
RAG 流水线部署完毕、检索正常运行、LLM 按部就班地生成回答、用户也在持续收到响应,这一切看上去运转良好。但有一个问题大多数工程师从来不问:这些回答真的对吗?
不是"系统是否返回了响应",而是"响应的内容是否正确"。
如果答案是"上线前测过"或者"余弦相似度分数没问题",那么一个静默故障问题大概率正在生产环境中发生。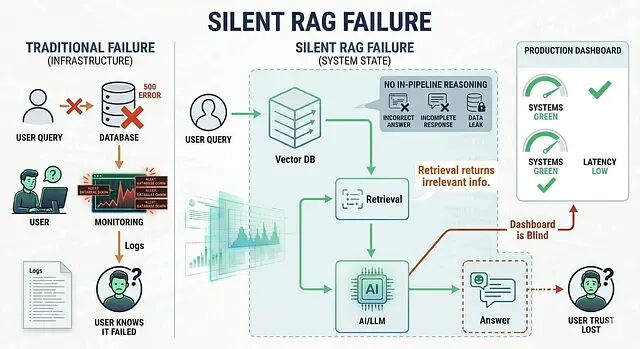
静默 RAG 故障
下面这种故障模式是不会出现在你的日志里的,用户提交一条查询、检索流水线运行并返回若干文本块、相似度分数看起来正常、LLM 据此生成了一段流畅的响应,但响应存在事实偏差或者以高度自信的口吻呈现了不完整的信息。这中抢矿不会异常抛出,也没有告警触发,而且没有 trace 将其标记为异常。系统继续运行用户也继续带着一份错误的信息离开。
这就是静默 RAG 故障,监控的每一个指标系统都"正常工作"了,按照真正重要的指标衡量,但是用户拿到的是一个错误答案。
根源分析:三个缺口
要了解原因需要先要看清标准 RAG 流水线中缺口出现在哪些环节。
缺口 1:检索质量 ≠ 检索相关性
余弦相似度衡量的是两个向量在嵌入空间中的距离。它不是对"检索到的文本块能否回答问题"的度量。
比如说,用户提问"Drug X 对肾病患者的禁忌症有哪些?",向量存储返回了一段关于 Drug X 一般作用机制的文本块,相似度分数 0.87。主题确实相关,分数确实好看,但这段文本并不包含禁忌症信息。LLM 需要基于一段不含目标信息的上下文来回答关于禁忌症的问题。大多数情况下它会做什么?用外推填补空白,并且在填补的过程中语气非常自信。
这样检索得分高,但是答案是错的。
缺口 2:LLM 的流畅性掩盖了不确定性
大语言模型在生成流畅、语气确定的文本方面能力极强——哪怕背后缺乏充分的信息支撑。这不是缺陷而是训练目标决定的行为模式。
上下文不足以回答问题时,模型很少说"我不知道"。它更倾向于将手头已有的片段拼凑成一段看似合理的回答:读起来像正确答案,结构上像正确答案,只是内容并不准确。生成环节之上如果没有叠加评估层,这类情况无从捕获。
缺口 3:故障信号未被收集
RAG 出错时用户其实在反馈,只是不是通过文字。他们会重新措辞同一个问题再问一遍,会点击"踩"或负面评价按钮,会提出一个暗示前一个答案有误的追问,或者干脆停止使用该功能。
这些信号如果没有被记录和标记,等于坐在一座评估数据的矿上而浑然不觉。
真正奏效的方案:构建反馈循环
以下是在生产 RAG 系统中实际使用的可观测性与评估架构。
1、生成前的相关性门控
不要让 LLM 基于低质量上下文生成回答。在检索与生成之间设置一道门控,校验检索到的文本块是否确实能回应查询。
from anthropic import Anthropic
client = Anthropic()
def relevance_gate(query: str, chunks: list[str], threshold: float = 0.7) -> bool:
"""
在将文本块传递给生成之前,验证它们是否确实相关。
如果文本块足以回答查询,则返回 True。
"""
context = "\n\n".join(chunks)
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=100,
messages=[{
"role": "user",
"content": f"""Given this query: "{query}"
And these retrieved chunks:
{context}
Do these chunks contain sufficient information to answer the query accurately?
Respond with only: SUFFICIENT or INSUFFICIENT"""
}]
)
result = response.content[0].text.strip()
return result == "SUFFICIENT"
def rag_with_gate(query: str, retrieved_chunks: list[str]) -> str | None:
if not relevance_gate(query, retrieved_chunks):
# 记录故障,触发重新检索或升级处理
log_retrieval_failure(query, retrieved_chunks)
return None # 不从质量差的上下文中生成
return generate_response(query, retrieved_chunks)
仅这一步就能在回答到达用户之前拦截相当比例的静默故障。
2、生成后的自评估
相关性门控到位之后,仍有部分低质量生成会通过。在生成环节之后追加第二道评估:
def evaluate_response(query: str, context: str, response: str) -> dict:
"""
在生成之后,评估响应是否基于上下文。
返回包含推理过程的评估结果。
"""
eval_prompt = f"""You are evaluating the quality of an AI-generated response.
