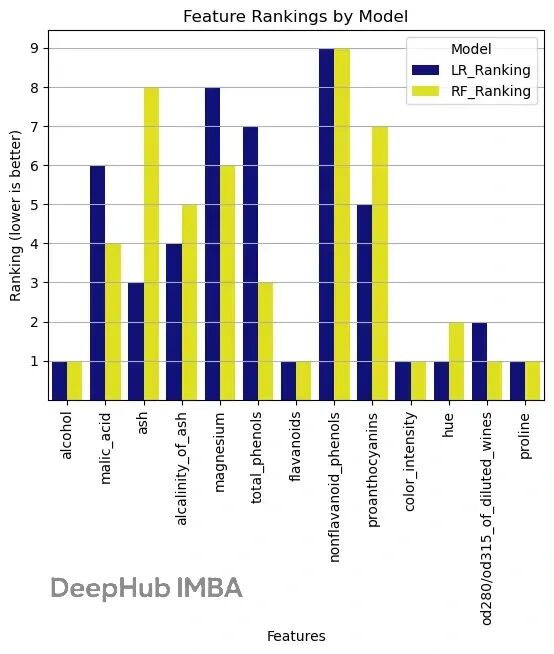
sklearn 特征选择实战:用 RFE 找到最优特征组合
本文会详细介绍RFE 的工作原理,然后用 scikit-learn 跑一个完整的例子。
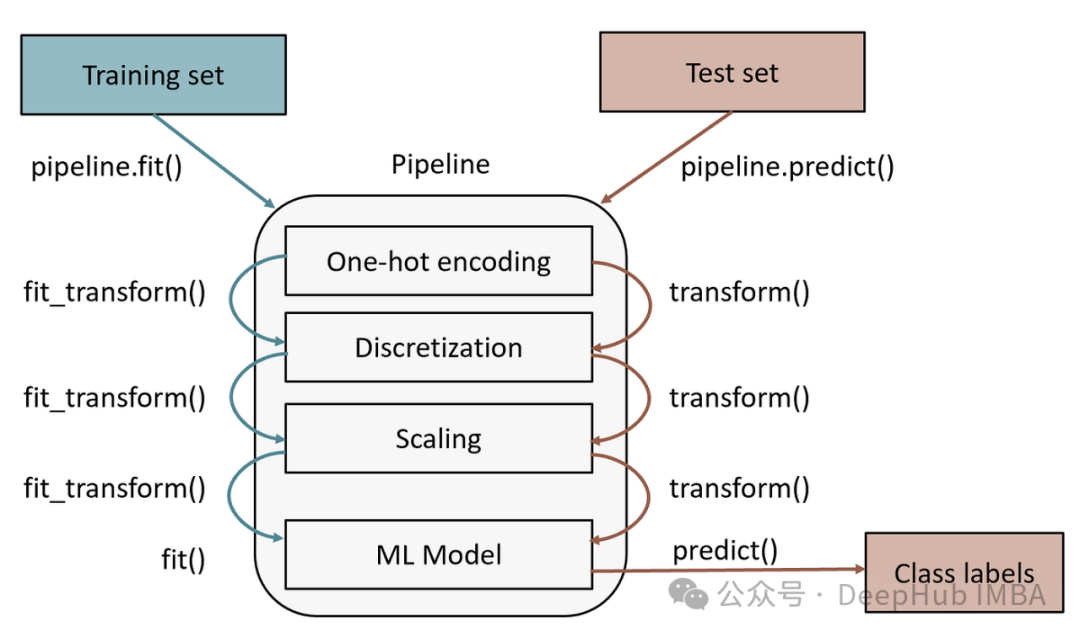
Scikit-learn Pipeline完全指南:高效构建机器学习工作流
在机器学习工作流程中,组合估计器通过将多个转换器(Transformer)和预测器(Predictor)整合到一个管道(Pipeline)中,可以有效简化整个过程。
CatBoost原生接口和Sklearn接口参数详解
CatBoost原生接口和Sklearn接口参数详解
人工智能学习笔记(1):了解sklearn
摘要:Sklearn是一个基于Python语言的开源机器学习库。全称Scikit-Learn,是建立在诸如NumPy、SciPy和matplotlib等其他Python库之上,为用户提供了一系列高质量的机器学习算法
特征正交化:用sklearn打造无偏特征空间
特征正交化是提高机器学习模型性能的重要技术。通过使用sklearn中的PCA、SVD和随机投影等方法,我们可以有效地消除特征间的相关性,构建一个无偏的特征空间。然而,正交化过程也需要权衡信息丢失和计算成本。本文的介绍和代码示例为读者提供了一种系统的方法来理解和应用特征正交化技术。在实际应用中,选择合
人工智能之数据科学库sklearn
sklearn,全称scikit-learn,是python中的机器学习库,建立在numpy、scipy、matplotlib等数据科学包的基础之上,涵盖了机器学习中的样例数据、数据预处理、模型验证、特征选择、分类、回归、聚类、降维等几乎所有环节,功能十分强大
人工智能-常见模型评估(基于sklearn实现)
模型评估是模型开发过程不可或缺的一部分。它有助于发现表达数据的最佳模型和所选模型将来工作的性能如何。按照数据集的目标值不同,可以把模型评估分为分类模型评估和回归模型评估。
未来科技的前沿:深入探讨人工智能的进展、机器学习技术和未来趋势
本文全面回顾了人工智能(AI)的发展历程,从早期概念到今日的先进应用,特别关注机器学习、深度学习和神经网络等关键技术。文章首先定义了AI,阐述了其模仿人类认知功能的核心目的,并透视了AI如何通过学习和适应,不断提升处理复杂任务的能力。随后,文中深入讨论了AI技术的主要分支,包括其工作原理、主要工具及
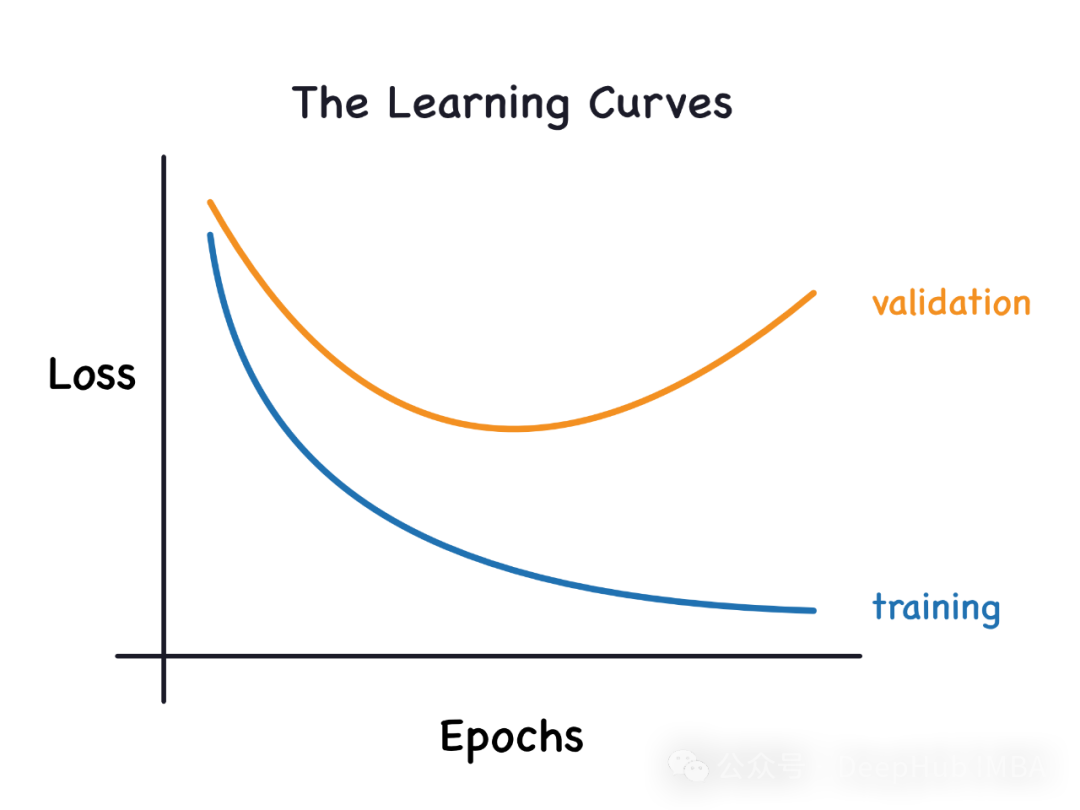
通过学习曲线识别过拟合和欠拟合
本文将介绍如何通过学习曲线来有效识别机器学习模型中的过拟合和欠拟合。
关于Pycharm无法安装sklearn库问题
pycharm里面如果要安装sklearn库的话是需要搜索sklearn库的全称scikit-learn的。但如果仍安装失败,可能就是pip版本的问题(我的就是这样)。解决方法:首先要升级安装pip版本,方法是打开cmd,输入:python -m pip install --upgrade pip。
