
人们喜欢长上下文,智能体记得你的项目、你的偏好、你说话的方式,连你那些反复冒出来的琐碎任务都帮你记着,所以用起来当然顺手。但顺手归顺手,顺手不等于靠谱,把这两件事搞混后面的麻烦就来了。
可靠性问题的起点恰恰是人们把长上下文当免费能力用的那一刻。你扩展了上下文就等于换了一个被测系统,测的不再是模型本身,而是模型加上一个持续膨胀的历史 Token 档案。这个档案天生就很杂乱:半成型的想法、开玩笑时随口说的话、情绪化的措辞、前后矛盾的约束、从未打算变成策略的临时指令,统统堆在一起。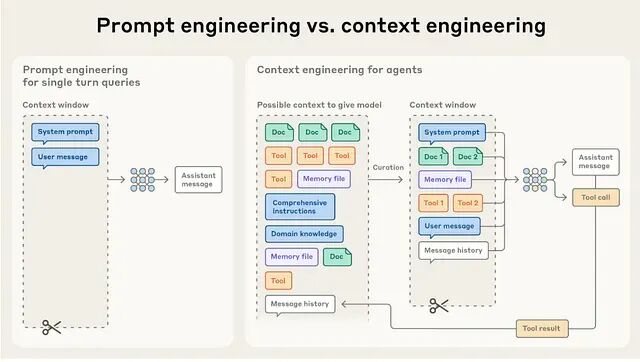
模型只能在它能关注到的范围内做推理,而注意力即便在窗口很大的情况下依然是稀缺资源。输入杂乱、矛盾、臃肿,模型的最优表现就不稳定压力一来更没法预测。很多人喜欢把长上下文比作"更大的大脑",但实际上它更像一张越来越大的办公桌:纸越堆越多最后你连自己要找的那份文件都找不到。
个性化是一种交换,因为可重复性很重要。
团队倾向于把个性化当作一次无争议的升级:见效快问题肉眼可见地减少。但实际操作中个性化是拿可重复性换舒适感,每个用户都有独特的上下文历史,意味着每个用户跑的实际上是一套不同的系统。
可重复性是时间压力下调试故障的前提,也是证明修复真正生效(而不是"感觉好了")的唯一手段。客户说"昨天还好好的,今天就坏了",团队拿同样的 prompt 试在自己的账户上完全复现不了,缺的那个变量往往是客户积累了好几周的上下文,这些交互以团队根本无法重建的方式,并且静悄悄地改变了模型的行为。
可测试性就这样成了长上下文的隐性牺牲品。实验室里通过的干净评估 prompt 放到线上就可能挂掉,因为线上的系统早已不是实验室里那个了:模型被更早的对话预热过,被推向了另一种语气,身上背着只属于那个用户的隐性约束。
个性化制造了一整支雪花舰队。雪花在规模化运营中极难管理,你完全可以交付一个使用体验极其顺滑的产品,同时交付的也是一个脆弱无比的系统。单次对话的流畅会遮蔽跨对话的不稳定。等到第一次严重故障真正来了,团队才意识到,复现不了也测不干净,发修复补丁又怕打破别人的个性化行为。
共享账户混合了意图,智能体失去了连贯性。
共享订阅看起来只是个小的使用习惯问题,但它制造的技术麻烦远比人们以为的要大,只是大家在真出事之前懒得细想。多个人共用一个账户或一条长线程,智能体看到的是一股混杂了不同目标、风格和约束的信息流。这些东西本来就不该共存,模型被迫在多种意图之间做插值(interpolation)而插值不是推理。
最能暴露问题的场景往往也最荒诞,比如某天你问了个基础问题,智能体的回答口吻突然像在跟一个数学家或资深工程师对话,你一头雾水,它怎么忽然高估了你?这不是什么灵异事件,只是别人的上下文残留渗进了当前会话,模型在模式匹配它"以为"正在交谈的那个用户。
这就引出了一种运行时才暴露的"我是谁"故障模式:智能体的应答对象不是当前打字的人,而是一个多用户融合出来的虚构画像。用户的感受是语气漂移、目标混乱、对专业水平的离谱假设、偏好前后矛盾:看起来像智能体的"人格"在闪烁。安全层面上共享上下文还带来额外风险:任何被摄入的恶意引导文本都能在更长的窗口中存活更久,而持久性恰好是日后引入工具调用时,把一段无害文本转化为延时炸弹的关键因素。
向量平均化会失败,因为人类目标是有方向性的。
人们习惯性地假设智能体可以把一组偏好平均成某种连贯稳定的东西。在风格层面模型确实擅长混合出听起来合理的折中方案。但一旦从风格混合切换到目标对齐,这个假设就不成立了。人类目标不只是偏好,它们是带着硬约束的方向性承诺。目标之间经常彼此对立有时候在设计上就是互斥的:一个人要激进增长,另一个人要风险最小化加法律合规。
