
多智能体系统一旦从顺序执行走向并行,测试的需求就更严格了。单个智能体的输出可能都是对的,但多个智能体并行决策、彼此影响时,集体行为可能违反系统级约束,而传统的单元测试和输出断言对这类问题完全无能为力。
这篇文章聚焦的就是这个问题:如何测试并行多智能体系统的协调行为。以一个跨四个城市的网络流量调度系统为例,从轨迹捕获、行为不变量、回放回归、黄金数据集到 CI/CD 集成,逐步搭建一套完整的协调测试框架。
被测系统
具体场景是骨干网光纤切断事件的自动响应。当故障被检测到时,一个 Coordinator Agent 分析影响范围,将任务分发给四个并行的区域流量智能体,分别负责纽约、达拉斯、拉斯维加斯和旧金山。四个智能体并行工作,转移流量负载,对非关键服务施加限速,目标是在级联拥塞发生之前完成处置。
┌──────────────────────┐
│ Fiber Cut Detected │
│ (BGP flap alarm) │
└──────────┬───────────┘
│
▼
┌─────────────────────┐
│ Coordinator Agent │
│ (impact analysis + │
│ task delegation) │
└──────────┬──────────┘
│
┌────────────────────┼─────────────────────────────────────────┐
▼ ▼ ▼ ▼
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ NYC Agent │ │ Dallas Agent │ │ Las Vegas Agent │ │ SF Agent │
│ Shift load to │ │ Absorb transit │ │ Rate-limit CDN │ │ Reroute peering │
│ NJ peer │ │ from cut path │ │ non-critical │ │ via Seattle │
└────────┬────────┘ └────────┬────────┘ └────────┬────────┘ └────────┬────────┘
└────────────────────┴─────────────────────┴────────────────────┘
│
▼
┌────────────────────────┐
│ Reducer + Validation │
│ Merge state, check │
│ invariants, confirm │
│ SLA preserved │
└────────────────────────┘
每个区域智能体是 LangGraph 状态图中一个由 LLM 驱动的节点,在一个 super-step 中并行执行。这是 LangGraph 的并行节点执行机制,它们各自的输出在下一阶段开始前由自定义 reducer 合并。
这不是简单的流水线。这是协调式的并行推理,会引入顺序系统压根不存在的故障模式。
传统测试为什么在这里失效
传统软件里测试四个并行 worker 是可控的。Mock 输入,捕获输出,assert 正确性。Worker 是确定性的同样的输入永远给出同样的输出。
但智能体不是确定性的。
达拉斯智能体可能这次决定吸收 40% 的重路由负载,下次变成 35%。从遥测数据来看都说得通因为都是合理的决策。但差异足以让任何写死精确值的断言直接挂掉。比如硬编码
assert result.load_shift_percent == 40
,下一次模型升级或 prompt 调整就会让它失败。。
更麻烦的情况是四个智能体并行跑、决策互相纠缠的时候。纽约智能体把负载转向某条通道,拉斯维加斯智能体却在同一条通道的过时利用率数据上做决策。如果单独看两个智能体都没做错什么,但放到一起它们制造了一个认为的拥塞。
每个智能体的输出看起来都是对的,但是协调出了问题。
智能体测试要捕获的正是这类故障,不是单个智能体的正确性而是集体行为的完整性。
步骤一:捕获执行轨迹
首先需要的是可观测性。看到的不能只是最终状态,还要包括完整的决策序列——每个并行智能体干了什么,reducer 怎么合并的输出。
LangGraph 的 checkpoint 机制天然提供了这些:
fromlanggraph.checkpoint.sqliteimportSqliteSaver
checkpointer=SqliteSaver.from_conn_string("incidents.db")
graph=fiber_cut_graph.compile(checkpointer=checkpointer)
result=graph.invoke(alarm_event, config={"configurable": {"thread_id": "incident-2024-0312"}})
从存储的历史记录中提取执行轨迹:
START
→ coordinator_analysis [Impact: HIGH | Regions: NYC, DAL, LV, SF]
┌─ nyc_agent [Load shift: 30% → NJ peer | Rate-limit: OTT]
├─ dallas_agent [Transit absorption: 38% | Carrier notified]
├─ lv_agent [CDN rate-limit: applied | MPLS LSPs: held]
└─ sf_agent [BGP MED adjusted | Reroute: Seattle path]
→ reducer_merge [Total redistributed: 102% ⚠]
→ sla_validation [SLA breached: false | Margin: 4%]
END
注意 reducer 中那个
102%
。这种问题只有轨迹捕获才能暴露出来。四个智能体各自基于自己对网络的局部视图做判断,集体的结果是容量过度承诺。没有哪个智能体做错了决定,但系统层面却出了问题。
设计良好的 reducer 难道不能自动阻止这种情况发生吗?
