
1. Attention(注意力机制)的诞生
注意力机制,起初是作为自然语言处理中的工作为大家熟知(文章 Attention is all you need 详细介绍了“什么是注意力机制”)。注意力机制的本质就是定位到感兴趣的信息,抑制无用信息,结果通常都是以概率图或者概率特征向量的形式展示,从原理上来说,主要分为空间注意力模型,通道注意力模型,空间和通道混合注意力模型三种。
即:① 注意力机制是深度学习常用的一个小技巧。② 注意力机制的核心重点就是让网络关注到它更需要关注的地方。当我们使用卷积神经网络去处理图片的时候,我们会更希望卷积神经网络去注意应该注意的地方,而不是什么都关注,我们不可能手动去调节需要注意的地方,这个时候,如何让卷积神经网络去自适应的注意重要的物体变得极为重要。而注意力机制就是实现网络自适应注意的一个方式。③ 一般而言,注意力机制可以分为通道注意力机制,空间注意力机制,以及二者的结合。
2. Attention模型架构
2.1 空间注意力模型(spatial attention)
不是图像中所有的区域对任务的贡献都是同样重要的,只有与任务相关的区域才是需要关心的,比如分类任务的主体,空间注意力模型就是寻找网络中最重要的部位进行处理。
和注意力机制相伴而生的一个任务便是显著目标检测,即salient object detection。它的输入是一张图,输出是一张概率图,概率越大的地方,代表是图像中重要目标的概率越大,即人眼关注的重点,一个典型的显著图如下:

右图就是左图的显著图,在头部位置概率最大,另外腿部,尾巴也有较大概率,这就是图中真正有用的信息。
显著目标检测需要一个数据集,而这样的数据集的收集便是通过追踪多个实验者的眼球在一定时间内的注意力方向进行平均得到,典型的步骤如下:
(1) 让被测试者观察图。
(2) 用eye tracker记录眼睛的注意力位置。
(3) 对所有测试者的注意力位置使用高斯滤波进行综合。
(4) 结果以0~1的概率进行记录。
于是就能得到下面这样的图,第二行是眼球追踪结果,第三行就是显著目标概率图。

上面讲述的都是空间上的注意力机制,即关注的是不同空间位置,而在CNN结构中,还有不同的特征通道,因此不同特征通道也有类似的原理。由于在大部分情况下我们感兴趣的区域只是图像中的一小部分,因此空间注意力的本质就是定位目标并进行一些变换或者获取权重。
2.2 通道注意力机制
