
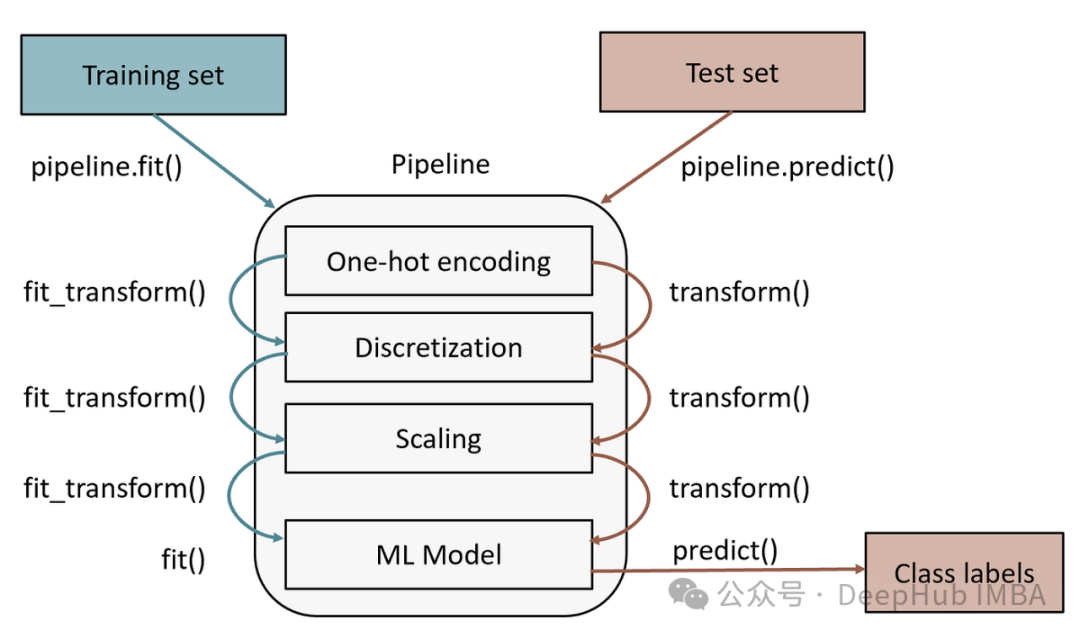
在机器学习工作流程中,组合估计器通过将多个转换器(Transformer)和预测器(Predictor)整合到一个管道(Pipeline)中,可以有效简化整个过程。这种方法不仅简化了数据预处理环节,还能确保处理过程的一致性,最大限度地降低数据泄露的风险。构建组合估计器最常用的工具是Scikit-learn提供的Pipeline类。
关键术语
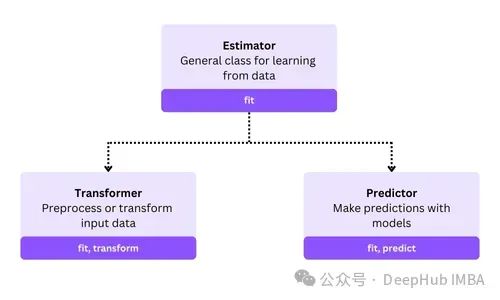
**估计器(Estimator)**泛指任何实现了
fit
方法的对象,该方法可以从数据中学习参数。估计器的概念涵盖了模型、预处理器以及管道等多种类型。
**转换器(Transformer)**是一种特殊的估计器,主要用于数据预处理或特征工程。转换器同时实现了
fit
方法(从数据中学习转换规则)和
transform
方法(将学习到的转换规则应用到数据上)。常见的转换器包括缩放器(Scaler)、降维器(Dimensionality Reduction)、编码器(Encoder)等。
**预测器(Predictor)**是用于监督学习任务(如分类或回归)的一类估计器。预测器需要实现
fit
方法(用于在训练集上学习)和
predict
方法(用于在测试集上进行预测)。
管道(Pipeline)
管道(或者叫流水线)可以将多个估计器串联起来,形成一个完整的工作流程。在数据处理过程中通常需要遵循一系列固定的步骤,例如特征选择、数据归一化以及模型训练等,所以一般会用这种形式来串联我们的训练过程。
使用管道有以下几个主要目的:
- 便捷性和封装性: 只需调用一次
fit和predict方法,即可完成从数据预处理到模型训练的全部步骤。 - 联合参数选择: 可以使用网格搜索等方法,一次性地对管道中所有估计器的超参数进行优化。
- 避免数据泄露: 通过交叉验证等方式,管道可以有效防止在训练过程中发生数据泄露。
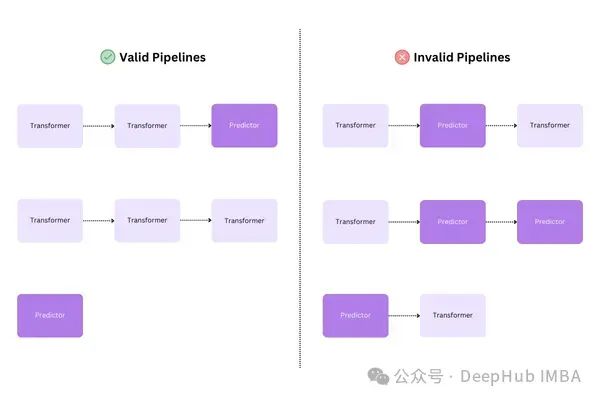
管道中除最后一个估计器以外,其余估计器都必须是转换器(即必须实现
transform
方法)。最后一个估计器可以是任意类型,包括转换器、分类器等。
构建管道
构建管道需要提供一个由
(key, value)
元组组成的列表,其中
key
是字符串类型,表示当前步骤的名称;
value
则是一个估计器对象。下面是一个构建管道的示例:
fromsklearn.pipelineimportPipeline
fromsklearn.linear_modelimportLogisticRegression
fromsklearn.decompositionimportPCA
pipeline=Pipeline([
('transformer_1', StandardScaler()),
('predictor', LogisticRegression())
])
pipeline
在上述示例中,我们首先使用
StandardScaler
对数据进行标准化处理,确保所有特征都经过适当的缩放。然后再将
LogisticRegression
模型作为预测器,对数据进行二分类。通过管道可以方便地对整个训练集进行拟合和预测,代码如下所示:
# 拟合管道
pipeline.fit(X_train, y_train)
# 管道预测
y_pred=pipeline.predict(X_test)
在拟合阶段,训练数据将依次通过管道中的各个转换器,依次完成拟合和转换操作。处理后的数据最终被用于训练预测模型。在预测阶段,管道会对测试数据应用与训练时相同的转换操作,再由预测器给出最终的预测结果。
网格搜索与交叉验证
手动调优超参数费时费力,而且往往难以取得理想的效果。这时就可以借助Scikit-learn提供的GridSearchCV类,自动化地搜索最优超参数组合。
