
交叉验证的种类和原理
所有的来自https://scikit-learn.org/stable/modules/cross_validation.html#cross-validation-iterators并掺杂了自己的理解。
文章目录
前言
前提:假设某些数据是独立且相同分布的 (i.i.d.),假设所有样本都源于同一个生成过程,并且假设生成过程没有对过去生成的样本的记忆。
注意:虽然i.i.d.数据是机器学习理论中的常见假设,但在实践中很少成立。如果知道样本是使用瞬态过程生成的,则使用时间序列感知交叉验证方案会更安全(例一)。同样,如果我们知道生成过程具有组结构(从不同受试者、实验、测量设备收集的样本),则使用分组交叉验证会更安全(例二)。
例一:像振动信号这样的信号,我们对一个信号分段截取后,每一段都和之前和之后截取的数据在时间维度上是相关的,所以每个片段之间不是独立且同分布的,所以官网针对具有时间相关性的数据创建了相关的交叉验证(时间序列感知交叉验证)。
例二:从多个患者那里收集医疗数据,从每个患者(也可以是机器部件)身上采集多个样本。在我们的示例中,每个样本的患者 ID 将是其组(group)标识符。在这种情况下,我们想知道在一组特定组上训练的模型是否能很好地泛化到看不见的组。为了衡量这一点,我们需要确保测试集中的所有样本都来训练集中根本没有表示的组。
一、基础知识
1.1 交叉验证图形表示
以四倍交叉验证为例:
0,1,2,3:每一行表示测试集和训练集的划分的一种方式。
class:表示类别的个数(下图显示的是3类),有些交叉验证根据类别的比例划分测试集和训练集(例三)。
group:表示从不同的组采集到的样本,颜色的个数表示组的个数(有些时候我们关注在一组特定组上训练的模型是否能很好地泛化到看不见的组)。举个例子(解释“组”的意思):我们有10个人,我们想要希望训练集上所用的数据来自(1,2,3,4,5,6,7,8),测试集上的数据来自(9,10),也就是说我们不希望测试集上的数据和训练集上的数据来自同一个人(如果来自同一个人的话,训练集上的信息泄漏到测试集上了,模型的泛化性能会降低,测试结果会偏好)。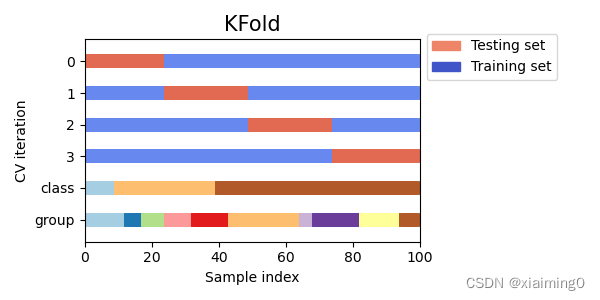
1.2 交叉验证主要类别
- 独立同分布数据的交叉验证迭代器(对应理想情况下)
- 基于类标签分层的交叉验证迭代器(对应例三)
- 分组数据的交叉验证迭代器(对应例二)
- 时间序列数据的交叉验证(对应例一)
二、部分交叉验证函数(每类一个)
2.1 Cross-validation iterators for i.i.d. data(i.i.d.数据的交叉验证迭代器)
K-fold定义
KFold 将所有样本分成 k堆大小相等的样本堆,称为折叠数(如果 k=n,这相当于 Leave One Out 策略)。分别使用其中
k-1堆样本做训练,剩余的1堆做测试(进行k次实验)。下图是k=4的情况。第0行的红色样本(1堆)作为测试集,剩余的蓝色样本(4-1=3堆)作为训练集。可以从图中看出,测试集和训练集的划分和class及grou无关,但从图上可以看出每个类别数据的数量是不一样的,同时也不是来自同一个group。所以存在一些问题
行标0,1,2,3表示训练集和测试集划分情况,K-fold这个交叉验证的class和group行只表示数据集的情况,即class表示类别的个数和每个类别所占的比例,group表示组的个数和每个组所占的比例。
值得注意的是:该划分和class及group无关,会存在在训练里没有的类别样本,在测试集里有(例如第0行的数据集划分就出现的了这样的问题:训练集没包含所有类别的样本)。
打散数据可以解决或缓解上述问题。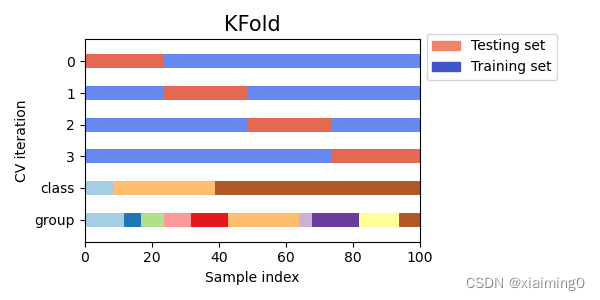
2.2 Cross-validation iterators with stratification based on class labels(基于类标签分层的交叉验证迭代器)
Stratified k-fold定义
有些分类问题的不同类别样本的比例可能不一样。