对于输入2维图像的CNN来说,一个维度是图像的尺度空间,即长宽,另一个维度就是通道,因此基于通道的Attention也是很常用的机制。通道注意力机制的本质,在于建模了各个特征之间的重要性,对于不同的任务可以根据输入进行特征分配,简单而有效。
Ⅰ. SENet(Sequeeze and Excitation Net)
SENet(Sequeeze and Excitation Net)[3]是2017届ImageNet分类比赛的冠军网络,本质上是一个基于通道的Attention模型,它通过建模各个特征通道的重要程度,然后针对不同的任务增强或者抑制不同的通道,原理图如下:
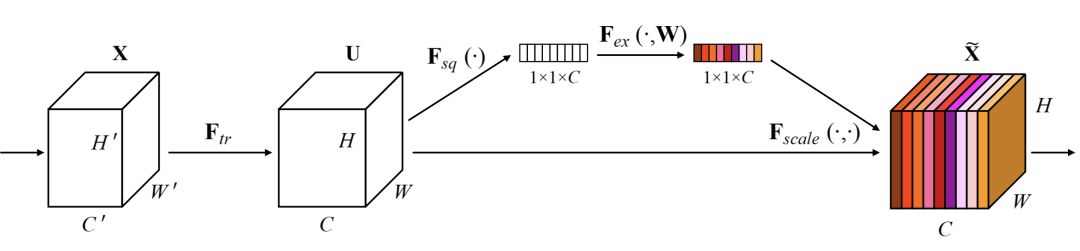
在正常的卷积操作后分出了一个旁路分支,首先进行Squeeze操作(即图中Fsq(·)),它将空间维度进行特征压缩,即每个二维的特征图变成一个实数,相当于具有全局感受野的池化操作,特征通道数不变。
然后是Excitation操作(即图中的Fex(·)),它通过参数w为每个特征通道生成权重,w被学习用来显式地建模特征通道间的相关性。在文章中,使用了一个2层bottleneck结构(先降维再升维)的全连接层+Sigmoid函数来实现。
得到了每一个特征通道的权重之后,就将该权重应用于原来的每个特征通道,基于特定的任务,就可以学习到不同通道的重要性。
将其机制应用于若干基准模型,在增加少量计算量的情况下,获得了更明显的性能提升。作为一种通用的设计思想,它可以被用于任何现有网络,具有较强的实践意义。而后SKNet[4]等方法将这样的通道加权的思想和Inception中的多分支网络结构进行结合,也实现了性能的提升。
Ⅱ. ECANet
ECANet也是通道注意力机制的一种实现形式。ECANet可以看作是SENet的改进版。
ECANet的作者认为SENet对通道注意力机制的预测带来了副作用,捕获所有通道的依赖关系是低效并且是不必要的。在ECANet的论文中,作者认为卷积具有良好的跨通道信息获取能力。
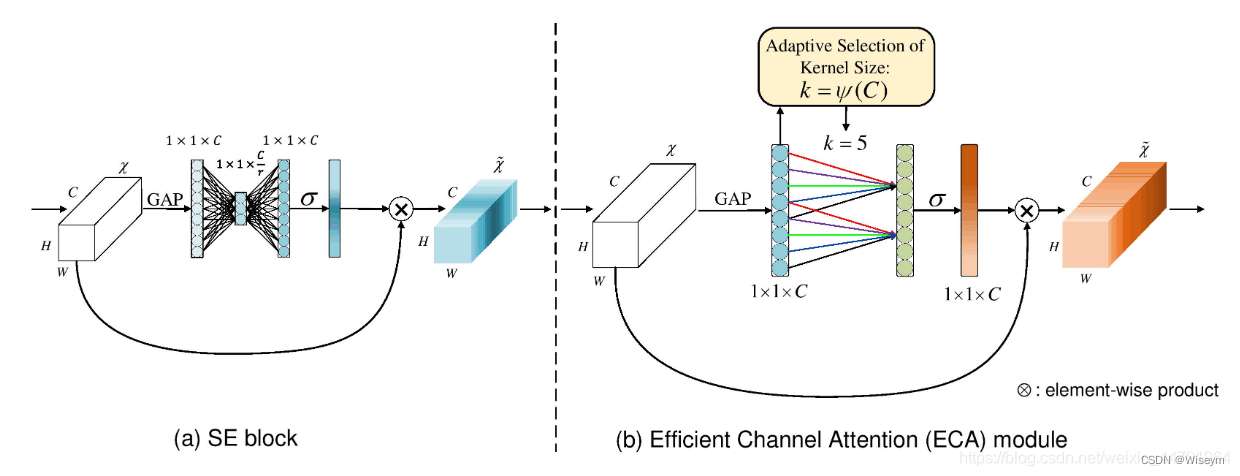
ECA模块的思想是非常简单的,它去除了原来SE模块中的全连接层,直接在全局平均池化之后的特征上通过一个1D卷积进行学习。既然使用到了1D卷积,那么1D卷积的卷积核大小的选择就变得非常重要了,1D卷积的卷积核大小会影响注意力机制每个权重的计算要考虑的通道数量。用更专业的名词就是跨通道交互的覆盖率。
