
生产里真正有分量的工作流是能批量处理几千份保险理赔、跑完一周的销售触达节奏、跨系统对账等等的复杂工作,而这些是没办法塞进一次对话轮次里。因为他们的处理时间以天为单位,而不是秒。
一旦动手做这类长时运行的 agent,会遇到一个问题:大多数 agent 架构本质上是无状态的,每次交互都从数据库里把 context 重新拼回来。拼回来的过程中推理链丢了,软信号也丢了,那些让前一步决策看起来合理的置信度梯度也丢了。
Cloud Next 26 上 Google 宣布 Agent Runtime 开始支持长时运行 agent,状态可以维持七天。围绕这次发布,本文整理出五种把生产系统和脆弱 demo 区分开来的设计模式。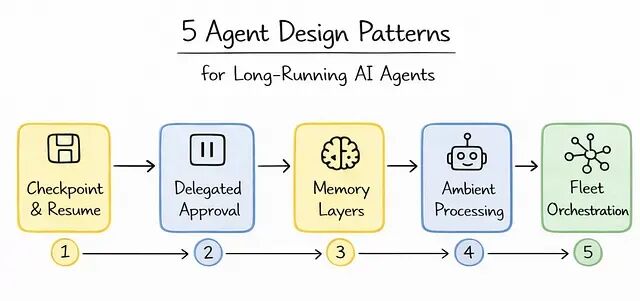
Fleet Orchestration
跨天工作流里最常见的崩盘方式就是 context 丢失。一个 agent 花四个小时处理 400 份文档,跑到第 301 份时报错——没有 checkpointing,整个流程要从零再来。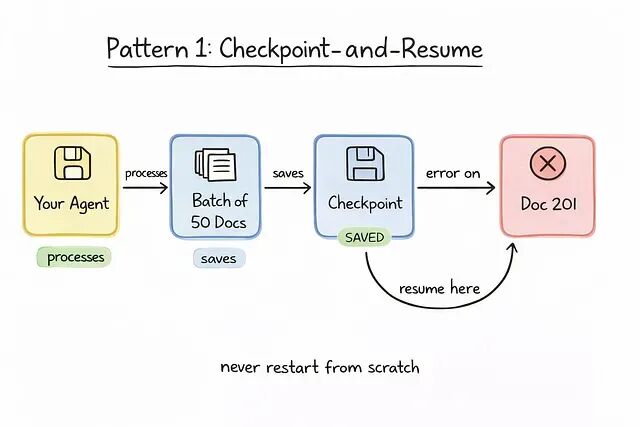
长时运行 agent 必须把执行状态持久化到一个安全的 cloud sandbox 里。agent 拥有 bash 命令权限和一个沙箱化的文件系统,所以可以把中间结果落到磁盘,把处理日志写下来这样故障时也能体面地恢复。
所以这里就需要把 agent 当成一个长期跑着的服务进程,而不是一次请求处理函数。就像写一条要吞掉几百万条记录的数据管道——进度要 checkpoint,部分失败要兜住,幂等性要保证。
每 30 份文档落一次盘,是在持久性和计算开销之间一个比较舒服的折中。出错时agent 直接从最近一次保存的状态接着跑。
# Pattern 1: Checkpoint-and-Resume
def process_documents(docs, checkpoint_file="state.json"):
state = load_checkpoint(checkpoint_file) or {"processed": 0, "results": []}
for i in range(state["processed"], len(docs)):
try:
result = agent.analyze(docs[i])
state["results"].append(result)
state["processed"] = i + 1
# 每 30 份文档执行一次 checkpoint
if (i + 1) % 30 == 0:
save_checkpoint(checkpoint_file, state)
except Exception as e:
save_checkpoint(checkpoint_file, state) # 在崩溃前保存
raise e
return state["results"]
Delegated Approval(Human-in-the-Loop)
几乎每个框架都在宣传自己支持 human-in-the-loop。但落到实现层面,多数版本都很糙:把状态序列化成 JSON,发一个 webhook 出去,剩下的就指望有人会去看。
问题会越积越多。
JSON 序列化会丢掉那些隐式的推理 context;通知则要和几十条其他告警一起抢眼球。等到几小时后终于有人回过头来响应,agent 又得反序列化、重建 context,并默认期间一切照旧——这是个非常脆弱的假设。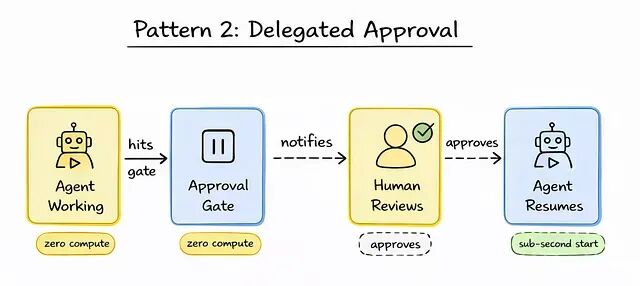
长时运行 agent 的处理方式不一样。走到审批节点时,它就在原地暂停。整套执行状态完整保留下来:推理链、工作记忆、tool call 历史、待执行的动作,全都不动。
关键在于资源效率。agent 等 24 小时让人来点 Approve,这 24 小时对 agent 是死时间,对人是工作时间。暂停期间 agent 不消耗任何计算;亚秒级冷启动让恢复几乎没有延迟代价。
# Pattern 2: Delegated Approval
@agent.tool
def request_human_approval(action_plan: dict, context: str):
"""暂停 agent 执行并请求人类审核。"""
approval_id = db.create_approval_request(
plan=action_plan,
context=context,