Pycharm安装sklearn后,仍然报错No module named ‘sklearn‘
Pycharm安装sklearn后,仍然报错No module named 'sklearn'
【版本安装】最新版本|还在开发的版本sklearn安装方式
对于有些还处在开发版本的库,我们是无法通过简单的pip调用的,比如sklearn的所有版本(2022.10.30)如下:
使用sklearn-SGDClassifier分类mnist数据集中‘5‘,并使用交叉验证评估模型
random_state参数是许多算法中用于控制随机数生成的种子值的一个常见参数。通过设置random_state为一个固定的整数值,可以确保代码的随机性部分是可重复的,这意味着每次运行代码时,如果输入数据不变,使用相同的random_state值将得到完全相同的结果。1. 下图报错也许是因为尝试使
sklearn学习的一个例子用pycharm jupyter
运行在jupyter 进行开发。即一个WEB端的开发工具。能适时显示开发的输出。后缀用的是ipynb.pycharm也可以支持。但也要提示按装jupyter.这里我们用pycharm进行项目创建。创建一个jupyter的文件。或直接用andcoda。
sklearn 中皮尔森相关性。
【代码】sklearn 中皮尔森相关性。
交叉验证的种类和原理(sklearn.model_selection import *)
前提:假设某些数据是独立且相同分布的 (i.i.d.),假设所有样本都源于同一个生成过程,并且假设生成过程没有对过去生成的样本的记忆。注意:虽然i.i.d.数据是机器学习理论中的常见假设,但在实践中很少成立。如果知道样本是使用瞬态过程生成的,则使用时间序列感知交叉验证方案会更安全(例一)。同样,如果
sklearn笔记:AgglomerativeClustering
n_clusters需要分成几个cluster?如果distance_threshold不是None,那么n_clusters需要是None'metric计算距离的方式可以是‘euclidean’,‘l1','l2','manhattan','cosine','precomputed'如果设置为No
from sklearn.externals import joblib导入报错
而因为python版本变动较为频繁,导致sklearn包在使用上,与各个版本会出现版本不协调情况。在 Sklearn 里面有六大任务模块:分别是分类、回归、聚类、降维、模型选择和预处理。sklearn是机器学习初学者在机器学习时使用的最重要的一个包。所以直接复制粘贴的import代码有小概率会有报错
机器学习 | sklearn库
本篇文章主要讲解对所给数据集进行机器学习之前的样本划分、数据预处理、数据降维等知识点与可视化和python实现