如下图所示,左图是常规的SE模块,右图是ECA模块。ECA模块用1D卷积替换两次全连接。
通道注意力机制模型——Pytorch 实现
SENet是通道注意力机制的典型实现。
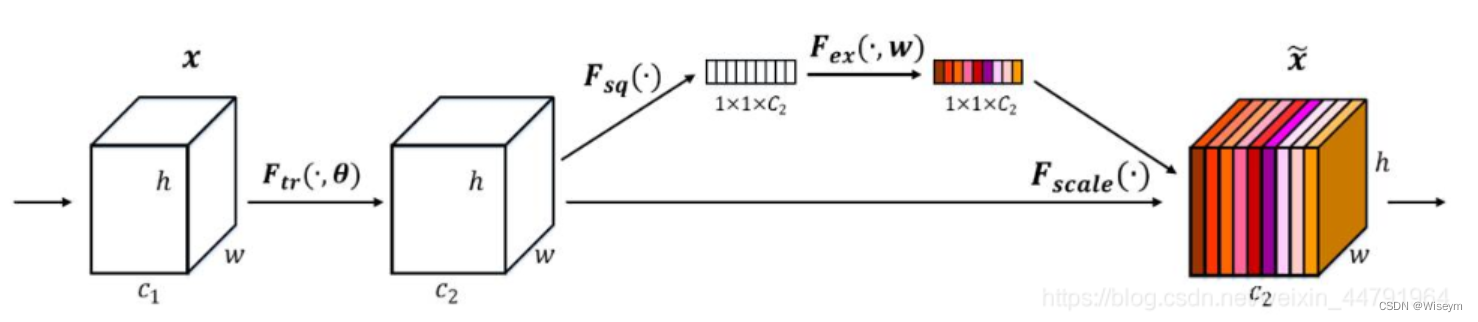
2017年提出的SENet是最后一届ImageNet竞赛的冠军,其实现示意图如下所示,对于输入进来的特征层,我们关注其每一个通道的权重,对于SENet而言,其重点是获得输入进来的特征层,每一个通道的权值。利用SENet,我们可以让网络关注它最需要关注的通道。
其具体实现方式:
1、对输入进来的特征层进行全局平均池化。
2、然后进行两次全连接,第一次全连接神经元个数较少,第二次全连接神经元个数和输入特征层相同。
3、在完成两次全连接后,我们再取一次Sigmoid将值固定到0-1之间,此时我们获得了输入特征层每一个通道的权值(0-1之间)。
4、在获得这个权值后,我们将这个权值乘上原输入特征层即可。
**SENet—— Pytorch代码实现如下: **
import torch
import torch.nn as nn
import math
class se_block(nn.Module):
def __init__(self, channel, ratio=16):
super(se_block, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // ratio, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // ratio, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
ECANet也是通道注意力机制的一种实现形式。
ECANet可以看作是SENet的改进版。ECA模块的思想是非常简单的,它去除了原来SE模块中的全连接层,直接在全局平均池化之后的特征上通过一个1D卷积进行学习。既然使用到了1D卷积,那么1D卷积的卷积核大小的选择就变得非常重要了,1D卷积的卷积核大小会影响注意力机制每个权重的计算要考虑的通道数量。ECA模块用1D卷积替换两次全连接。
ECANet—— Pytorch代码实现如下:
class eca_block(nn.Module):
def __init__(self, channel, b=1, gamma=2):