fromsklearn.model_selectionimportGridSearchCV
# 定义网格搜索参数
grid_params= {
'transformer_1__with_mean': [True, False],
'predictor__C': [0.1, 1, 10]
}
# 执行网格搜索
grid=GridSearchCV(pipeline, grid_params, cv=10)
grid.fit(X_train, y_train)
在
grid_params
字典中,指定了需要优化的超参数及其候选取值:
transformer_1__with_mean: 管道中transformer_1步骤的with_mean参数,取值为布尔类型。predictor__C: 管道中predictor步骤的正则化强度C,取值为数值类型。cv=10: 指定交叉验证的折数为10。
通过网格搜索可以找到模型在当前数据集上的最优超参数组合。这个过程可以确保管道在性能上得到充分优化。
保存和加载管道
一旦通过
GridSearchCV
完成了管道的训练和优化,就可以将其保存起来,供日后使用。下面的代码展示了如何保存和加载一个已经训练好的管道:
importjoblib
# 保存管道
joblib.dump(pipeline, 'pipeline.pkl')
# 加载管道
loaded_pipeline=joblib.load('pipeline.pkl')
这一功能在实际生产环境中尤为重要。通过保存训练好的管道可以直接将其部署到线上系统,用于对新数据进行实时预测,而无需重新训练模型。
为什么要保存管道?
保存管道有以下几个主要原因:
- 复用性: 避免了每次使用都需要重新训练模型和执行数据预处理的繁琐步骤。
- 一致性: 确保对不同数据集应用相同的转换操作和模型,提高结果的可重复性。
- 部署便捷: 将管道整体保存为一个对象,可以方便地集成到生产系统中,实现实时预测。
- 时间效率: 对于复杂的管道或大规模数据集,重用已训练的管道可以显著节省计算时间。
完整示例代码
下面的代码展示了如何使用Scikit-learn管道完成端到端的机器学习流程:
- 定义包含数据转换和模型的管道;
- 使用
GridSearchCV搜索最优超参数,并拟合管道; - 使用训练好的管道对测试集进行预测。
fromsklearn.pipelineimportPipeline
fromsklearn.linear_modelimportLogisticRegression
fromsklearn.decompositionimportPCA
fromsklearn.model_selectionimportGridSearchCV
# 创建管道
pipeline=Pipeline([
('transformer_1', StandardScaler()),
('predictor', LogisticRegression())
])
# 定义网格搜索参数
grid_params= {
'transformer_1__with_mean': [True, False],
'predictor__C': [0.1, 1, 10]
}
# 执行网格搜索
grid=GridSearchCV(pipeline, grid_params, cv=10)
grid.fit(X_train, y_train)
# 使用管道进行预测
y_pred=pipeline.predict(X_test)
总结
Scikit-learn管道是构建高效、鲁棒、可复用的机器学习工作流程的利器。通过掌握管道的使用,我们可以轻松地完成从数据预处理到模型训练、评估和部署的全流程,极大地提高工作效率。建议在实际项目中多多尝试和运用管道,以期进一步优化您的机器学习流程。
Mohammed Shammeer