status="pending"
)
# 将执行控制权交还给 orchestrator
# 在 webhook 触发之前,agent 消耗 0 计算资源
raise SuspendExecution(
reason="human_approval_required",
resume_webhook=f"/api/resume/{approval_id}"
)
Memory-Layered Context
跑七天的 agent 需要的远不止 session 状态。它得记住前几次 session 里的东西、几周前用户留下的偏好,以及那些任何单次对话都装不下的组织信息。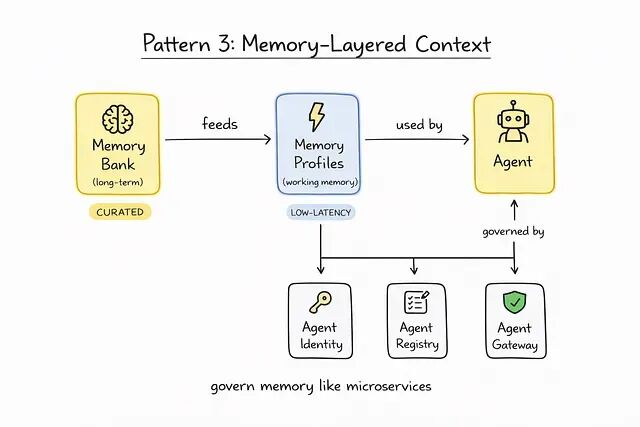
Memory-Layered Context 把长期存储和工作记忆拆开,由严格的策略来管。
分层记忆在这里就变成必需品。一边是 Memory Bank——长期记忆,动态地把对话整理沉淀下来;一边是 Memory Profiles——工作记忆,专门服务那些低延迟、高准确度的细节查询。
但其中藏着一个坑:记忆漂移。agent 从少数几次非典型交互里"学到"某个程序性捷径可以接受,接下来可能就把这个捷径泛化到所有场景。多个 agent 共用同一个记忆池时,数据泄漏也是个真实存在的风险。
不能放任 agent 随便往向量数据库里写东西。治理它们的方式应当和治理 microservices 一样,由三个核心组件支撑:
Agent Identity:相当于 agent 的 IAM,决定它能访问哪些 memory bank 和 tool。
Agent Registry:相当于服务发现,记录哪些 agent 在跑、它们的 prompt 版本是哪一版、当前处于什么执行状态。
Agent Gateway:相当于 API gateway,根据组织策略评估每一次请求——比如阻止 agent 把 PII 写入长期记忆。
# Pattern 3: Memory-Layered Context
class AgentGateway:
def __init__(self, identity_provider, policy_engine):
self.iam = identity_provider
self.policies = policy_engine
def write_to_memory_bank(self, agent_id, data):
# 1. 验证身份
if not self.iam.can_write(agent_id, "long_term_memory"):
raise UnauthorizedError()
# 2. 执行策略(例如 PII 脱敏)
safe_data = self.policies.redact_pii(data)
# 3. 写入受管理的存储
vector_db.upsert(
collection="memory_bank",
metadata={"source_agent": agent_id},
content=safe_data
)
Ambient Processing
不是所有长时运行 agent 都和人类有交互。还有一类是 ambient 的:盯着事件、消费数据流、在后台直接动手,全程不需要任何用户提示。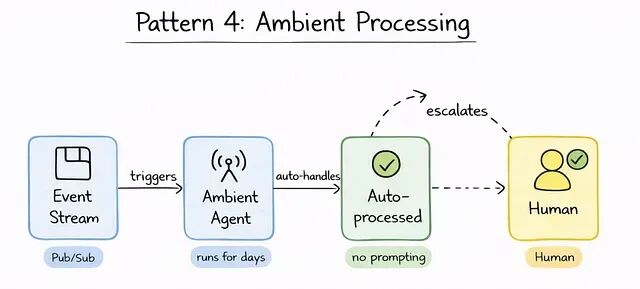
Ambient Processing 让 agent 在无人值守状态下持续运行,按事件触发动作。
举个例子:一个直接挂在
Pub/Sub
流上的内容审核 agent。它会跑上好几天,处理源源不断进来的用户内容,自己维护一份关于趋势和模式的状态,只在确实需要时才升级给人类。
这里最关键的架构决定又回到治理上。内容策略不应该被硬编码进 agent 本身,而应该在 Agent Gateway 里定义。策略一变,只更新一次 Gateway,整个 fleet 的 ambient agent 立刻拿到新规则。
# Pattern 4: Ambient Processing
async def ambient_moderation_agent(pubsub_stream):
"""持续运行,对事件做出反应而无需提示。"""
async for event in pubsub_stream.listen("user_content"):
# agent 自主评估内容
analysis = await agent.evaluate(event.text)
if analysis.flagged:
if analysis.confidence > 0.95:
# 高置信度时自动处理
await api.ban_user(event.user_id)
else:
# 升级边缘案例
await request_human_approval(
action_plan={"action": "ban", "user": event.user_id},
context=analysis.reasoning
)
Fleet Orchestration
生产里很少出现一个 agent 单打独斗的情况。常见的形态是:一个 coordinator agent 把子任务分派给若干 specialist agent,每个 specialist 独立运行,时长各不相同。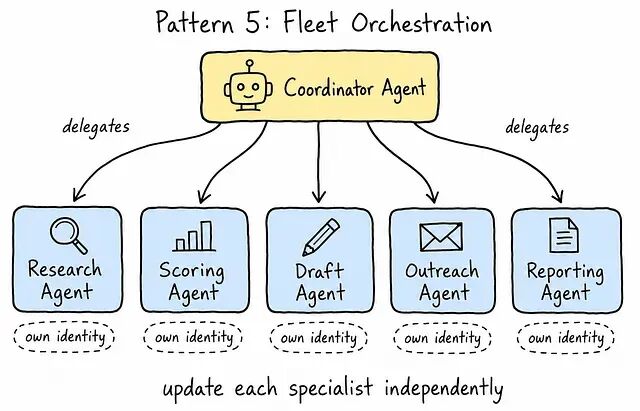
Fleet Orchestration 用一个 coordinator 来统筹一群独立的 specialist agent。
拿销售开发流程举例:Coordinator Agent 把工作分给五个 specialist:Research Agent 负责收集每个 lead 的公开数据;Scoring Agent 按匹配度和意图信号给 lead 打分排序;Draft Agent 写出第一封个性化消息;Outreach Agent 选合适的渠道把消息发出去;Reporting Agent 收尾,把整轮跑完后的结果汇总。
每个 specialist 拥有独立的 Agent Identity,因此只能访问自己需要的资源;通过 Agent Gateway 走自己的策略校验;在 Agent Registry 里有独立条目。Coordinator Agent 维护全局状态,处理 specialist 之间的交接。
把每个 specialist 当成独立单元,一个直接的好处是更新可以分开做。Scoring Agent 的排序逻辑要改进,发新版本上去就行,不会牵连到 fleet 里的其他成员。
# Pattern 5: Fleet Orchestration
async def coordinator_agent(lead_list):
results = []
for lead in lead_list:
# 1. Research Agent — 收集 lead 的公开数据
research = await fleet.call("research_agent", target=lead)
# 2. Scoring Agent — 根据匹配度和意图信号对 lead 排名
score = await fleet.call("scoring_agent", data=research)
if score > 80:
# 3. Draft Agent — 撰写个性化的首条消息
draft = await fleet.call("draft_agent",
context=research,
tone="professional")
# 4. Outreach Agent — 通过合适的渠道发送消息
await fleet.call("outreach_agent",
lead=lead,
message=draft)
results.append({"lead": lead, "score": score, "draft": draft})
# 5. Reporting Agent — 总结整个运行过程
await fleet.call("reporting_agent", summary=results)
总结
这五种模式反映的是 AI agent 在真实世界里运转方式的一次推进。它们也直接对应着 agentic AI 的下一次转向——agent 不再只是被动响应,而是能够持续存在、自我治理、规模化协同。
底层原则其实很简单:结构化、有状态、被治理的执行,比无状态的请求-响应循环是更基础。
把确定性的 checkpointing 和概率性的推理拆开;用原地暂停取代序列化成 JSON 再恢复;让记忆通过身份和策略来约束,而不是盲目信任 agent 的写入行为——做到这几点,工作流里的推理链就能被保留下来,必要时还能复原。
agent 本身就是进程。其余的都是脚手架。
生产级 AI 不是单轮里把 agent 调得多聪明,而是看它能否在很多轮、很多天、很多次交接之间保持可靠。把已知和推断区分清楚的团队,以及一开始就把治理嵌进系统而不是事后再补的团队,会决定公司未来怎么用 AI。
作者:Ana Bildea, PhD