super(eca_block, self).__init__()
kernel_size = int(abs((math.log(channel, 2) + b) / gamma))
kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=(kernel_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
y = self.avg_pool(x)
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
y = self.sigmoid(y)
return x * y.expand_as(x)
2.3 空间和通道注意力机制的融合
前述的Dynamic Capacity Network是从空间维度进行Attention,SENet是从通道维度进行Attention,自然也可以同时使用空间Attention和通道Attention机制。
CBAM(Convolutional Block Attention Module)[5]是其中的代表性网络,结构如下:
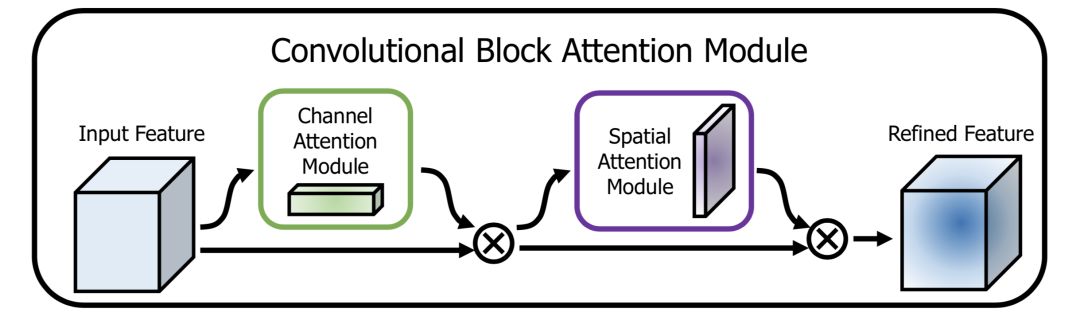
通道方向的Attention建模的是特征的重要性,结构如下:
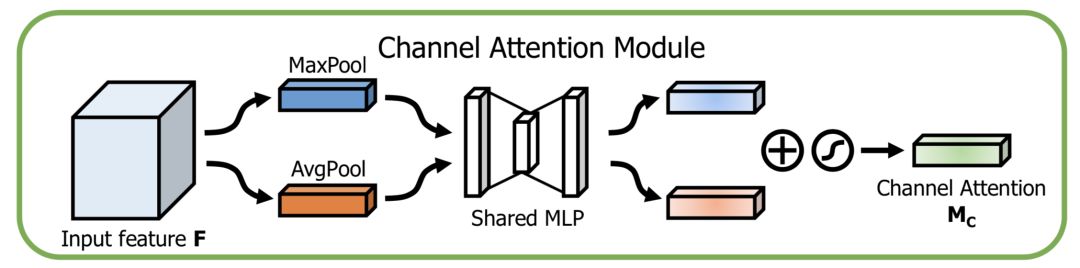
同时使用最大pooling和均值pooling算法,然后经过几个MLP层获得变换结果,最后分别应用于两个通道,使用sigmoid函数得到通道的attention结果。
空间方向的Attention建模的是空间位置的重要性,结构如下:
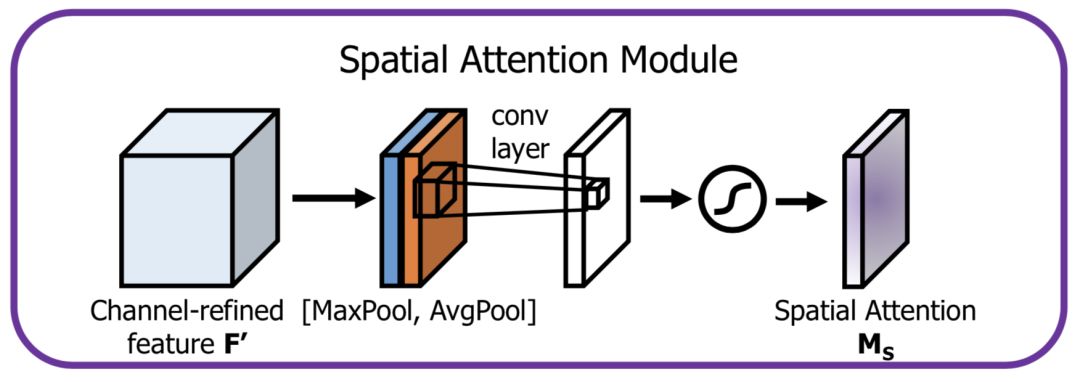
首先将通道本身进行降维,分别获取最大池化和均值池化结果,然后拼接成一个特征图,再使用一个卷积层进行学习。
这两种机制,分别学习了通道的重要性和空间的重要性,还可以很容易地嵌入到任何已知的框架中。
CBAM的实现
CBAM将通道注意力机制和空间注意力机制进行一个结合,相比于SENet只关注通道的注意力机制可以取得更好的效果。其实现示意图如下所示,CBAM会对输入进来的特征层,分别进行通道注意力机制的处理和空间注意力机制的处理。
下图是通道注意力机制和空间注意力机制的具体实现方式:
