
一.代码和数据集准备
1.代码:
使用b站up主霹雳吧啦Wz提供的代码:https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/tree/master/pytorch_object_detection/faster_rcnn
2.数据集
①PASCAL VOC2012数据集
下载地址:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
②自己的数据集
按VOC数据集格式准备,因为只进行目标检测,按下图层级目录和文件夹命名即可。
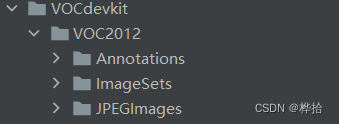
其中
Annotations文件夹里存在所有数据集的.xml文件
JPEGImages文件夹里存在所有数据集的.jpg文件
ImageSets文件夹里存放Main文件夹

再在Main文件夹中存放以下4个.txt文件
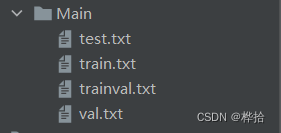
其中
- train.txt:训练集
- val.txt:验证集
- trainval.txt:训练和验证集
- test.txt:测试集
只是训练阶段,可仅保留train.txt和val.txt。可以利用split_data.py文件(代码如下)直接随机生成这两个文件,然后放到相应的目录下即可。
import os
import random
def main():
random.seed(0) # 设置随机种子,保证随机结果可复现
files_path = "./VOCdevkit/VOC2012/Annotations"
assert os.path.exists(files_path), "path: '{}' does not exist.".format(files_path)
val_rate = 0.5
files_name = sorted([file.split(".")[0] for file in os.listdir(files_path)])
files_num = len(files_name)
val_index = random.sample(range(0, files_num), k=int(files_num*val_rate))
train_files = []
val_files = []
for index, file_name in enumerate(files_name):
if index in val_index:
val_files.append(file_name)
else:
train_files.append(file_name)
try:
train_f = open("train.txt", "x")
eval_f = open("val.txt", "x")
train_f.write("\n".join(train_files))
eval_f.write("\n".join(val_files))
except FileExistsError as e:
print(e)
exit(1)
if __name__ == '__main__':
main()
此外,还需根据自己的数据集,相应地修改.json文件。