能,但是这恰恰就是重点。在 LangGraph 中自定义 reducer 就是协调约束的载体。通过条件边可以在总承诺负载超过容量时,把执行路由到重新平衡步骤,在任何实际操作执行之前拦截。
但Reducer 不只是个合并函数,它是执行层。
在 LangGraph 的并行执行中reducer 承担的角色相当于分布式事务边界,或者说是唯一一个能在副作用发生之前基于所有智能体的组合意图评估全局不变量的位置。
轨迹测试验证的是这个执行层有没有实际运行,不变量测试验证的是它有没有守住规则。
步骤二:行为不变量
不变量是结构性规则:无论底层跑的是哪个 LLM、选了什么路由、智能体之间怎么分工这些规则都必须成立,因为这些规则是由业务来定义的。
多智能体网络系统不存在一套通用的不变量。金融客户和 CDN 运营商的 SLA 承诺不同;处在维护窗口的区域和正常运行的区域约束也不同。不变量应该反映的是业务上下文不只是技术拓扑。
不过有些不变量是系统级的,对任何并行流量响应系统都值得显式定义。
不变量 1:流量在转移过程中必须守恒。
这是最底层的保障。流量从路径 X 挪到路径 Y 或路径 Z,但进入网络的总流量在重新分配前后必须相等,不能有流量被静默丢弃,也不能被重复计算。
def invariant_traffic_conservation(pre_shift: dict, post_shift: dict) -> bool:
pre_total = sum(pre_shift["path_volumes"].values())
post_total = sum(post_shift["path_volumes"].values())
return abs(pre_total - post_total) <= pre_total * 0.01 # allow 1% drift
这个不变量一旦失败,问题就不只是协调错误了,要么流量被黑洞吞掉了,要么智能体在不一致的状态快照上做决策。
在智能体系统中确定性被有界变异性替代。目标不是冻结输出而是定义变异的结构性边界。
不变量 2:SLA 验证必须在 reducer 合并之后运行,绝不能在之前。
每个区域智能体看到的只是网络的局部。SLA 影响只有在四个决策合并为全局状态之后才能真正评估。在部分状态上跑 SLA 检查,比不跑还糟——它给人一种虚假的安全感。
def invariant_sla_after_merge(trajectory: list[str]) -> bool:
return trajectory.index("sla_validation") > trajectory.index("reducer_merge")
不变量 3:不允许任何区域在没有有效操作集的情况下行动。
如果某个区域智能体返回了空操作,比如所有备选路径都在维护。这时系统不能静默地继续执行,必须升级给人来处理。静默的部分执行是事后复盘里最让人困惑的故障模式。
def invariant_no_silent_partial_execution(merged_state: dict, trajectory: list[str]) -> bool:
for region in ["nyc", "dal", "lv", "sf"]:
if not merged_state[region].get("actions"):
return "escalate_to_human" in trajectory
return True
不变量 4:承诺容量不能超过可用余量。
这条直接验证 reducer 的条件边逻辑。如果各区域转移量之和超过骨干网可用容量,系统必须走重新平衡流程而不是执行已经超限的方案。
def invariant_no_capacity_overcommit(merged_state: dict) -> bool:
total_shifted = sum(merged_state[r]["load_shift_percent"] for r in ["nyc", "dal", "lv", "sf"])
return total_shifted <= merged_state["backbone_available_capacity_percent"]
每次执行后把四个不变量全跑一遍,就是在对整个协调层做行为健康检查,而不是只看某个智能体的输出。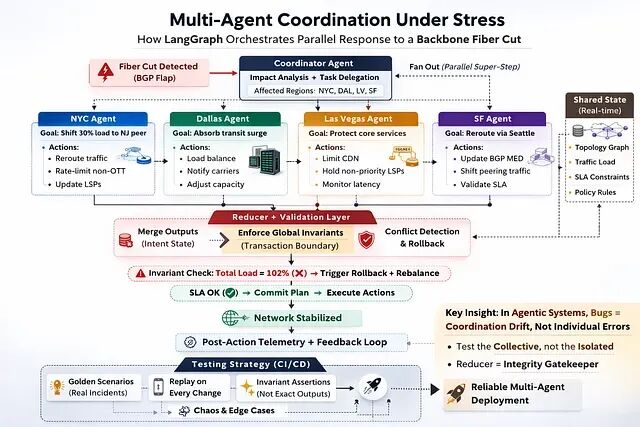
步骤三:基于回放的回归测试
上线半年后团队升级到了新版 LLM。单个智能体的决策质量确实提升了,但并行执行时旧金山智能体变得更激进了,比如在负载转移上承诺到更高的比例,把总利用率推过了 reducer 调优时设定的余量阈值。不变量本可以抓住这个问题,但如果升级完没人跑回放测试,它就带着隐患上了线。
LangGraph 的 checkpoint 机制让每个真实事件都成了回归测试资产。把原始输入在更新后的图上重新跑一遍,提取新轨迹然后验证所有不变量是否依然成立。
更聪明的模型可能用更短的路径达到同样的结果。但在并行协调系统中无法解释的漂移必须经过人工审查,特别是 reducer 和 SLA 验证步骤前后的变化。
回放测试的价值不只是抓住已知的故障更是建立一种信心:模型和 prompt 的变化不会在所有输出级测试的盲区之外悄悄改变系统的集体行为。
步骤四:来自真实事件的黄金数据集
真实事件里藏着你编都编不出来的边界情况:维护窗口和光纤切断同时发生了、BGP 重收敛在执行中途发生、遥测数据对一个区域返回过时结果而其他区域正常。