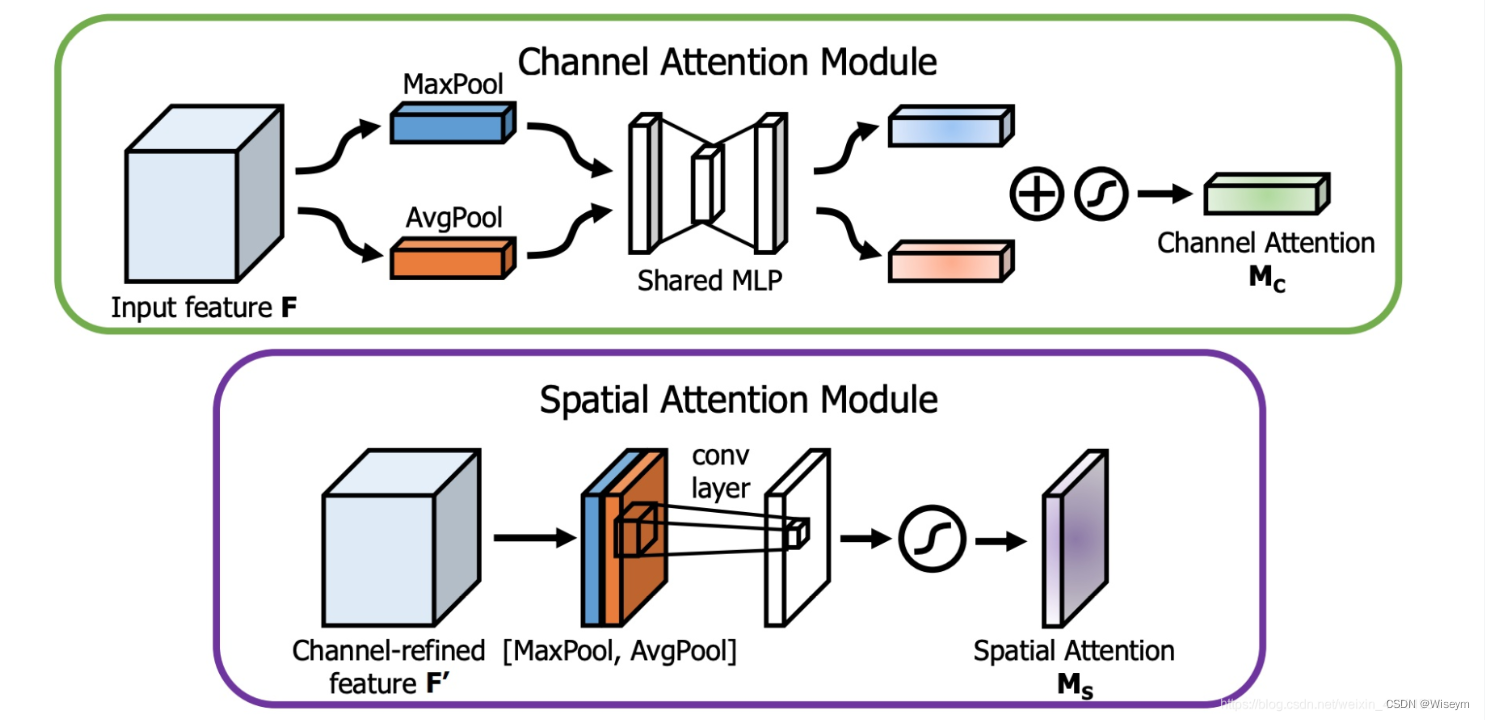
图像的上半部分为通道注意力机制,通道注意力机制的实现可以分为两个部分,我们会对输入进来的单个特征层,分别进行全局平均池化和全局最大池化。之后对平均池化和最大池化的结果,利用共享的全连接层进行处理,我们会对处理后的两个结果进行相加,然后取一个sigmoid,此时我们获得了输入特征层每一个通道的权值(0-1之间)。在获得这个权值后,我们将这个权值乘上原输入特征层即可。
图像的下半部分为空间注意力机制,我们会对输入进来的特征层,在每一个特征点的通道上取最大值和平均值。之后将这两个结果进行一个堆叠,利用一次通道数为1的卷积调整通道数,然后取一个sigmoid,此时我们获得了输入特征层每一个特征点的权值(0-1之间)。在获得这个权值后,我们将这个权值乘上原输入特征层即可。
CBAM——** Pytorch代码实现如下:**
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=8):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
# 利用1x1卷积代替全连接
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
class cbam_block(nn.Module):
def __init__(self, channel, ratio=8, kernel_size=7):
super(cbam_block, self).__init__()
self.channelattention = ChannelAttention(channel, ratio=ratio)
self.spatialattention = SpatialAttention(kernel_size=kernel_size)
def forward(self, x):
x = x * self.channelattention(x)
x = x * self.spatialattention(x)
return x
除此之外,还有很多的注意力机制相关的研究,比如残差注意力机制,多尺度注意力机制,递归注意力机制等。
3. 注意力机制的应用
注意力机制是一个即插即用的模块,理论上可以放在任何一个特征层后面,可以放在主干网络,也可以放在加强特征提取网络。