Stratified K-Fold 是 k-fold 的一种变体,它根据类别的比例指导数据集的划分,如下图所示。假设class行各个颜色(类别)的比例是1:3:6,可以看到第0行第一个红色的大小占第一个类别的1/4(k=4),第0行第二个红色的大小占第二个类别的1/4,等。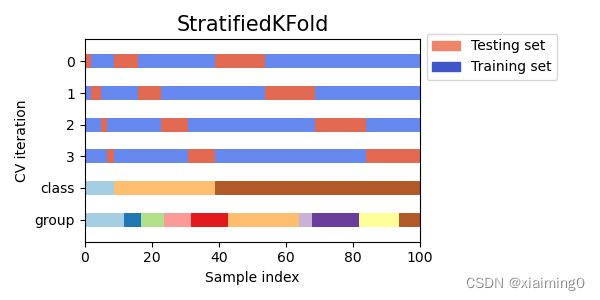
2.3 Cross-validation iterators for grouped data(分组数据的交叉验证迭代器)
Group k-fold
有些情况下,我们想知道在特定组别上训练出来的模型是否能很好地泛化到未见过的组别上。为了衡量这一点,我们需要确保测试集中的所有样本都来自训练集中完全没有的组。
Group K-Fold 是 k-fold 的一种变体,它可以确保测试集和训练集中不包含同一群体。它根据group划分测试集和训练集。
值得注意的是:该划分根据group划分数据集的,该划分和class无关,例如:第2行第一个红块包含了class行的藏青色类(第一个块)的所有样本,训练集中完全没有这各类别的数据——这是一个很大的问题。
打散数据不一定可以解决或缓解上述问题。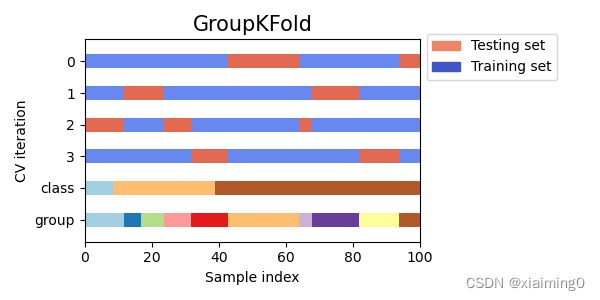
2.4 Cross validation of time series data(时间序列数据的交叉验证)
Time Series Split定义
时间序列数据的特点是时间相近的观测值之间存在相关性(自相关性)。然而,经典的交叉验证技术(如 KFold 和 ShuffleSplit)假设样本是独立且同分布的,这将导致时间序列数据的训练实例和测试实例之间存在不合理的相关性(导致泛化误差估计值较差)。因此,在 "未来 "观测数据上评估我们的时间序列数据模型非常重要,这些观测数据至少与用于训练模型的观测数据相同。为此,TimeSeriesSplit 提供了一种解决方案。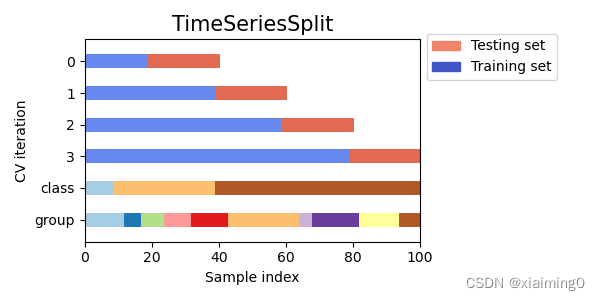
三、全部交叉验证函数
2.1 Cross-validation iterators for i.i.d. data(i.i.d.数据的交叉验证迭代器)
2.1.1 K-fold
2.1.2 Repeated K-Fold
2.1.3 Leave One Out (LOO)
2.1.4 Leave P Out (LPO)
2.1.5 Random permutations cross-validation a.k.a. Shuffle & Split
2.2 Cross-validation iterators with stratification based on class labels(基于类标签分层的交叉验证迭代器)
2.2.1 Stratified k-fold
2.2.2 Stratified Shuffle Split
2.3 Cross-validation iterators for grouped data(分组数据的交叉验证迭代器)
2.3.1 Group k-fold)
2.3.2 StratifiedGroupKFold
2.3.3 Leave One Group Out
2.3.4 Leave P Groups Out
2.3.5 Group Shuffle Split
2.4 Cross validation of time series data(时间序列数据的交叉验证)
2.5 Predefined Fold-Splits / Validation-Sets(预定义的折叠分割/验证集)
2.6 Using cross-validation iterators to split train and test(使用交叉验证迭代器拆分训练和测试)
总结
基于类标签分层的交叉验证迭代器比其他缺了3个迭代器,因为基于类标签分层的交叉验证迭代器不存在leave one out(留一法),leave p out(留P法)等。
要综合考虑class和group对数据划分的影响,也要考虑数据集本身各方面的特点。
建议:把数据集打乱,多做几组交叉验证,显示验证结果,分析结果原因。
版权归原作者 xiaiming0 所有, 如有侵权,请联系我们删除。