
使用scikit-learn为PyTorch 模型进行超参数网格搜索
scikit-learn是Python中最好的机器学习库,而PyTorch又为我们构建模型提供了方便的操作,要让PyTorch 模型可以在 scikit-learn 中使用的一个最简单的方法是使用skorch包
PCA降维原理 操作步骤与优缺点
PCA全称是Principal Component Analysis,即主成分分析。它主要是以“提取出特征的主要成分”这一方式来实现降维的。 介绍PCA的大体思想,先抛开一些原理公式,如上图所示,原来是三维的数据,通过分析找出两个主成分PC1和PC2,那么直接在这两个主成分的方向上就可以形成一个平面
初学者安装Sklearn详细步骤(有详细步骤截图,亲测完成)
一、安装前的准备1.1 安装python(我安装的是最新版3.10.2)1.2 Win 10 操作系统二、正式安装(Win+R --> 'cmd'进入命令提示符 也就是终端)在安装sklearn之前,需要安装两个库,即numpy+mkl和scipy。但是最好不要使用pip3直接在终端安装,因为
降维干货,一种用于处理特征的方式——后附Python代码例子
读了周志华老师写得《机器学习》降维的一部分知识后还是觉得这一部分有一点不一样的感悟,感觉很多情况下在数据分析时都可以用到,而且现在操作也非常简单,只需要调用sklearn库中函数即可,可以让大家快速上手使用
PCA(主成分分析法)的Python代码实现(numpy,sklearn)
PCA(主成分分析法)的Python代码实现(numpy,sklearn)语言描述算法描述示例1 使用numpy一步一步按算法降维 2 直接使用sklearn中的PCA进行降维语言描述PCA设法将原来众多具有一定相关性的属性(比如p个属性),重新组合成一组相互无关的综合属性来代替原属性。通常数学上的
PCA降维原理 操作步骤与优缺点
PCA全称是Principal Component Analysis,即主成分分析。它主要是以“提取出特征的主要成分”这一方式来实现降维的。 介绍PCA的大体思想,先抛开一些原理公式,如上图所示,原来是三维的数据,通过分析找出两个主成分PC1和PC2,那么直接在这两个主成分的方向上就可以形成一个平面
初学者安装Sklearn详细步骤(有详细步骤截图,亲测完成)
一、安装前的准备1.1 安装python(我安装的是最新版3.10.2)1.2 Win 10 操作系统二、正式安装(Win+R --> 'cmd'进入命令提示符 也就是终端)在安装sklearn之前,需要安装两个库,即numpy+mkl和scipy。但是最好不要使用pip3直接在终端安装,因为
增加sklearn逻辑回归拟合能力的解决方案
本文主要介绍了增加sklearn逻辑回归拟合能力的解决方案,希望对新手有所帮助。文章目录1. 问题描述2. 解决方案 2.1 不建议的解决方案 2.2 推荐的解决方案

sklearn 中的两个半监督标签传播算法 LabelPropagation和LabelSpreading