智能体面对不兼容的目标时,很典型的行为是输出一份语言极其自信的模糊计划。自信的措辞容易让人误以为连贯性存在,输出听上去四平八稳实际上违反了真正关键的约束条件。因为模型并不是在跟你显式地协商取舍,它只是在互相矛盾的指令模式间静默插值。人类可以把冲突摆上台面然后做决策,模型则倾向于用一个谁也没要求的"看似合理的折中"来填补空缺。
那些被称为"涌现性怪异行为"的东西就是在这里出现的,它不神秘只是系统运作方式的可预见后果。智能体可能会锁定某个用户反复提到的主题,然后把它套用到共享上下文里的所有人身上,因为重复 Token 被当成了稳定意图的信号。它也可能去优化一些代理目标,比如"最大化礼貌度"、"最小化冲突"或者"给出中位数推荐",因为它没有能力调和线程深处那些真正的目标函数。
性能问题是真实存在的,上下文饱和使情况更糟。
一个很多开发者吃过亏才学到的问题:把当前代际的模型往上下文窗口深处推,往往让它在你真正关心的任务上变差。退化的表现形式包括推理变弱、遗漏增多、对干扰信号的抵抗力下降,以及用户口中那种模型"累了"的整体迟钝感。窗口技术上能撑那么长,不代表质量在窗口内是均匀分布的。
注意力是有限资源。上下文膨胀,模型就得把注意力摊到更大的 Token 预算上。塞进去一整部之前聊天的"小说",它可能恰好漏掉今天最关键的那段话——但它照样会自信满满地给你一个答案,因为生成回答本身就是训练目标。由此产生的失败模式非常隐蔽:智能体不会轰轰烈烈地报错,它只是悄悄地出错。而悄无声息的错,才是真正搞垮生产系统的。
长上下文在检索工作流中也能放大幻觉——哪怕检索到的文档本身是对的。RAG 管道可能拿到了正确的来源,但环绕的对话上下文把相关证据淹没了,模型最终从记忆中"声量最大"的模式而非 grounded text 里取材来拼答案。还有一种情况叫约束遗忘:一条合规规则在对话早期被明确声明过,却被后续大量闲聊掩埋,智能体的行为就好像那条规则不存在一样——它在那个时刻就是没能可靠地 attend 到它。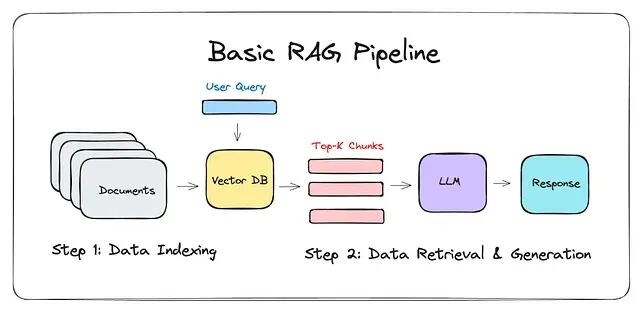
很多团队的直觉反应是往窗口里塞更多上下文,觉得记忆多了就能修复漂移。这条路通常走不通。塞得越多,噪声越大,信噪比越低,检索的选择性越差。到了某个临界点,更大的上下文反而意味着更差的记忆,因为模型已经无法可靠地定位到什么才是重要的。你的系统变得更难测试、更难调试、更难被信任。
将长上下文视为生产依赖项
要在生产环境中用长上下文,第一天就得建立明确的上下文预算。预算逼你做决定:什么是持久的,什么可以丢弃,什么该被摘要压缩,什么该以结构化记忆而非原始文本的形式留存。没有预算,上下文只会无限膨胀直到变成负债,唯一的退路是一次痛苦的重置——用户会抗拒,因为他们早已对"连续性"产生了情感依赖。
会话隔离是智能体系统的基本问题。私人闲聊不该渗进工作流,工作流不该渗进财务流程。用户非要开一个巨型线程的话,系统也必须在线程内部强制角色边界,因为角色边界是意图清晰性的保障。读取权限和执行权限也必须分离——读取本身就有风险,执行则把风险兑现成了实际损害。最小权限原则在这里不再是理论说教,而是工程必需。
记忆层要像对待数据库 schema 一样去管理。记忆本质上是一个塑造未来行为的状态存储,必须定义哪些字段存在、谁有写入权限、什么内容该被提升到长期存储——因为长期记忆里的一切都会成为系统策略面的一部分。上下文长度应当作为窗口容量的百分比来监控,设好阈值触发自动摘要或裁剪,摘要策略或记忆管理逻辑每次变更都要跑回归测试。
重置机制同样不可或缺。给用户设计一条能接受的重置路径,提供可审计的精选摘要,让用户理解清空上下文不是在抹掉历史,而是在保留真正经过验证的稳定信息。从工程角度看,清空是一种主动的状态管理手段,和数据库的定期归档、日志的轮转没有本质区别。长上下文本质上是一个输入面——它会老化、会漂移、会积累噪声。不做治理,它就会从资产退化为负债。
by Travis Good