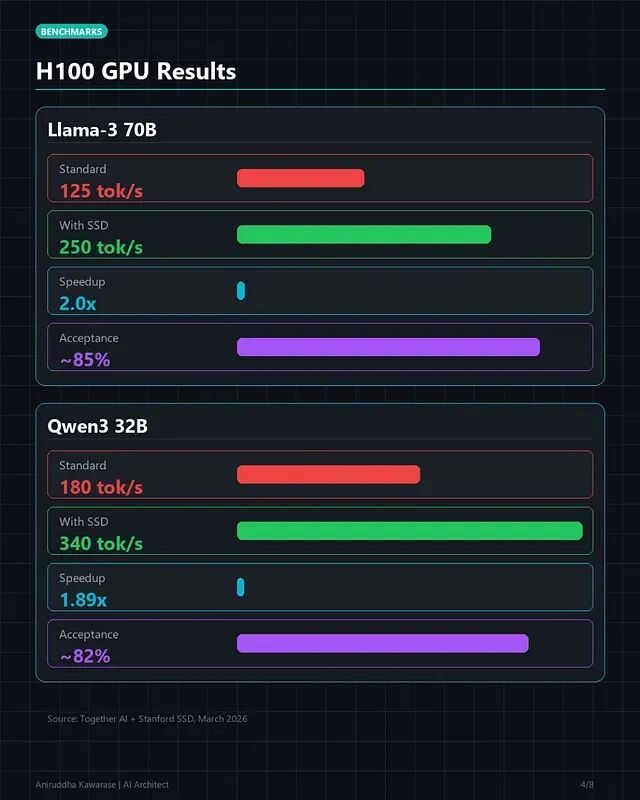
以上均为单请求吞吐量。并发场景下优势更明显:每个请求占用的 GPU 时间缩短,腾出的算力可以承载更多并发。
基准测试:真正重要的数字
下面拆解 Llama-3 70B 在单张 H100(80GB)上的实测数据——这些数字直接左右基础设施决策。
吞吐量:基线自回归解码 125 tokens/秒,启用 SSD 后 250 tokens/秒,提升 2.0 倍。
首 token 延迟(TTFT):基线 180ms(含 prompt 处理与首 token 生成),SSD 下 195ms,因树结构初始化略有增加。
内存开销:基线 68.2 GB(模型权重 + KV 缓存),SSD 下 71.4 GB(多出预测头与树缓冲区),增量 3.2 GB(4.7%),H100 的 80GB 显存完全装得下。
按任务类型看接受率和实际加速:
| Task | Acceptance Rate | Effective Speedup |
| — — — | — — — — — — — — | — — — — — — — — — -|
| Code generation | 87% | 2.3x |
| Translation | 82% | 2.0x |
| Summarization | 79% | 1.9x |
| Creative writing | 68% | 1.6x |
| Math reasoning | 72% | 1.7x |
代码生成加速最为突出,原因在于代码的可预测性高——语法结构、常见模式、样板代码都在草稿模型的舒适区内。创意写作加速最低,token 层面的不确定性本身就大。
放到实际尺度来看:每天在 H100 上处理 1000 万 token 的服务,基线方案需要 4 张 GPU 才能在负载下维持 200ms 以内的 TTFT,SSD 只需 2 张就能满足同样的 SLA。按按需云定价折算,年度节省约 150,000 美元。
实现:vLLM 中的投机解码
vLLM 在 v0.7 中加入了生产级投机解码支持,v0.8 进一步引入 SSD 风格的自草稿生成。以下是具体配置方式。
基础投机解码(独立草稿模型):
from vllm import LLM, SamplingParams
# 使用投机解码初始化
llm = LLM(
model="meta-llama/Llama-3-70B-Instruct",
speculative_model="meta-llama/Llama-3-8B-Instruct",
num_speculative_tokens=5, # 每步草稿生成 5 个 token
tensor_parallel_size=4, # 将 70B 模型分片到 4 个 GPU
gpu_memory_utilization=0.90,
dtype="float16",
)
sampling_params = SamplingParams(
temperature=0.7,
top_p=0.9,
max_tokens=2048,
)
prompts = [
"Explain the PagedAttention algorithm in detail.",
"Write a Python function to merge two sorted linked lists.",
"Summarize the key findings of the 2026 State of AI report.",
]
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
generated_text = output.outputs[0].text
num_tokens = len(output.outputs[0].token_ids)
print(f"Generated {num_tokens} tokens")
print(generated_text[:200])
print("---")
SSD 风格自草稿生成(单模型)
from vllm import LLM, SamplingParams
# 自投机解码——不需要独立的草稿模型
llm = LLM(
model="meta-llama/Llama-3-70B-Instruct",