系统处理过的每一个真实事件都是黄金数据集的候选,这里有一个核心设计原则:不要记录每个智能体说了什么,要记录哪些属性必须成立。
黄金数据集的一条记录包含原始输入(真实遥测快照、拓扑状态、当时的策略约束)和预期行为属性:哪些不变量必须成立、哪些轨迹节点必须出现、哪些不能出现。不记录精确输出值,不记录具体路径名。
这样做的好处是数据集不会随着系统演进而过时。模型换了、prompt 改了、图逻辑重构了,数据集验证的依然是真正重要的东西不会在合理变化的部分误报。
步骤五:CI/CD 集成
智能体测试不自动化就没有意义,每次 prompt 变更、工具 schema 更新、或者切换模型版本,流水线都应该回放黄金数据集,并且在任何变更上线之前完成不变量验证。
不变量违规是硬性失败流水线直接挂掉。轨迹漂移标记出来交给人审查但不自动阻断,可接受的行为变化和真正的回归之间的判断,应该由人来做而不是流水线。
阈值问题值得提前想清楚:不是所有轨迹变化都是回归,有时更智能的模型会走一条更高效的路径。在凌晨 2:47 做部署回滚的时候再去定义什么叫"有意义的漂移"就太晚了。
换个角度想:升级路由协议之前你不会不跑回归测试,升级多智能体协调图里的 LLM 也不应例外。
步骤六:协调测试——并行系统真正出事的地方
多智能体系统里最难缠的故障不在任何单个智能体内部。它们存在于智能体之间的缝隙——并行系统比顺序系统有多得多的这种缝隙。
三种故障模式反复出现:
┌─────────────────────────────────────────────────────────────┐
│ Pattern 1: Capacity Overcommit │
│ │
│ Each agent independently prefers the eastern backbone. │
│ Reducer sums all four shifts → 105% utilization. │
│ No single agent was wrong. The coordination was. │
└─────────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────────┐
│ Pattern 2: Stale State in Parallel Branches │
│ │
│ NYC Agent reads backbone_utilization = 72% │
│ DAL Agent reads backbone_utilization = 68% (4s stale) │
│ Both make shift decisions on different views of reality. │
│ Reducer aggregates inconsistent data as if it were valid. │
└─────────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────────┐
│ Pattern 3: Reducer State Overwrite │
│ │
│ Multiple agents write to a shared metric field. │
│ Last writer wins → earlier, higher-accuracy data lost. │
│ Downstream agents make decisions on corrupted state. │
└─────────────────────────────────────────────────────────────┘
针对每种模式,要写专门的协调测试:注入问题状态,运行图,断言 reducer 和条件边正确处理了冲突。测试的不是智能体聪不聪明,而是协调层能不能在智能体产出合理但相互冲突的结果时依然执行结构性规则。
这是大多数团队在智能体测试中跳过的部分,也恰恰是造成生产事故最多的部分。
总结
至此已经搭建起了一套完整的基线:轨迹捕获、行为不变量、回放回归测试、黄金数据集、CI/CD 集成、协调测试。对于一个并行管理四座城市流量的系统来说,这是把它放到生产环境之前必须具备的测试纪律。
但这个框架还有几个没有覆盖的问题,值得明确指出。
系统对每个决策有多大信心?达拉斯智能体选了 38% 的负载吸收率,这是基于清晰遥测数据的高置信度判断,还是不确定条件下的最优猜测?如果能在决策粒度上引入置信度评分,就可以校准每一步需要多大程度的人工介入。这个在智能体操作实时骨干网流量的场景下,这一点非常关键。
混沌环境下会发生什么?遥测 API 返回过时数据,拓扑数据库落后 90 秒,某个区域智能体的工具调用在执行中途超时而其他三个正常推进。当前的测试假设环境全程配合但是生产中不会,针对智能体系统的混沌测试目前还没有成熟的标准化工具,所以只能手动进行。
传统软件里bug 是逻辑错误。代码做了不该做的事;并行智能体系统里的 bug 往往以另一种形态出现:协调漂移。
四个智能体各自推理正确,各自的决策在隔离环境下都站得住脚,但组合在一起违反了一个系统级不变量。系统平稳运行了半年某次模型升级让某个智能体的决策偏了那么一点,刚好够造成 reducer 没有拦住的容量过度承诺。
该问的问题不是"系统有没有产出正确的输出",而是"系统有没有通过正确的协调达到这个输出,而且在模型和 prompt 持续演进的过程中,它能不能一直做到"。这是两个完全不同的问题,需要完全不同的工具。
作者:ravikiran veldanda