由于放置在主干会导致网络的预训练权重无法使用,本文以YoloV4-tiny为例,将注意力机制应用加强特征提取网络上。
如下图所示,我们在主干网络提取出来的两个有效特征层上增加了注意力机制,同时对上采样后的结果增加了注意力机制。
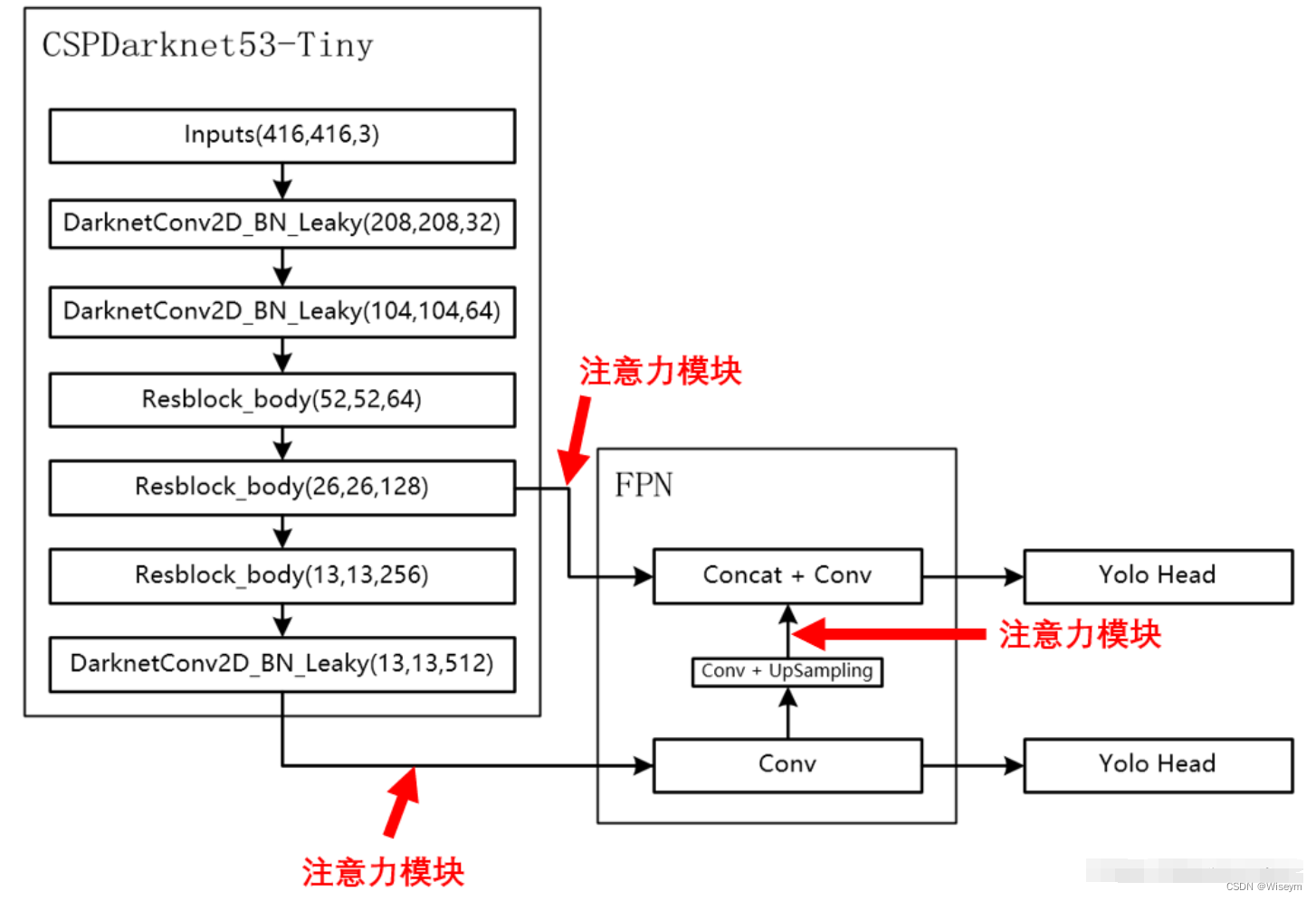 实现代码如下:
实现代码如下:
attention_block = [se_block, cbam_block, eca_block]
#---------------------------------------------------#
# 特征层->最后的输出
#---------------------------------------------------#
class YoloBody(nn.Module):
def __init__(self, anchors_mask, num_classes, phi=0):
super(YoloBody, self).__init__()
self.phi = phi
self.backbone = darknet53_tiny(None)
self.conv_for_P5 = BasicConv(512,256,1)
self.yolo_headP5 = yolo_head([512, len(anchors_mask[0]) * (5 + num_classes)],256)
self.upsample = Upsample(256,128)
self.yolo_headP4 = yolo_head([256, len(anchors_mask[1]) * (5 + num_classes)],384)
if 1 <= self.phi and self.phi <= 3:
self.feat1_att = attention_block[self.phi - 1](256)
self.feat2_att = attention_block[self.phi - 1](512)
self.upsample_att = attention_block[self.phi - 1](128)
def forward(self, x):
#---------------------------------------------------#