二.训练网络
1.下载预训练权重
该up主提供了两个版本的backbone
mobilenetv2+fasterrcnn和resnet50+fpn+fasterrcnn
其预训练权重分别对应下载地址:
https://download.pytorch.org/models/mobilenet_v2-b0353104.pth
https://download.pytorch.org/models/resnet50-0676ba61.pth
下载后,需重新命名文件名,然后放到bakcbone文件夹下
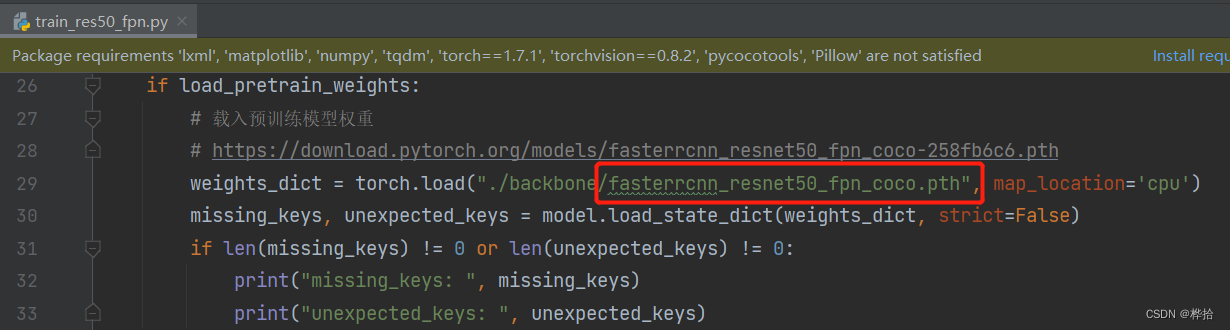
使其与训练代码中,指定的载入权重地址相同即可,否则会报错,找不到权重文件。
2.训练网络可能遇到的问题
若要训练mobilenetv2+fasterrcnn,直接使用train_mobilenet.py训练脚本。
若要训练resnet50+fpn+fasterrcnn,直接使用train_resnet50_fpn.py训练脚本
此外,up主还提供多GPU版本训练,本文以训练resnet50+fpn+fasterrcnn为例。
数据集位置和识别的类别 如需修改,则修改黄色方框圈出的位置。注意,类别数通常包含背景,要在类别的基础上+1,但是这里的识别数是不包含背景的。
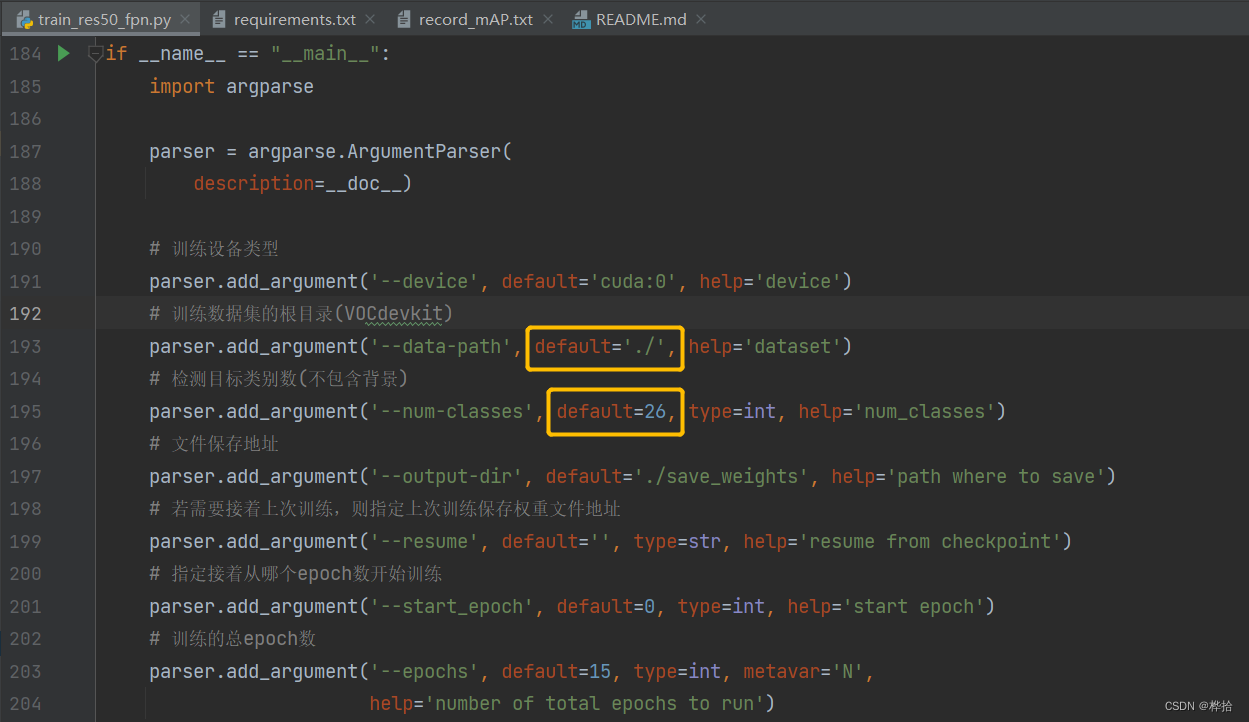
训练设备显存不足,则修改batch_size的大小,将8改为4,甚至是2。
 修改相应的参数后,即可训练。
修改相应的参数后,即可训练。
如需预测,则运行以下文件。记得修改代码中,制定的文件路径。

版权归原作者 桦拾 所有, 如有侵权,请联系我们删除。