speculative_model="[self]", # 使用前几层作为草稿
speculative_draft_tensor_parallel_size=1,
num_speculative_tokens=5,
speculative_max_model_len=4096,
tensor_parallel_size=4,
gpu_memory_utilization=0.92,
dtype="float16",
)
sampling_params = SamplingParams(
temperature=0.0, # 贪心解码以获得最高接受率
max_tokens=2048,
)
# 批处理——投机解码真正大放异彩的地方
prompts = load_prompts_from_queue() # 你的提示批次
outputs = llm.generate(prompts, sampling_params)
使用 OpenAI 兼容 API 提供服务
# 使用投机解码启动 vLLM 服务器
# 在终端或部署脚本中运行:
# vllm serve meta-llama/Llama-3-70B-Instruct \
# --speculative-model meta-llama/Llama-3-8B-Instruct \
# --num-speculative-tokens 5 \
# --tensor-parallel-size 4 \
# --port 8000
# 然后像使用任何 OpenAI 兼容 API 一样调用它:
import openai
client = openai.OpenAI(
base_url="http://localhost:8000/v1",
api_key="not-needed",
)
response = client.chat.completions.create(
model="meta-llama/Llama-3-70B-Instruct",
messages=[
{"role": "user", "content": "Explain speculative decoding."}
],
max_tokens=1024,
temperature=0.7,
stream=True,
)
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
vLLM 的实现对 API 调用侧完全透明——现有的 OpenAI 兼容客户端代码不需要任何改动,加速全部发生在服务端。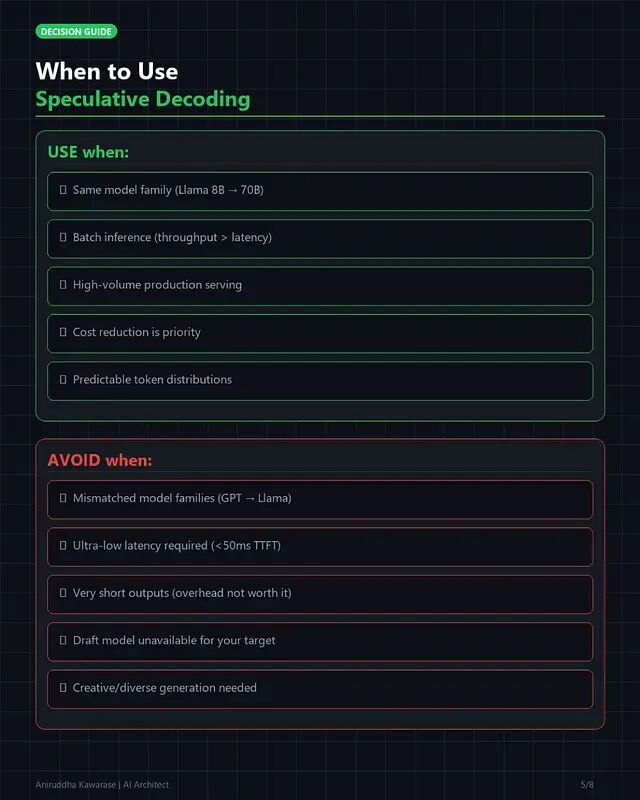
何时使用投机解码
投机解码并非适用于所有场景。
接受率最高的前提是草稿模型与目标模型出自同一家族——Llama-3 8B 配 Llama-3 70B 效果理想,二者共享训练数据和分词器;跨家族搭配如 Mistral 配 Llama 则接受率低不少。批量推理流水线从中获益最多,RAG、摘要、数据提取这类大量 prompt 并行处理的场景下,2 倍吞吐量直接换算为一半的时耗和 GPU 开支。采样策略上贪心解码或低温度最为有利,temperature 越低、目标分布越集中,草稿命中概率越高。GPU 显存需要留出 5%–10% 的余量来装载草稿模型或预测,因为利用率已在 95% 以上的环境可能触发 OOM。
而下面几类场景应当规避。对 TTFT 有硬性要求的实时对话(SLA < 100ms)中,树初始化带来的 10–20ms 额外开销不可忽视。高温度创意生成(temperature > 1.0)下输出分布过于平坦,接受率跌到 60% 以下,加速收益被草稿开销抵消。跨家族模型搭配因训练分布差异过大,接受率撑不起加速。输出很短的任务(< 50 tokens)——分类、简短问答——初始化开销来不及摊薄。显存已满的环境同样不适用,70B 模型在 80GB 上本就吃紧,再加草稿模型只会溢出。
总结
投机解码已经从论文走进了生产系统,自草稿生成解决了草稿模型的管理负担。SSD 直接复用目标模型前几层做草稿,内存里只驻留一个模型、维护一组权重,加速效果不打折扣。
投机解码是投入产出比最高的一项优化:配好 vLLM,打开开关,吞吐量翻倍。
by Aniruddha Kawarase