# 生成CSPdarknet53_tiny的主干模型
# feat1的shape为26,26,256
# feat2的shape为13,13,512
#---------------------------------------------------#
feat1, feat2 = self.backbone(x)
if 1 <= self.phi and self.phi <= 3:
feat1 = self.feat1_att(feat1)
feat2 = self.feat2_att(feat2)
# 13,13,512 -> 13,13,256
P5 = self.conv_for_P5(feat2)
# 13,13,256 -> 13,13,512 -> 13,13,255
out0 = self.yolo_headP5(P5)
# 13,13,256 -> 13,13,128 -> 26,26,128
P5_Upsample = self.upsample(P5)
# 26,26,256 + 26,26,128 -> 26,26,384
if 1 <= self.phi and self.phi <= 3:
P5_Upsample = self.upsample_att(P5_Upsample)
P4 = torch.cat([P5_Upsample,feat1],axis=1)
# 26,26,384 -> 26,26,256 -> 26,26,255
out1 = self.yolo_headP4(P4)
return out0, out1
代码下载
Github源码下载地址为:
https://github.com/bubbliiiing/yolov4-tiny-pytorch
复制该路径到地址栏跳转。
参考文献:
(124条消息) 神经网络学习小记录64——Pytorch 图像处理中注意力机制的解析与代码详解_Bubbliiiing的博客-CSDN博客
(124条消息) 一文读懂计算机视觉中的注意力机制原理及其模型发展_AI科技大本营的博客-CSDN博客
(124条消息) Pytorch 图像处理中常用的注意力机制的解析与代码详解_蓝胖胖▸的博客-CSDN博客_注意力机制pytorch代码
Pytorch 图像处理中注意力机制的代码详解与应用(Bubbliiiing 深 - 哔哩哔哩 (bilibili.com)
版权归原作者 Wiseym 所有, 如有侵权,请联系我们删除。