Query: {query}
Context provided to the model:
{context}
Generated response:
{response}
Evaluate the response on two criteria:
1. GROUNDED: Is every claim in the response directly supported by the context? (yes/no)
2. COMPLETE: Does the response fully address the query using the available context? (yes/no)
Respond in this exact format:
GROUNDED: yes/no
COMPLETE: yes/no
REASONING: one sentence explanation"""
result = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=200,
messages=[{"role": "user", "content": eval_prompt}]
)
return parse_eval_result(result.content[0].text)
def parse_eval_result(text: str) -> dict:
lines = text.strip().split('\n')
return {
'grounded': 'yes' in lines[0].lower(),
'complete': 'yes' in lines[1].lower(),
'reasoning': lines[2].replace('REASONING: ', '') if len(lines) > 2 else ''
}
grounded
为 False,说明响应中存在幻觉性论断,不应返回给用户。
complete
为 False,说明上下文不够充分,需要记录并考虑用更宽泛的查询重新检索。
3、以 Session ID 贯穿全链路追踪
经过 RAG 流水线的每一条查询都应当生成一份 trace——不只是最终响应,而是每一个中间步骤。
import uuid
from datetime import datetime
from dataclasses import dataclass, field
@dataclass
class RAGTrace:
session_id: str = field(default_factory=lambda: str(uuid.uuid4()))
timestamp: str = field(default_factory=lambda: datetime.utcnow().isoformat())
query: str = ""
retrieved_chunks: list[dict] = field(default_factory=list)
retrieval_scores: list[float] = field(default_factory=list)
relevance_gate_passed: bool = False
generated_response: str = ""
eval_grounded: bool = False
eval_complete: bool = False
final_returned: bool = False
failure_reason: str = ""
def traced_rag_pipeline(query: str) -> tuple[str | None, RAGTrace]:
trace = RAGTrace(query=query)
# 检索
chunks, scores = retrieve(query)
trace.retrieved_chunks = chunks
trace.retrieval_scores = scores
# 相关性门控
gate_passed = relevance_gate(query, chunks)
trace.relevance_gate_passed = gate_passed
if not gate_passed:
trace.failure_reason = "relevance_gate_failed"
trace.final_returned = False
persist_trace(trace)
return None, trace
# 生成
response = generate_response(query, chunks)
trace.generated_response = response
# 评估
eval_result = evaluate_response(query, "\n".join(chunks), response)
trace.eval_grounded = eval_result['grounded']
trace.eval_complete = eval_result['complete']
if not eval_result['grounded']:
trace.failure_reason = "hallucination_detected"
trace.final_returned = False
persist_trace(trace)
return None, trace
trace.final_returned = True
persist_trace(trace)
return response, trace
出了问题时,打开对应 Session ID 的 trace,一眼就能定位故障发生在哪个环节——检索、门控、生成还是评估。排查时间从几小时缩短到几分钟。
4、把用户行为转化为评估数据
用户行为是最诚实的信号源。把它接入系统:
def log_user_signal(session_id: str, signal_type: str, metadata: dict = {}):
"""
signal_type 选项:
- 'thumbs_down'
- 'rephrased_query' # 同一用户,2分钟内的相似查询
- 'follow_up_correction' # 后续问题暗示第一个答案是错的
- 'no_engagement' # 响应已展示但用户立即离开
"""
signal = {
"session_id": session_id,
"signal_type": signal_type,
"timestamp": datetime.utcnow().isoformat(),
**metadata
}
# 持久化到评估数据库
persist_failure_signal(signal)
# 将原始 trace 标记为故障
update_trace_failure_flag(session_id, signal_type)
定期对标记过的 trace 做复盘,寻找规律:故障是否集中在某个特定主题或文档类型?某些查询模式是否反复无法通过相关性门控?向量存储中的某份文档是否产生了不成比例的失败率?
这才是闭环,基于真实用户故障来调优检索策略,而非依赖合成基准测试。
整体架构一图总览
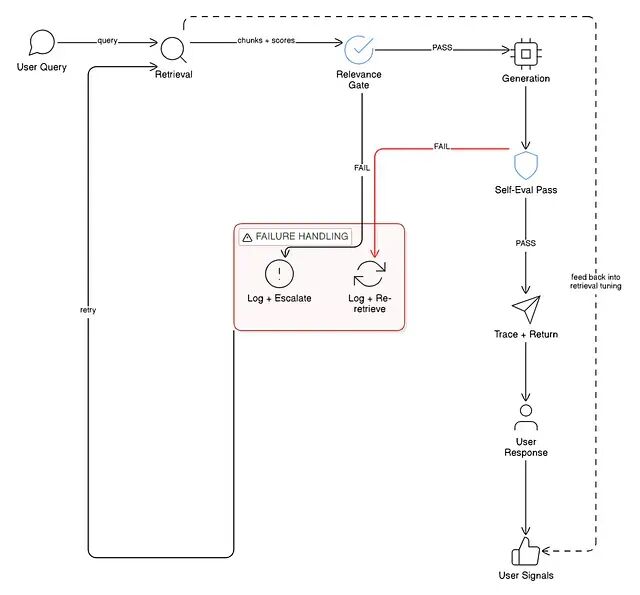
加上这一层之前,监控范围局限于:系统是否返回了响应、延迟是否可接受、是否发生了错误。
加上这一层之后,监控的维度变成了:检索到的上下文是否确实与查询相关,生成的响应是否有上下文依据,用户后续行为是否暗示答案有误,以及这条具体查询在哪个环节出了问题。
前者交付的是一个黑盒,后者交付的是一个可以被信任的系统。差别在此。
总结
RAG 的搭建门槛不高。嵌入、检索、生成——基础流水线一个下午就能跑通。
但要让一个 RAG 系统在生产环境中达到可信赖的程度,所需时间远不止于此。原因不在于技术组件本身有多复杂,而在于绝大多数团队直接跳过了可观测性这一层。本地测试通过,效果看起来没问题,直接上线。
之后它就开始静默地失败。数周,数月,无人察觉。
检索流水线对用户不可见。
错误答案对用户可见。
by Sai Akash Avunoori