【pytorch】深度学习所需算力估算:flops及模型参数量
因为8GB显卡的实际可用显存约为7500MB左右,可以满足模型在最大推理batchsize下的显存需求,同时还有一定的余量,可以保证模型能够正常运行。在部署时,需要考虑芯片的显存,是因为显存的大小限制了模型的最大批次大小。如果模型的批次大小超过了显存的大小,那么就无法将整个批次的数据同时加载到显存中
【深度强化学习】(8) iPPO 模型解析,附Pytorch完整代码
IPPO(Independent PPO)是一种完全去中心化的算法,此类算法被称为独立学习。由于对于每个智能体使用单智能体算法 PPO 进行训练,所因此这个算法叫作独立 PPO算法。这里使用的 PPO 算法版本为 PPO-截断

VLAD Diffusion,一个更好用且易于安装的Stable Diffusion Web UI
VLAD Diffusion 是我们前面介绍过的 AUTOMATIC1111/stable-diffusion-webui的一个定制的更新,它主要是为了更频繁发布的更新和错误修复。
基于yolov5的Android版本目标检测app开发(部署安卓手机)
基于yolov5的Android版本目标检测app开发(部署安卓手机)1、开发环境搭建2、数据集准备3、模型训练4、模型转换5、Androidapp开发6、运行检测7、项目开发中遇到的问题总结
使用Pytorch进行多卡训练
当一块GPU不够用时,我们就需要使用多卡进行并行训练。其中多卡并行可分为数据并行和模型并行。具体区别如下图所示: 由于模型并行比较少用,这里只对数据并行进行记录。对于pytorch,有两种方式可以进行数据并行:数据并行(DataParallel, DP)和分布式数据并行(Distributed
Pytorch实现GCN(基于PyTorch实现)
本专栏整理了《图神经网络代码实战》,内包含了不同图神经网络的相关代码实现(PyG以及自实现),理论与实践相结合,如GCN、GAT、GraphSAGE等经典图网络,每一个代码实例都附带有完整的代码。
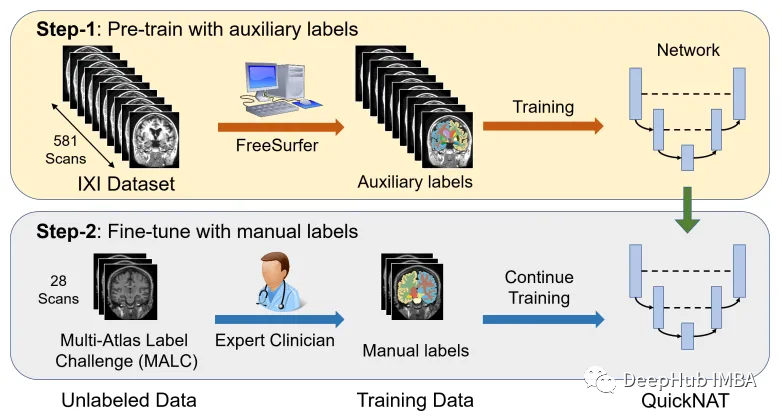
医学图像的深度学习的完整代码示例:使用Pytorch对MRI脑扫描的图像进行分割
本文我们将介绍如何使用QuickNAT对人脑的图像进行分割。使用MONAI, PyTorch和用于数据可视化和计算的常见Python库,如NumPy, TorchIO和matplotlib。
Pytorch平均池化nn.AvgPool2d()使用记录
PyTorch学习笔记之二维平均池化nn.AvgPool2d()
PyTorch中查看GPU使用情况以及一些重要函数
pytorch多卡相应内容学习总结,本着勤能补拙的态度,希望能够更好地提升自我能力。
pytorch复习笔记--nn.Embedding()的用法
nn.Embedding()产生一个权重矩阵weight,其shape为(num_embeddings, embedding_dim),表示生成num_embeddings个具有embedding_dim大小的嵌入向量;输入input的形状shape为(batch_size, Seq_len),ba
PyTorch深度学习实战 | 基于深度学习的电影票房预测研究
基于深度学习的映前票房预测模型(Cross&Dense网络结构模型),该模型通过影片基本信息如:电影类型、影片制式、档期和电影的主创阵容和IP特征等信息对上映影片的票房进行预测。本篇采用451部电影作为训练模型,最后再在194部影片上进行测试,模型的绝对精度为55%,相对精度为92%。该模型在使用相
真的不能再详细了,2W字保姆级带你一步步用Pytorch搭建卷积神经网络实现MNIST手写数字识别
2w6k字,真的不能再详细了!!!几乎每一行代码都有注释!!!本教程包括MNIST数据集的下载与保存与加载、卷积神经网路的构建、模型的训练、模型的测试、模型的保存、模型的加载与继续训练和测试、模型训练过程、测试过程的可视化、模型的使用。
PyTorch 进行多步时间序列预测详细教程
PyTorch 进行多步时间序列预测详细教程
DeepSpeed配置参数 - 快速上手
针对DeepSpeed的几组重要的参数进行说明
Pytorch运行过程中解决出现内存不足的问题
1. 前提利用Transformer模型进行O3浓度的反演2. 问题2.1 速度慢一开始模型是在CPU上面跑的,为了加快速度,我改成了在GPU上跑方法如下:1、验证pytorch是否存在GPU版本在Pycharm命令行输入import torchprint(torch.cuda.is_availab
【PyTorch】教程:DCGAN
本教程将通过一个示例来介绍 DCGAN。我将训练一个生成对抗网络 (GAN) ,在向其展示许多真实名人的照片后生成新的名人。这里大部分代码来自于。本文档针对这些实现进行全面解释,并阐述该模型的工作方式和原因。
pytorch--在本地搭建chatGpt简化版,实现聊天,写代码功能
体验了一下new bing,很不错,但是最近觉得这种模型还是搭建在自己电脑上最好,看了下github上的chatGLM项目,这个项目在致力于将一个大语言模型搭建在个人机上,我对此惊叹不已,就按照其流程下载下来搭建在自己电脑上了,这种模型运行在自己电脑上的感觉不会有那种隐私被偷窥的感觉,同时自己可以对
LSTM实现多变量输入多步预测(直接多输出)时间序列预测(PyTorch版)
本专栏整理了《深度学习时间序列预测案例》,内包含了各种不同的基于深度学习模型的时间序列预测方法,例如LSTM、GRU、CNN(一维卷积、二维卷积)、LSTM-CNN、BiLSTM、Self-Attention、LSTM-Attention、Transformer等经典模型,💥💥💥包含项目原理以
Pytorch深度学习基础 实战天气图片识别(基于ResNet50预训练模型,超详细)
🔥本项目使用Pytroch,并基于ResNet50模型,实现了对天气图片的识别,过程详细,十分适合基础阶段的同学阅读。项目目录结构核心步骤数据处理准备配置文件构建自定义DataSet及Dataloader构建模型训练模型编写预测模块效果展示。
【深度学习、工程实践】关系抽取Casrel实现(Pytorch版)
CASREL 分为两个步骤1.识别出句子中的subject2.根据subject识别出所有可能的relation和object其中模型分为三个部分1.BERT-based encoder module:编码2.subject tagging module:目的是识别出句子中的 subject。3.r



