
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_openml
from sklearn.linear_model import SGDClassifier
from sklearn.model_selection import cross_val_score
mnist = fetch_openml('mnist_784', version=1, parser='auto')
X, y = mnist['data'], mnist['target']
X = np.array(X)
y = np.array(y)
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
shuffle_index = np.random.permutation(60000)
X_train, y_train = X_train[shuffle_index], y_train[shuffle_index]
y_train_5 = (y_train=='5')
y_test_5 = (y_test=='5')
clf = SGDClassifier(random_state=42)
clf.fit(X_train,y_train_5)
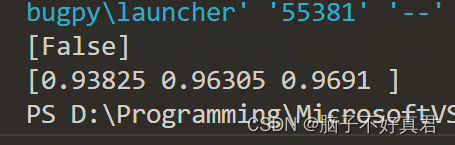
result_X_66666 = clf.predict([X[66666]])
print(result_X_66666)
image = X[66666].reshape(28, 28)
plt.imshow(image, cmap='gray') # 图像以灰度模式显示
plt.show()
result_cross_val_score= cross_val_score(clf, X_train, y_train_5, cv=3)
print(result_cross_val_score)
1. 下图报错也许是因为尝试使用shuffle_index数组来索引X_train[]DataFrame时,该索引数组中的值被误解。将X和y转换为numpy数组,然后再进行随机洗牌操作,解决报错。
X = np.array(X)
y = np.array(y)

2. shuffle_index = np.random.permutation(60000)
random.permutation函数生成一个长度为60000的随机排列数组。这个数组shuffle_index可以用于打乱数据集,确保数据的随机性。
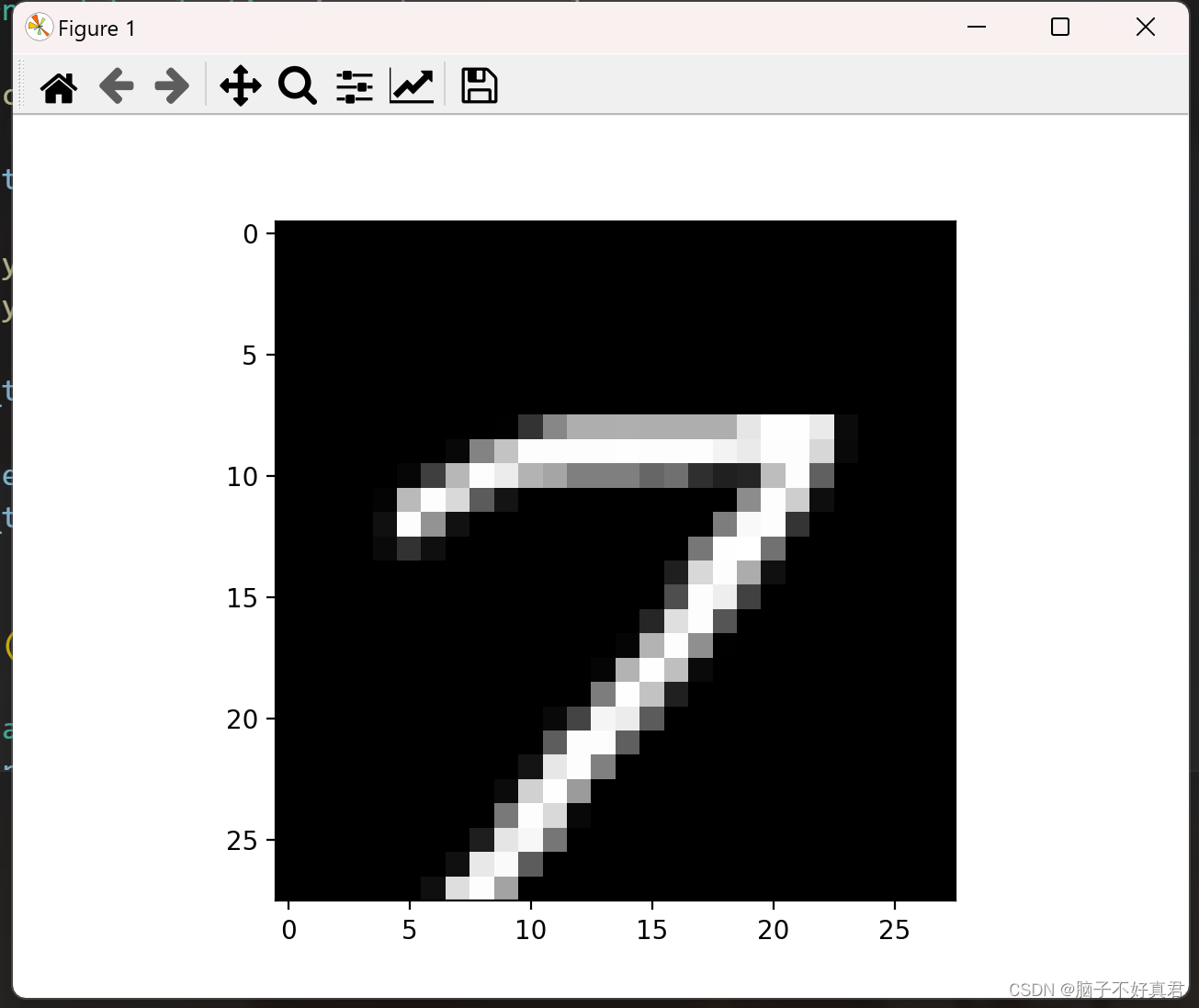
3. 以图片形式显示X[66666]
image = X[66666].reshape(28, 28)
plt.imshow(image, cmap='gray')
plt.show()
4. clf = SGDClassifier(random_state=42)
random_state参数是许多算法中用于控制随机数生成的种子值的一个常见参数。通过设置random_state为一个固定的整数值,可以确保代码的随机性部分是可重复的,这意味着每次运行代码时,如果输入数据不变,使用相同的random_state值将得到完全相同的结果。
5. 结果
6. 学习视频
4-交叉验证实验分析_哔哩哔哩_bilibili
本文转载自: https://blog.csdn.net/naozibuok/article/details/136062306
版权归原作者 脑子不好真君 所有, 如有侵权,请联系我们删除。
版权归原作者 脑子不好真君 所有, 如有侵权,请联系我们删除。