标签传播算法是一种半监督机器学习算法,它将标签分配给以前未标记的数据点。要在机器学习中使用这种算法,只有一小部分示例具有标签或分类。在算法的建模、拟合和预测过程中,这些标签被传播到未标记的数据点。
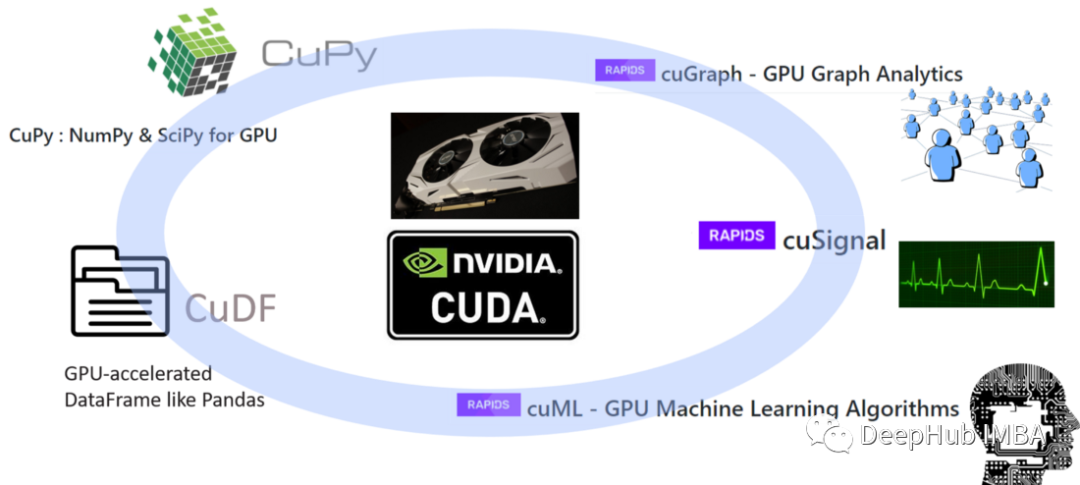
在gpu上运行Pandas和sklearn
Pandas和sklearn这两个是我们最常用的基本库,Rapids将Pandas和sklearn的功能完整的平移到了GPU之上
机器学习之手写决策树以及sklearn中的决策树及其可视化
(2)如果属性划分次数达到上限,即属性划分完了,或者是样本中在此类属性取值都一样,可以认为全部划分仍然存在不同类的样本,那么这个节点就标记为类别数占较多的叶节点。划分选择还是比较重要的,因为不同的划分选择会建出不同的决策树。划分选择的指标就是希望叶节点的数据尽可能都是属于同一类,即节点的“纯度”越来

使用阈值调优改进分类模型性能
在本文中将演示如何通过阈值调优来提高模型的性能。
猿创征文|Python-sklearn机器学习快速入门:你的第一个机器学习实战项目
从开始学习机器学习到现在已经有三年了,建模过程以及各类模型使用场景都有个大致的掌握。其中我感觉在我所有的机器学习文章中缺少一篇真正引人入门的文章。任何情况迈开学习的第一步都是比较困难的,学习的成本是很高的,相对你学会了收益也高。尤其是机器学习这种数学和逻辑能力强关联的学科,是比较难上手的事,但是当真
sklearn实现一元线性回归 【Python机器学习系列(五)】
sklearn实现一元线性回归 【Python机器学习系列(五)】
浅谈sklearn中的数据预处理
sklearn中的数据预处理
LightGBM原理与实践简记
写在前面:LightGBM 用了很久了,但是一直没有对其进行总结,本文从 LightGBM 的使用、原理及参数调优三个方面进行简要梳理。目录使用 LightGBM 官方接口,核心步骤sklearn 接口增量学习在处理大规模数据时,数据无法一次性载入内存,使用增量训练。主要通过两个参数实现:详细方法见
机器学习作业(第十八次课堂作业)
机器学习作业(第十八次课堂作业)
python机器学习从入门到高级:超参数调整(含详细代码)
Python机器学习🌸个人主页:JoJo的数据分析历险记📝个人介绍:小编大四统计在读,目前保研到统计学top3高校继续攻读统计研究生💌如果文章对你有帮助,欢迎✌关注、👍点赞、✌收藏、👍订阅专栏在我们选择好一个模型后,接下来要做的是如何提高模型的精度。因此需要进行超参数调整,一种方法是手动处
Python机器学习从入门到高级:模型评估和选择(含详细代码)
之前我们介绍了机器学习的一些基础性工作,介绍了如何对数据进行预处理,接下来我们可以根据这些数据以及我们的研究目标建立模型。那么如何选择合适的模型呢?首先需要对这些模型的效果进行评估。本文介绍如何使用`sklearn`代码进行模型评估
机器学习系列6 使用Scikit-learn构建回归模型:简单线性回归、多项式回归与多元线性回归
在本文中,我们以美国南瓜数据为例,讲解了三种线性回归的原理与使用方法,探寻数据之间的相关性,并构建了6种线性回归模型。将准确率从一开始的0.04提升到0.96.



